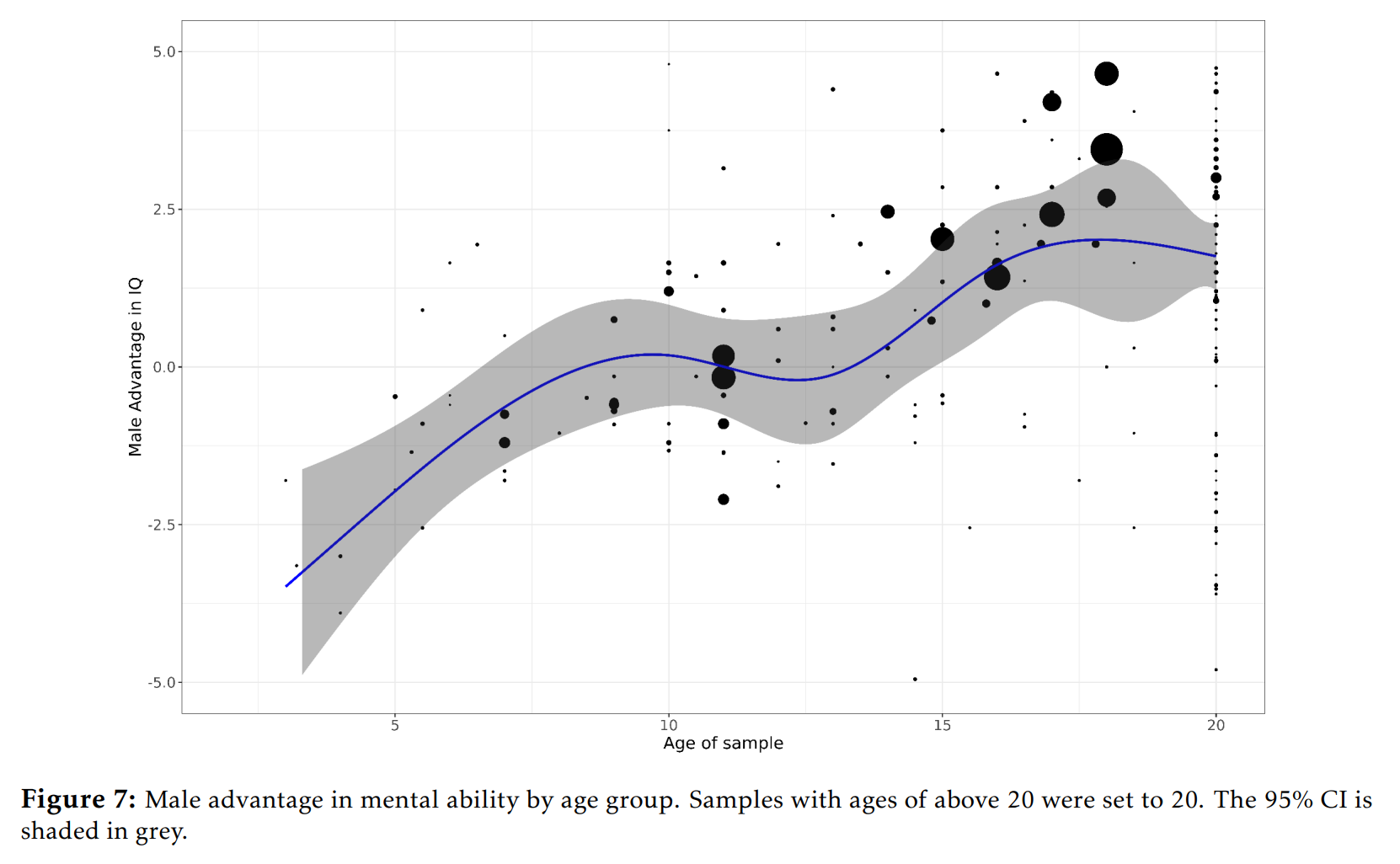
Newest results on the sex difference in intelligence
Richard Lynn noted a 'paradox' or incongruency many years ago (1994): A paradox concerning sex differences in intelligence and brain size has recently been noted by Ankney (1992) and Rushton…
Richard Lynn noted a 'paradox' or incongruency many years ago (1994): A paradox concerning sex differences in intelligence and brain size has recently been noted by Ankney (1992) and Rushton…
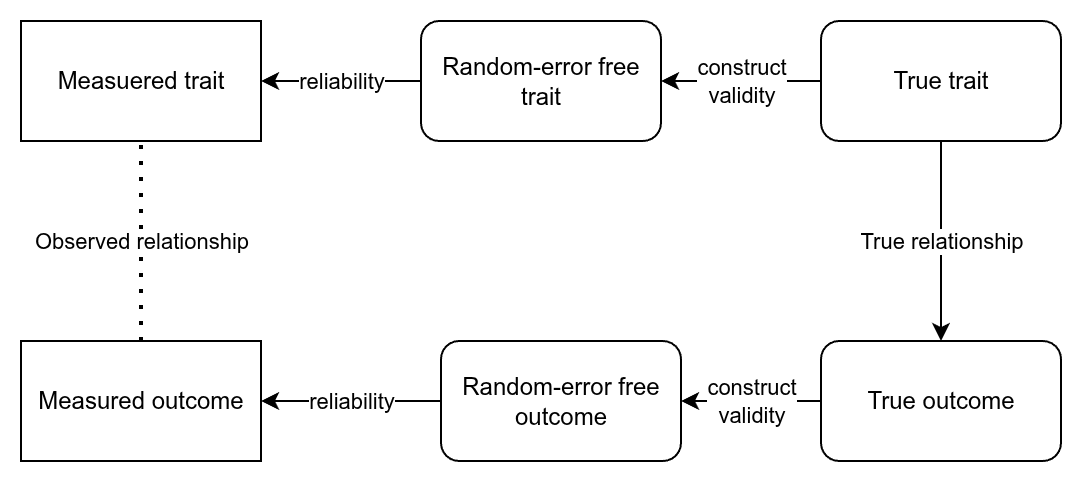
You will often find intelligence researchers and enjoyers make claims like the following: g can be said to be the mostpowerful single predictor of overall job performance. First, no other…
It's time for the sort of annual reader survey. Click here to participate. It should take 10-15 minutes. Prior years survey results: 2024 results (I apparently forgot in 2023) 2022…

There's a lot of variation across the globe in average height. It looks like this (per OWID): Furthermore, there has been a significant increase in the last century: We also…

I think most people are unfamiliar with how the scientific publication and prestige system works. It works like this: Scientists submit papers to journals for publication. This means they start…
Glædelig jul og godt nytår. 🎄🎊 Following my prior post on how to use LibGen (Library Genesis) and Scihub, here's a new post on the most recent tool in the…

I thought this was general knowledge by now, but I still see quite a bit Substacks that are still suffering from this dumb Elon suppression move. Here's the problem: Such…
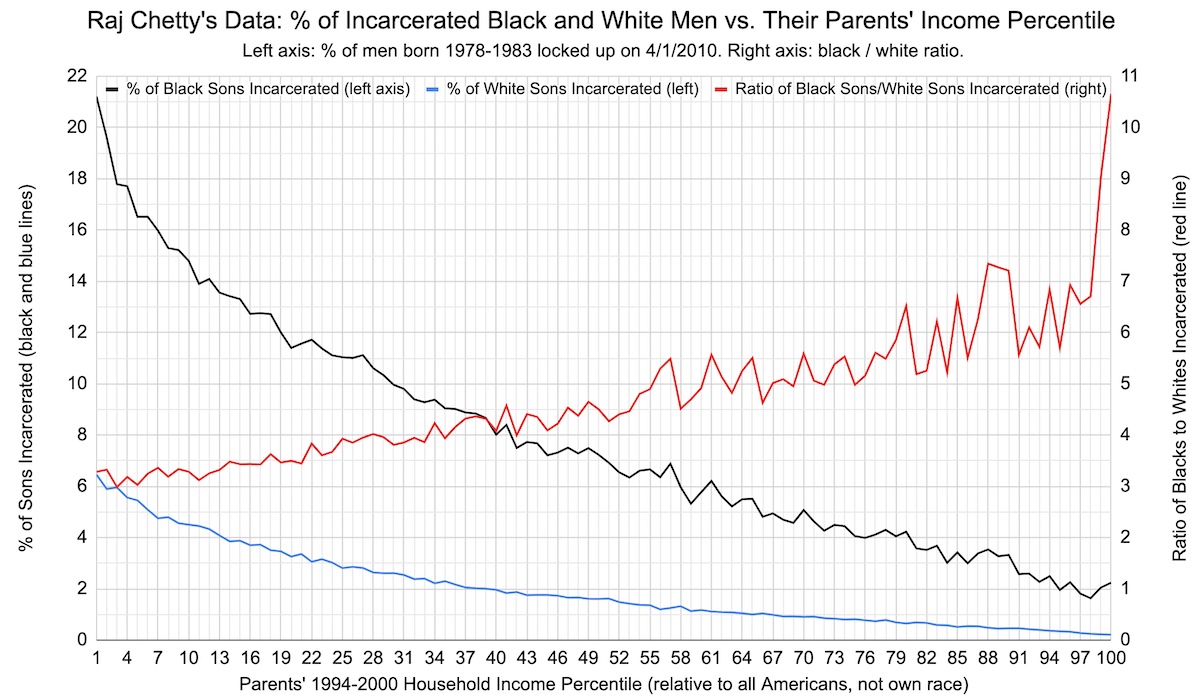
Steve Sailer tells the story of this figure: Why Is the Ratio of Black Incarceration to White Incarceration Worse in Higher Social Classes? He muses: Why does the black-to-white ratio…
Metaculus: Will Marine Le Pen win the 2022 French presidential election? Will Emmanuel Macron be re-elected as President of France in the 2022 Presidential Election? So let's try! Let's time…
So you've probably seen the midwit meme about COVID vaccine skepticism: The data given to back this one up is this survey: Now you might be tempted to question some…