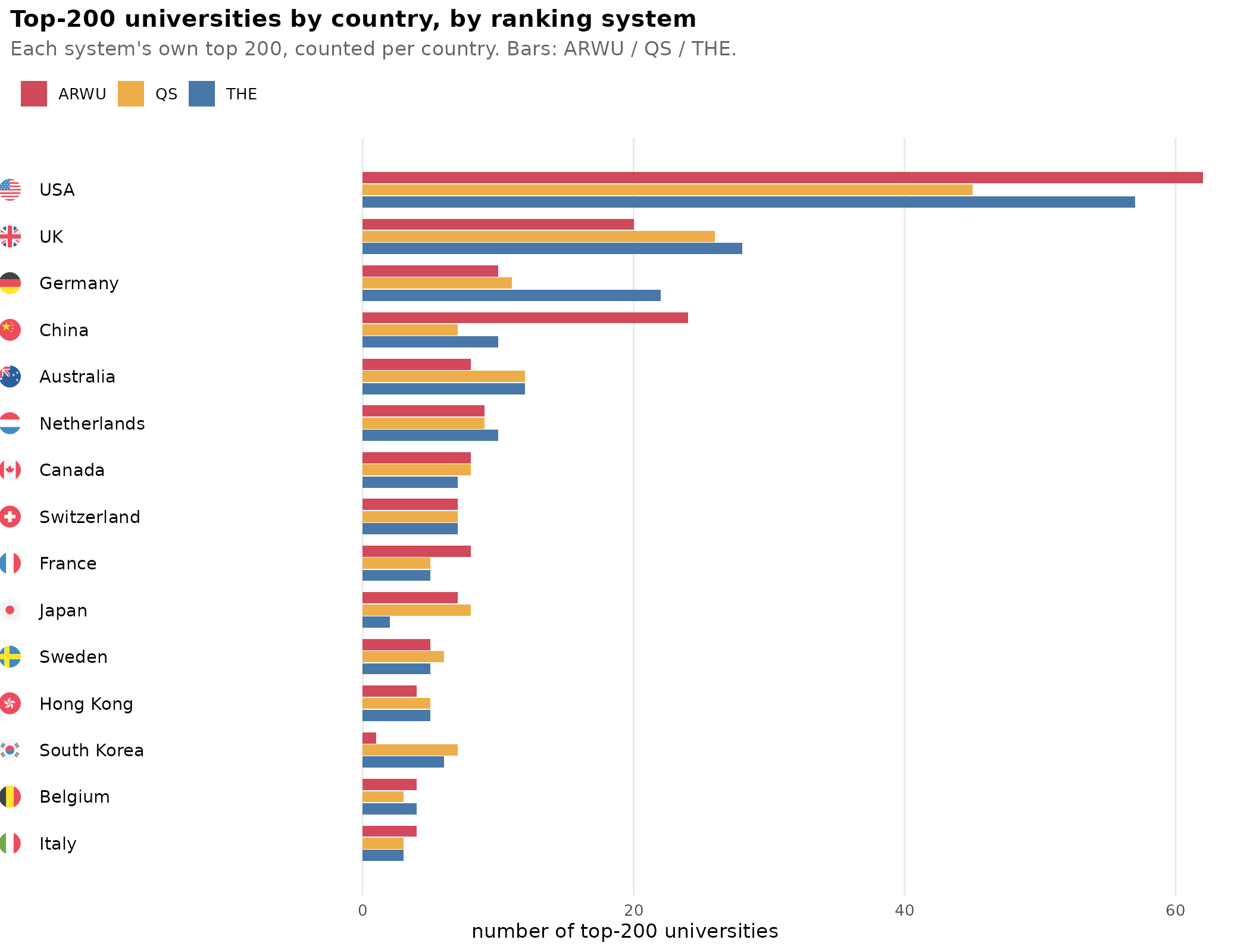
Top universities and national intelligence
We all know that universities differ in quality. But what exactly do we mean by that? How do we determine which are the top universities? There are a number of…
We all know that universities differ in quality. But what exactly do we mean by that? How do we determine which are the top universities? There are a number of…
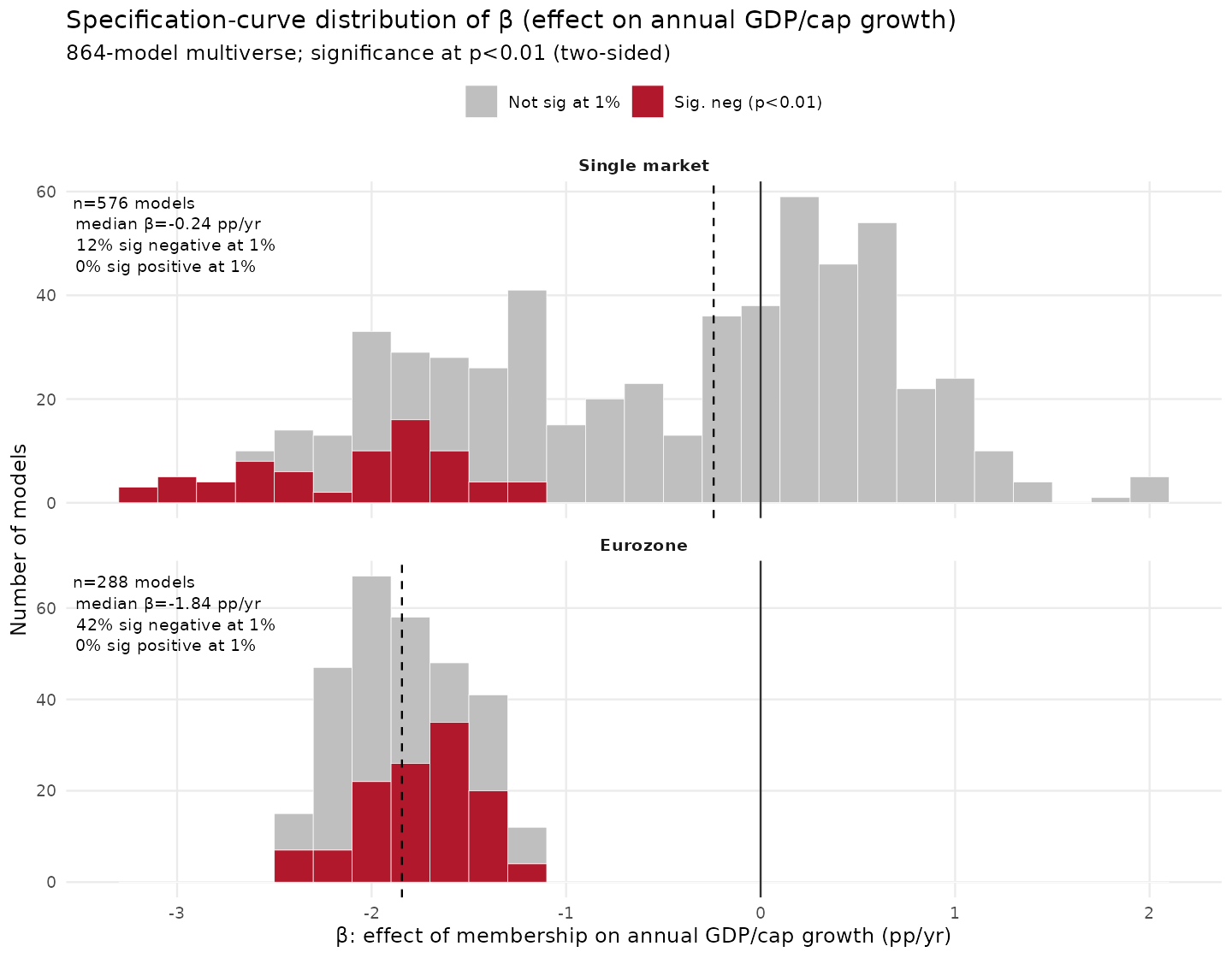
Since I can remember I've been told that prominent economists say that the European Single Market (tariff free zone) is good for business and the economy at large. And the…
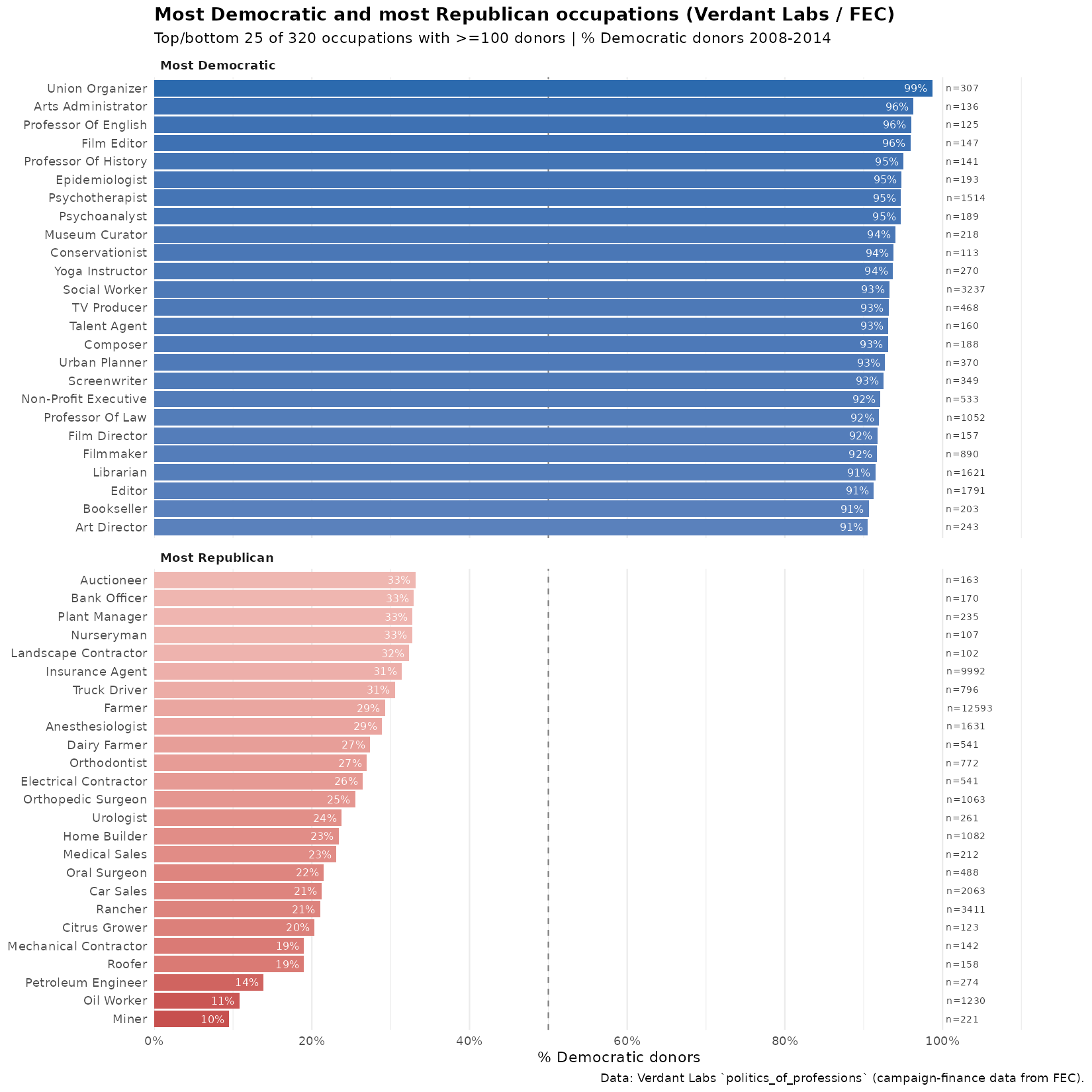
In response to my prior post on the fertility rates of American women by occupation, some asked for the results for men, and others pointed out that there seems to…
In a world of declining fertility, we have to ask ourselves why it is so declining. I've spent many posts on that question. We could also ask instead, how do…
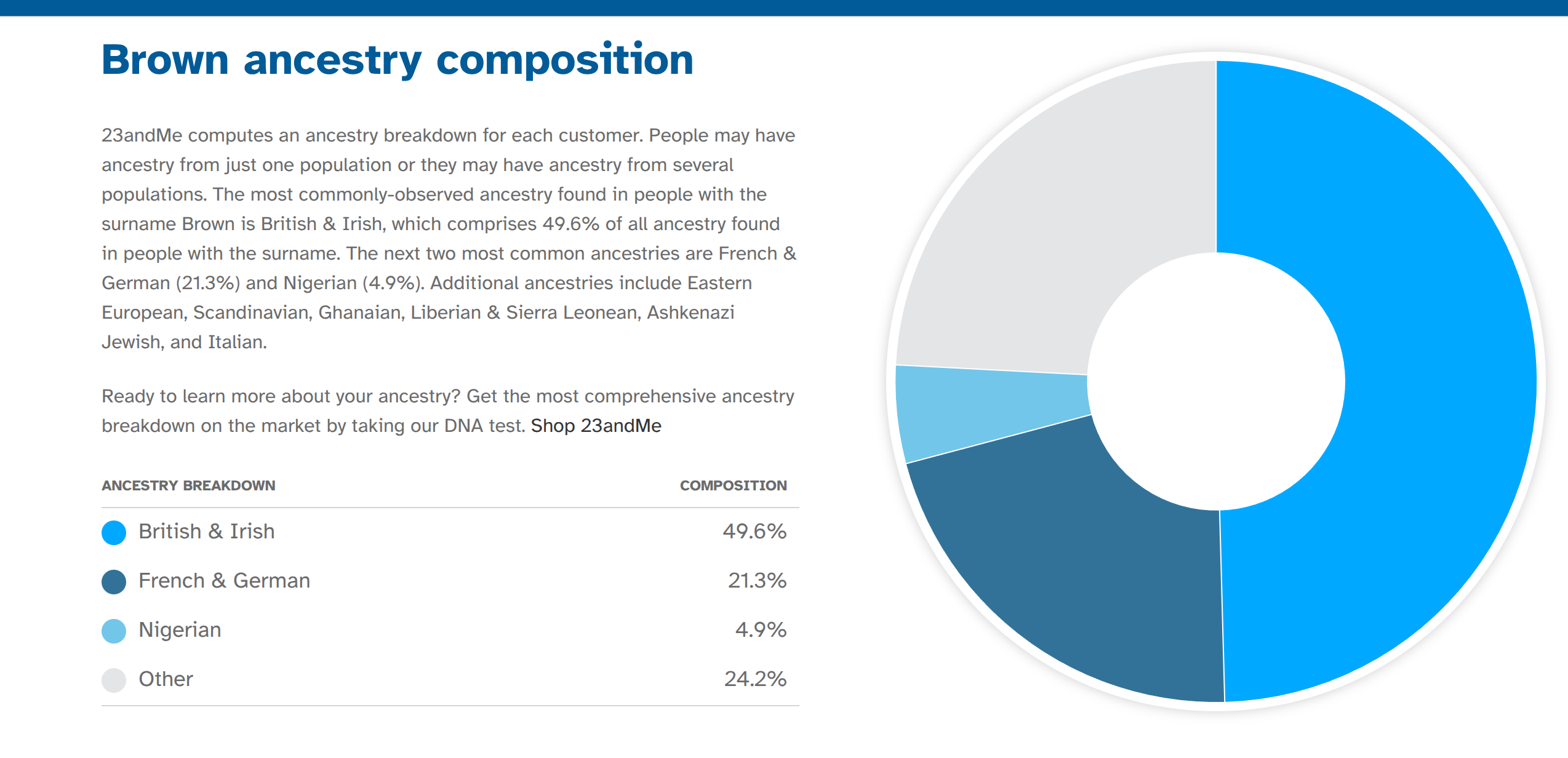
Our big project was finally published: Van Pelt, D., & Kirkegaard, E. O. (2026). Big Data, Deep Roots: Correlating Surname Genetic Ancestry and Socioeconomic Status across Millions of Americans. Comparative…
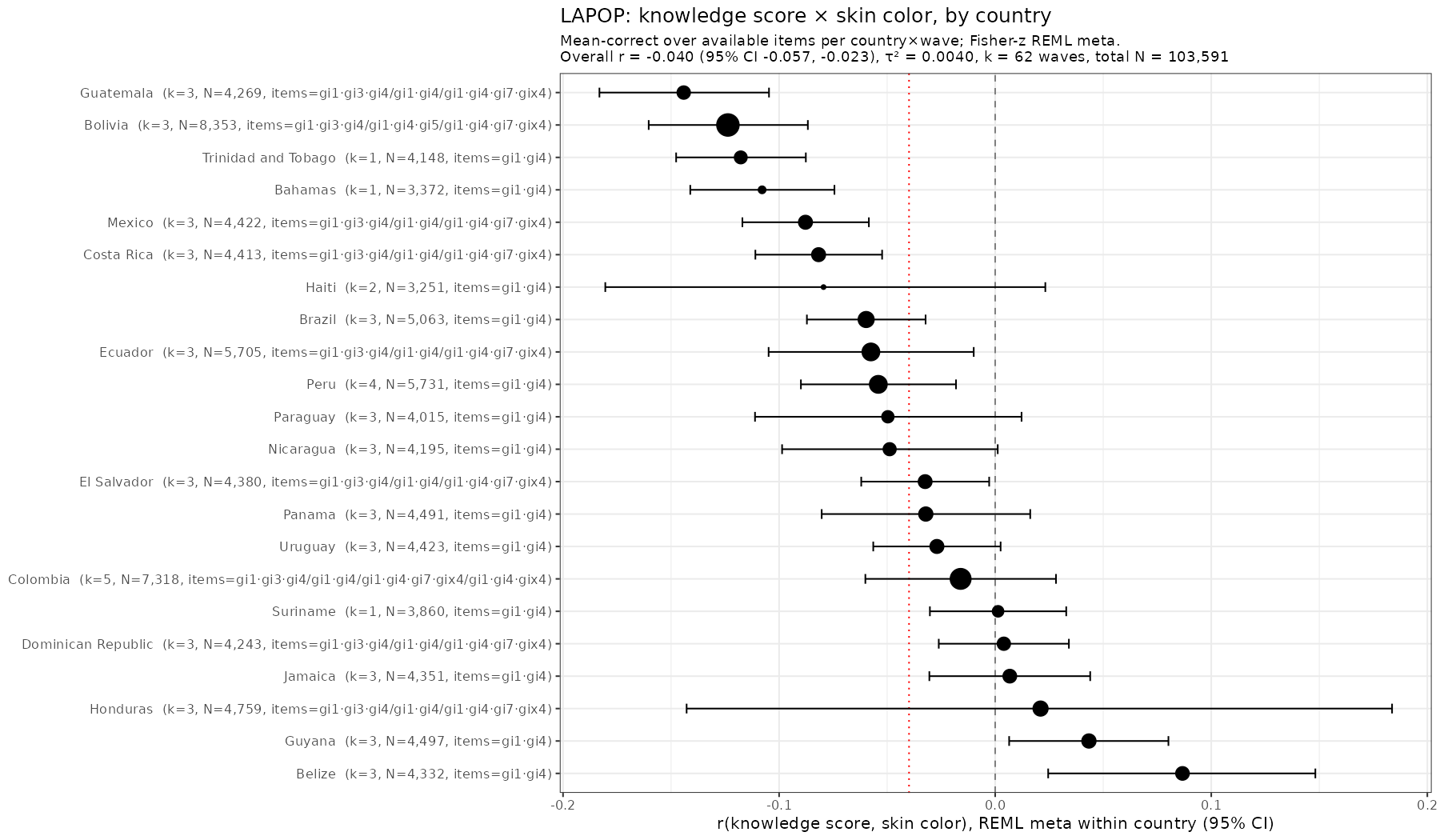
Skin color (lightness or brightness) has been used as a proxy for genetic ancestry for over 100 years. It works alright in many cases. Take this study (Parra et al…

Many years ago I discovered that Brazil publishes the subject level data for many scale testing efforts. These also come with rich surveys concerning the children's homes. The main tests…
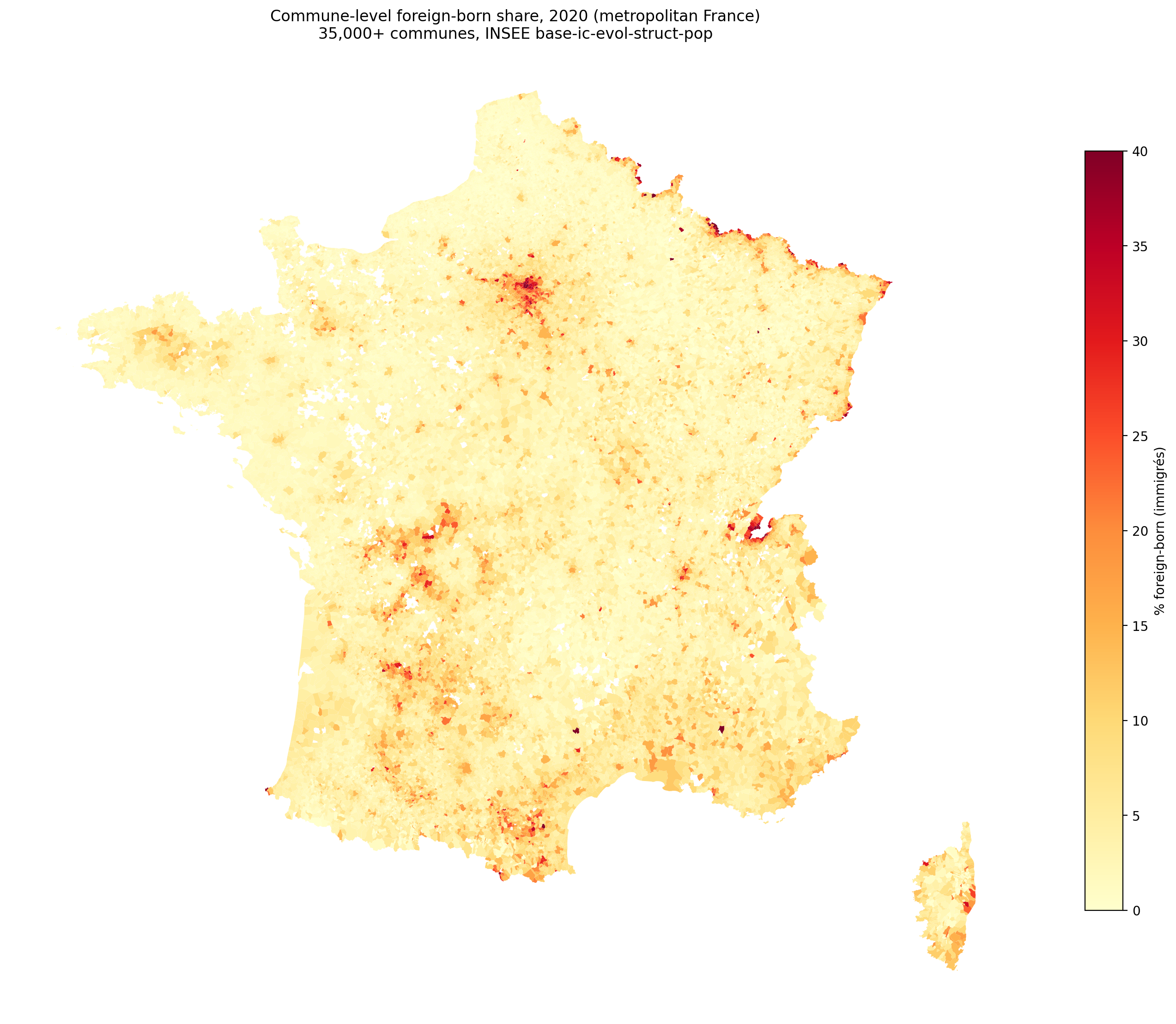
France is the 4th most populous country in Europe these days (it used to be number 1 before it had early secularization). It is also quite insular when it comes…
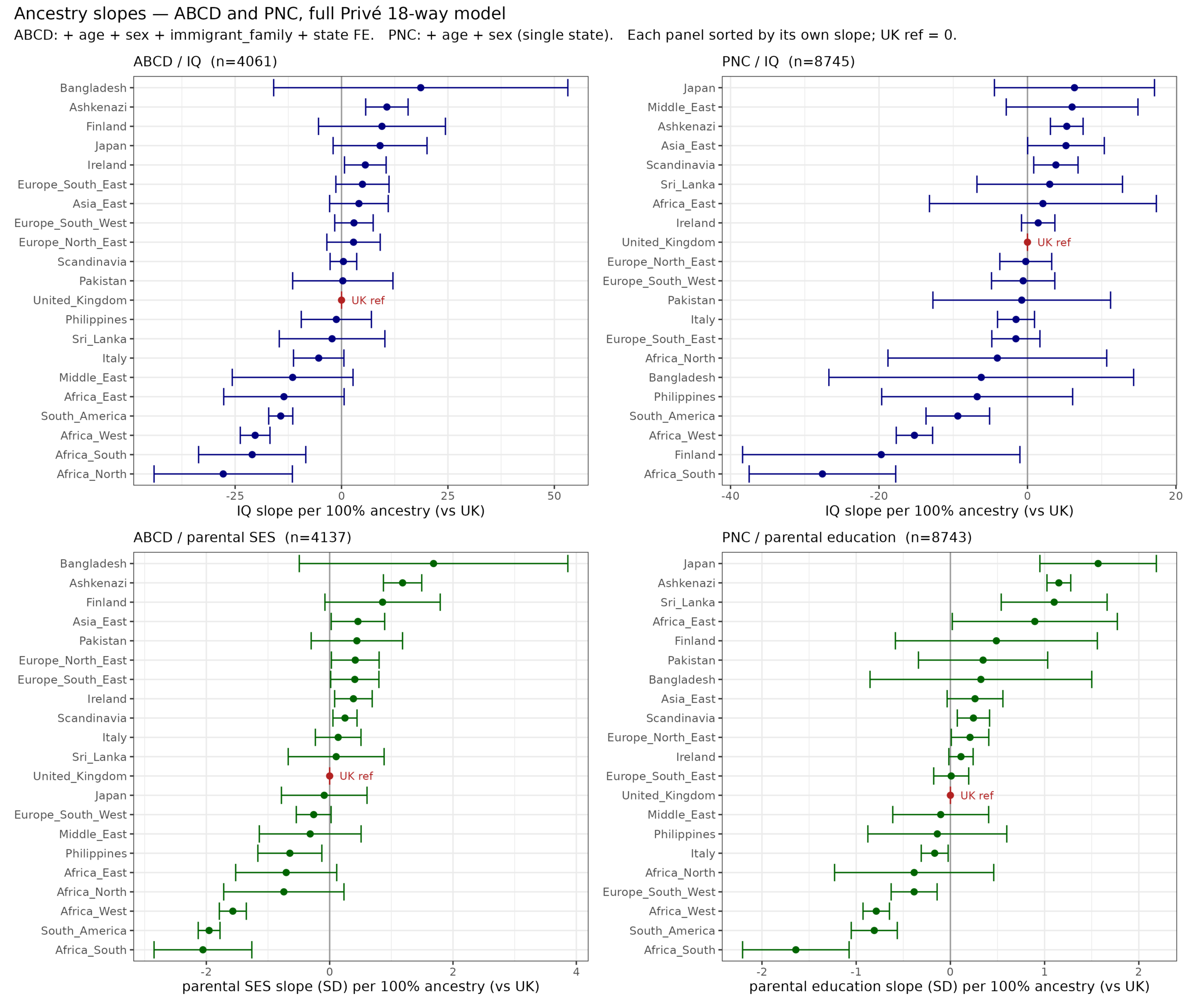
There are long standing questions about the source of Jewish achievement. Most of this achievement relates to the Ashkenazi subgroup, less so the other Jews. This tells us that the…
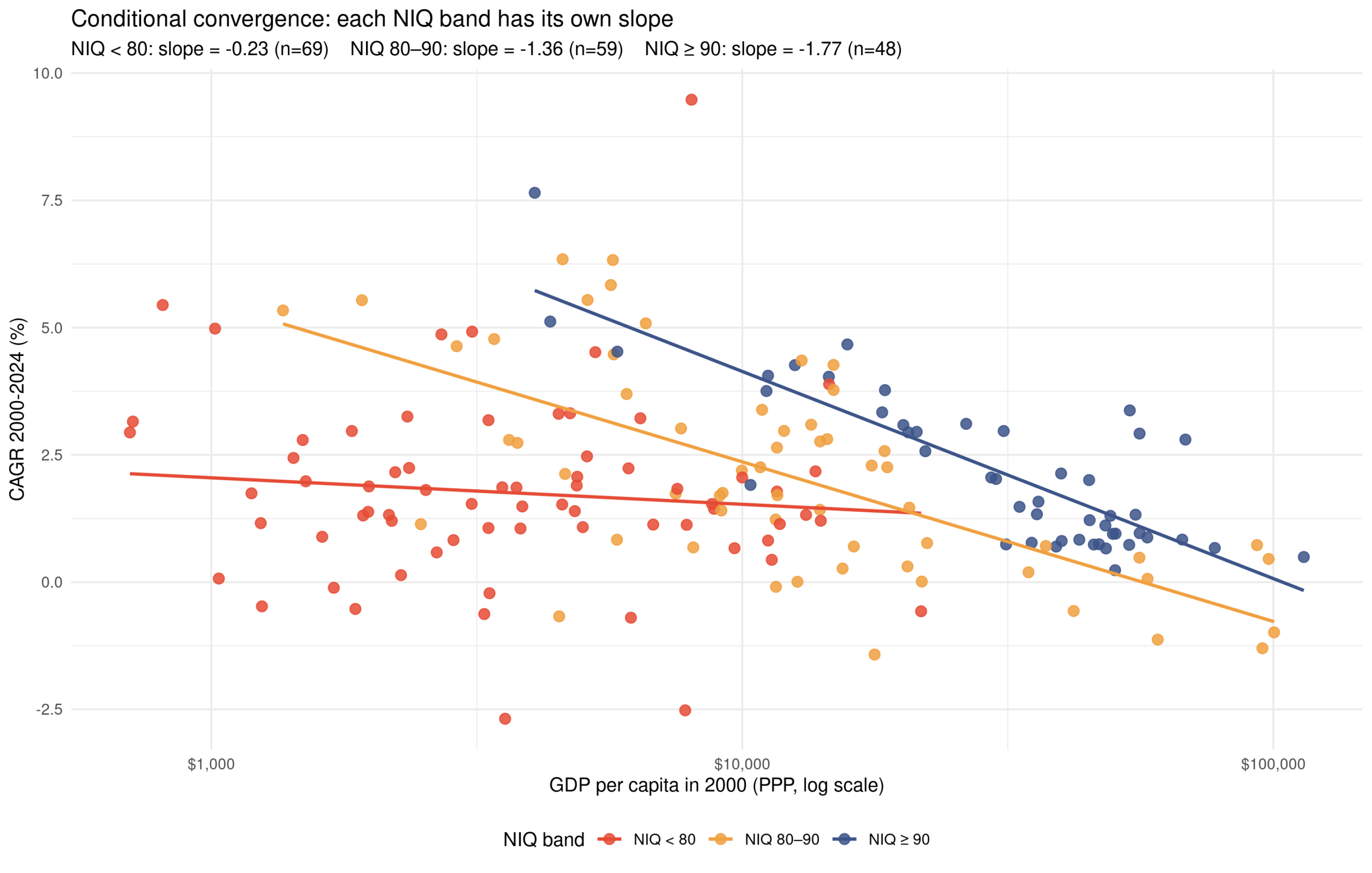
Some days ago I posted some cumulative growth charts for OECD countries, like this one: These results are somewhat affected by the usual GDP issues relating to tax haven (Ireland…