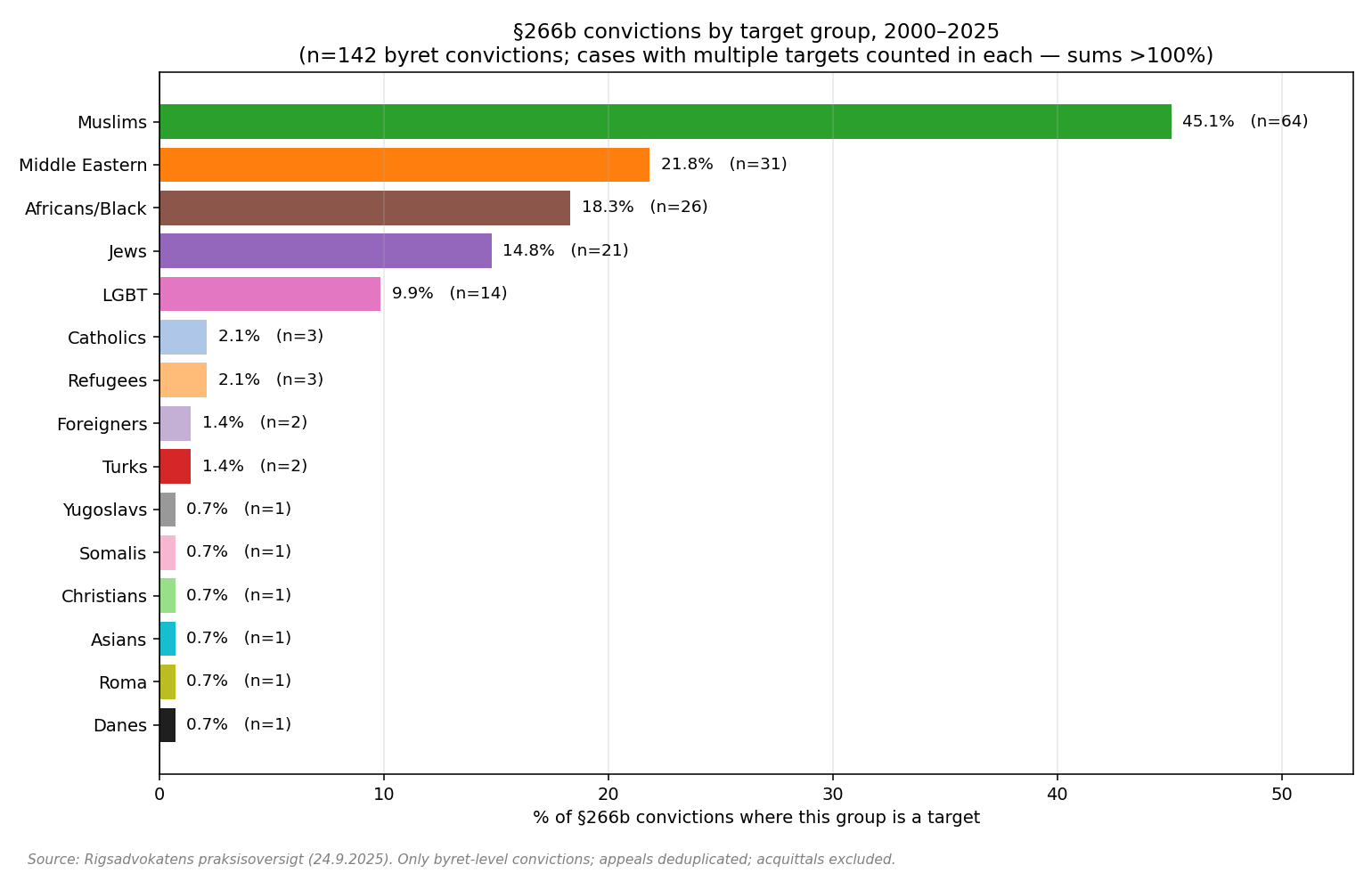
Free speech for thee but not for me
Most countries have severe limitations on free speech. Historically, freer speech was a characteristic of western countries, but not so much anymore, with the exception of the United States. And…
Most countries have severe limitations on free speech. Historically, freer speech was a characteristic of western countries, but not so much anymore, with the exception of the United States. And…

I decided to review all books I read, which also serves as a motivator for making notes when reading (actually, I only highlight text and memory is usually enough reconstruct…
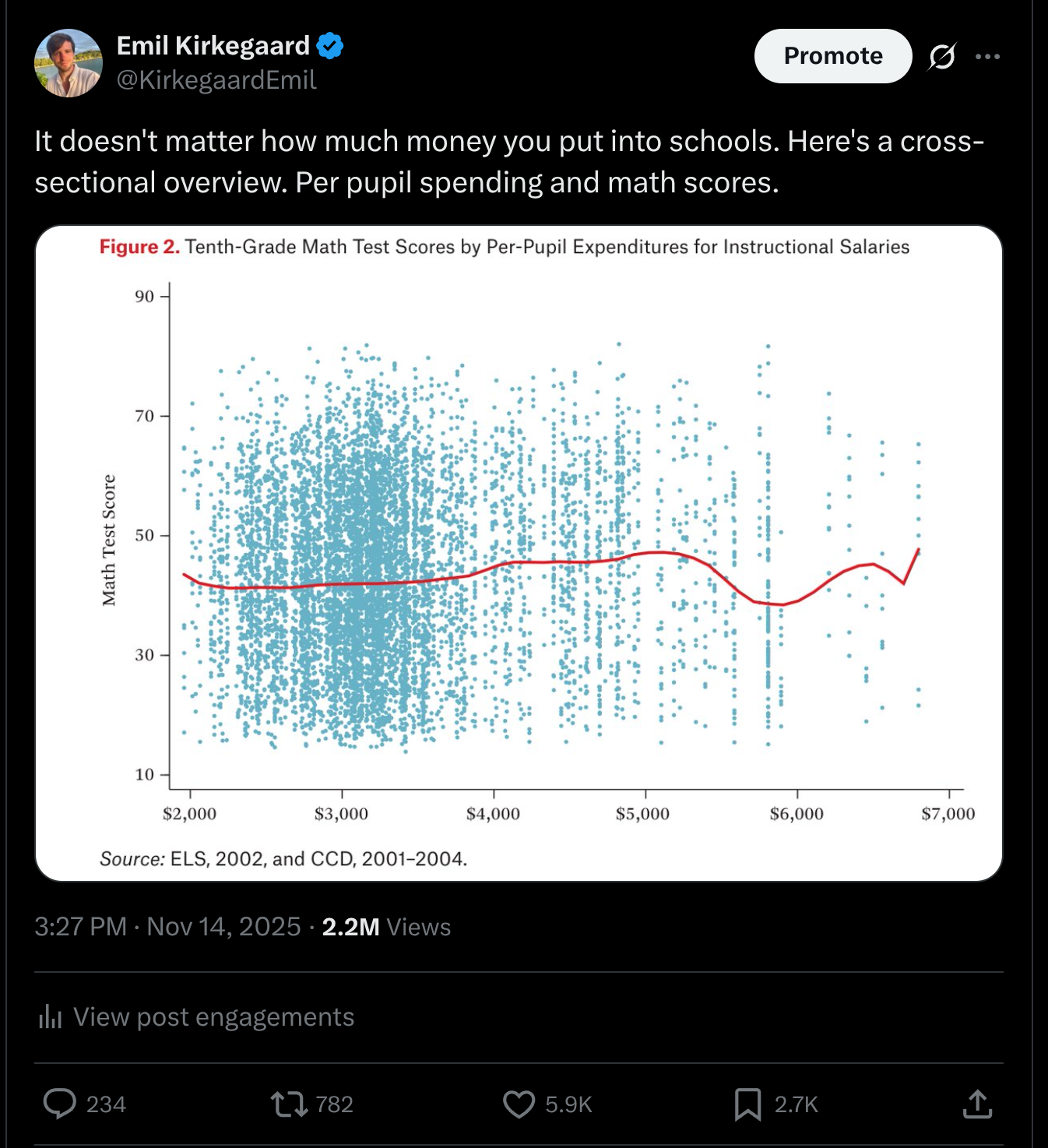
Some days ago I posted a chart about school spending (per-pupil spending) and math test scores: Note how I didn't say this cross-sectional scatterplot proves anything about causality, but we…

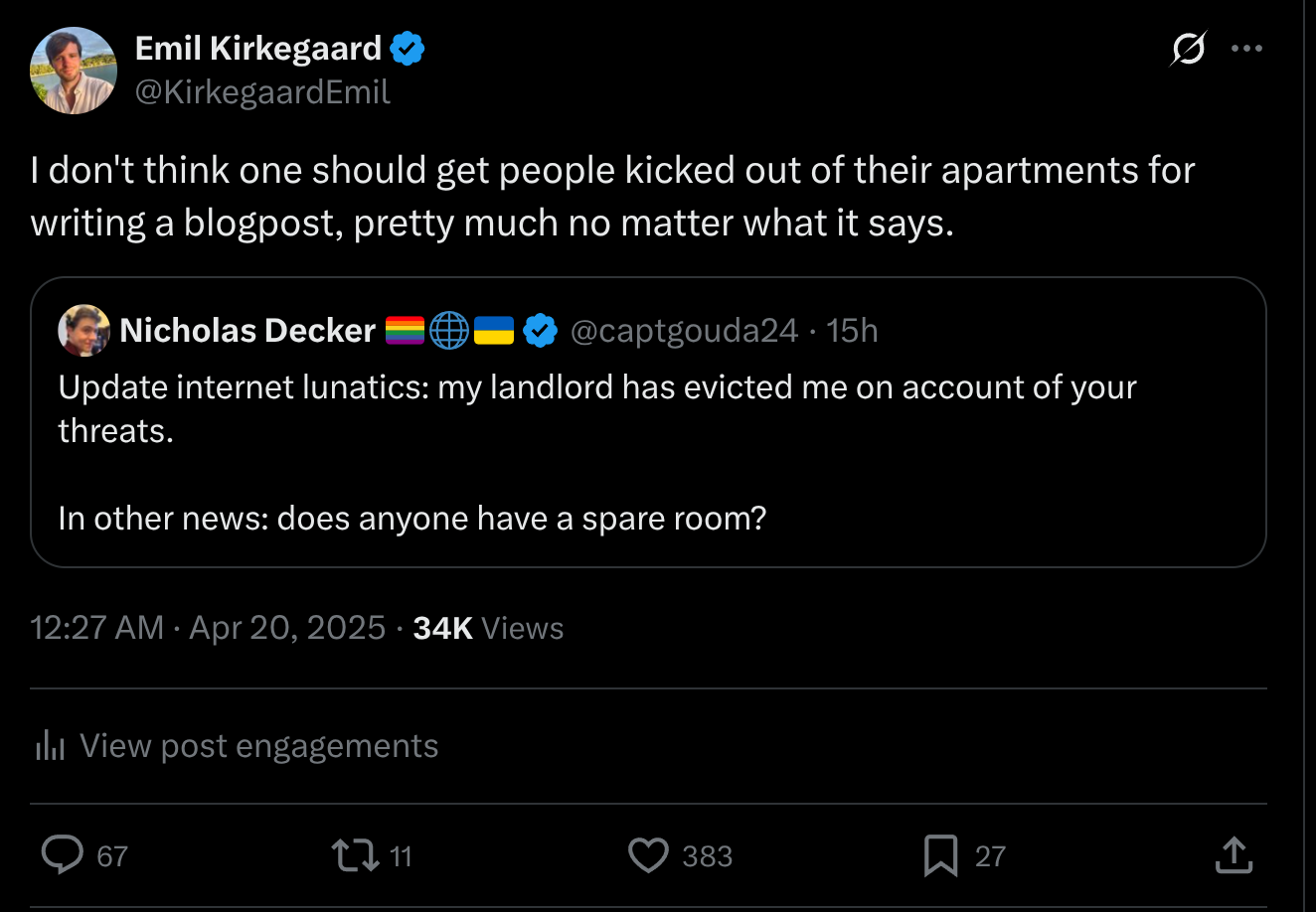
Most people know that if you at some point say something the left doesn't like, your life may became hell. You may get stalked, assaulted, and occasionally killed and so…

I was busy attending a wedding this weekend, so there were no posts. In the mean time, Lipton Matthews (X profile, Substack, Aporia articles) asked if he could write a…
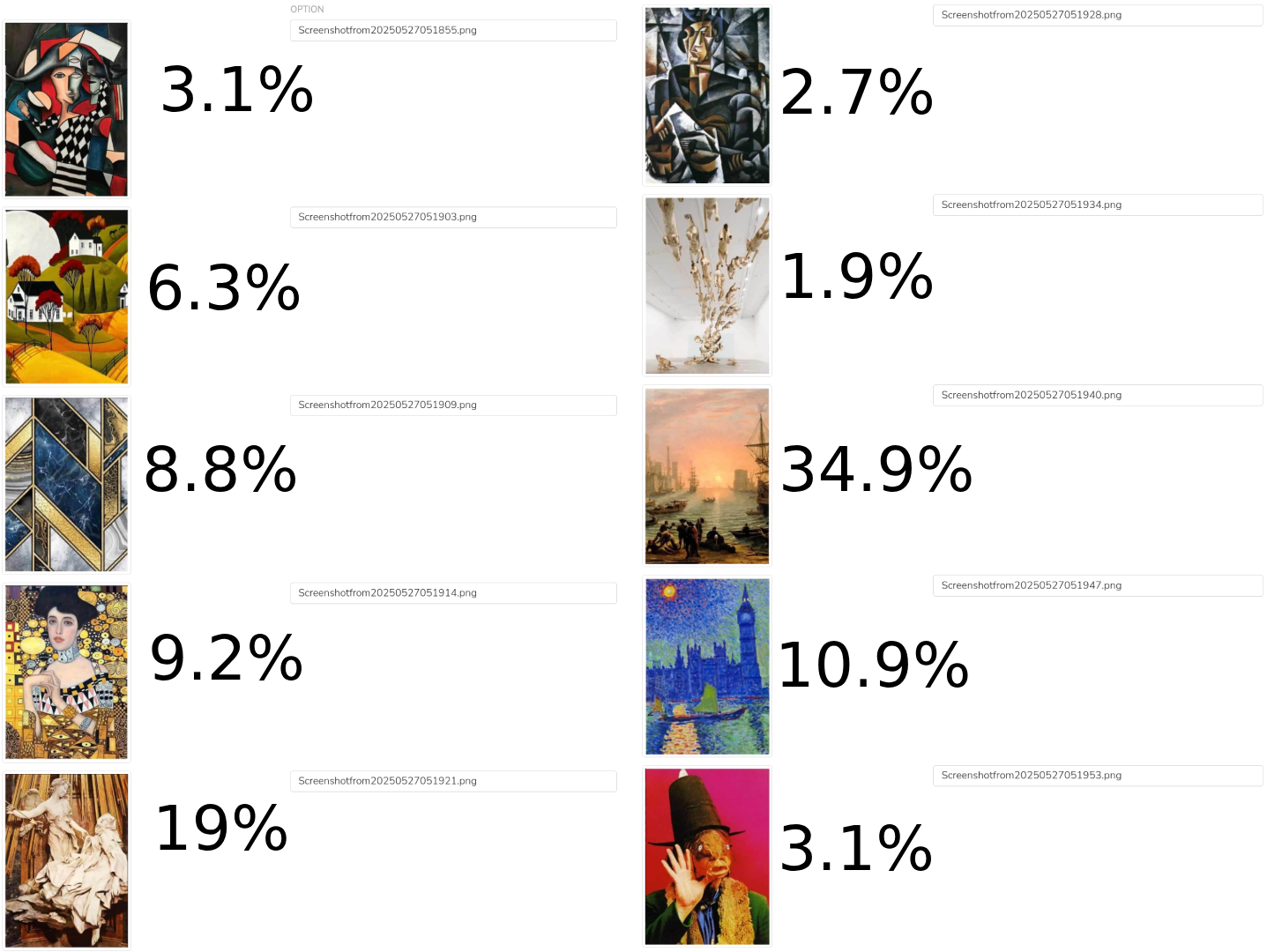
OK, I got tired of waiting for more willing subjects (that is, maybe you), so here's the results of this year's survey. There were 664 subjects of which 320 complete…
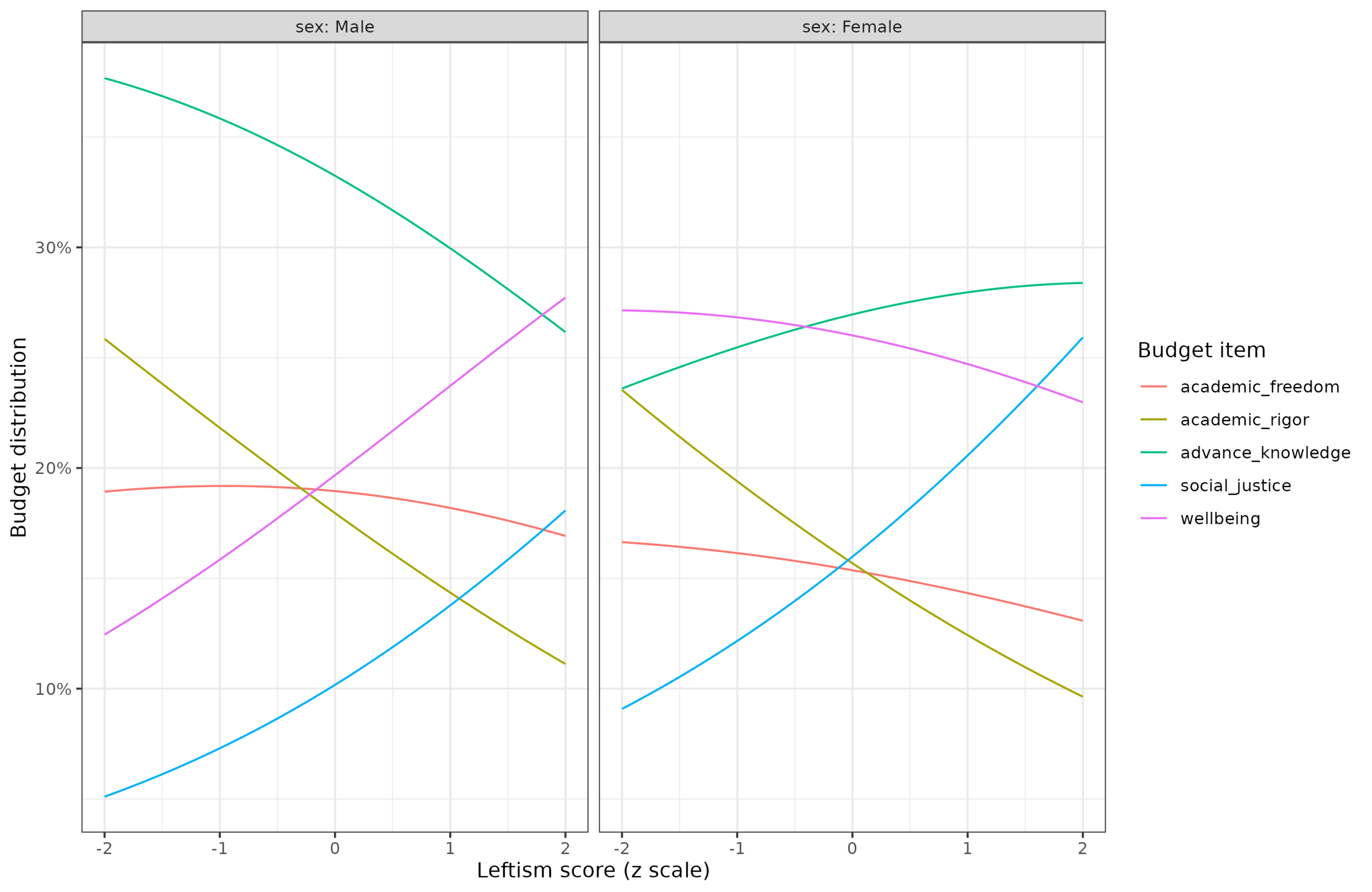
I was browsing studies out in Lee Jussim's newish journal, The Journal of Open Inquiry in Behavioral Science (JOIBS), and saw this one: Rausch, Z. M. (2023). The value gap:…
It's time for another unpopular post, but the principle is right. During human history, there has been a very large number of civil wars, coups, and state collapses due to…

Central to the decline of the West and now almost all high income countries is that they have too low fertility. Just a reminder from the prior post: Why the…

Granted, it is a bit of a strange name, a power law. Is that a particularly powerful piece of legislation? Not at all. It is a kind of statistical distribution,…