
EU health tech at its finest: case study of Oviva
A friend sent me this linkedin post some days ago. I was mainly interested because I thought it might have something to do with making eggs for IVF (oviva meaning…
A friend sent me this linkedin post some days ago. I was mainly interested because I thought it might have something to do with making eggs for IVF (oviva meaning…

I was sent this viral image about ethnicity and pain management: Tracing the source of this, it comes from a 2017 blogpost, which cites an article in NYPost. The complaints…
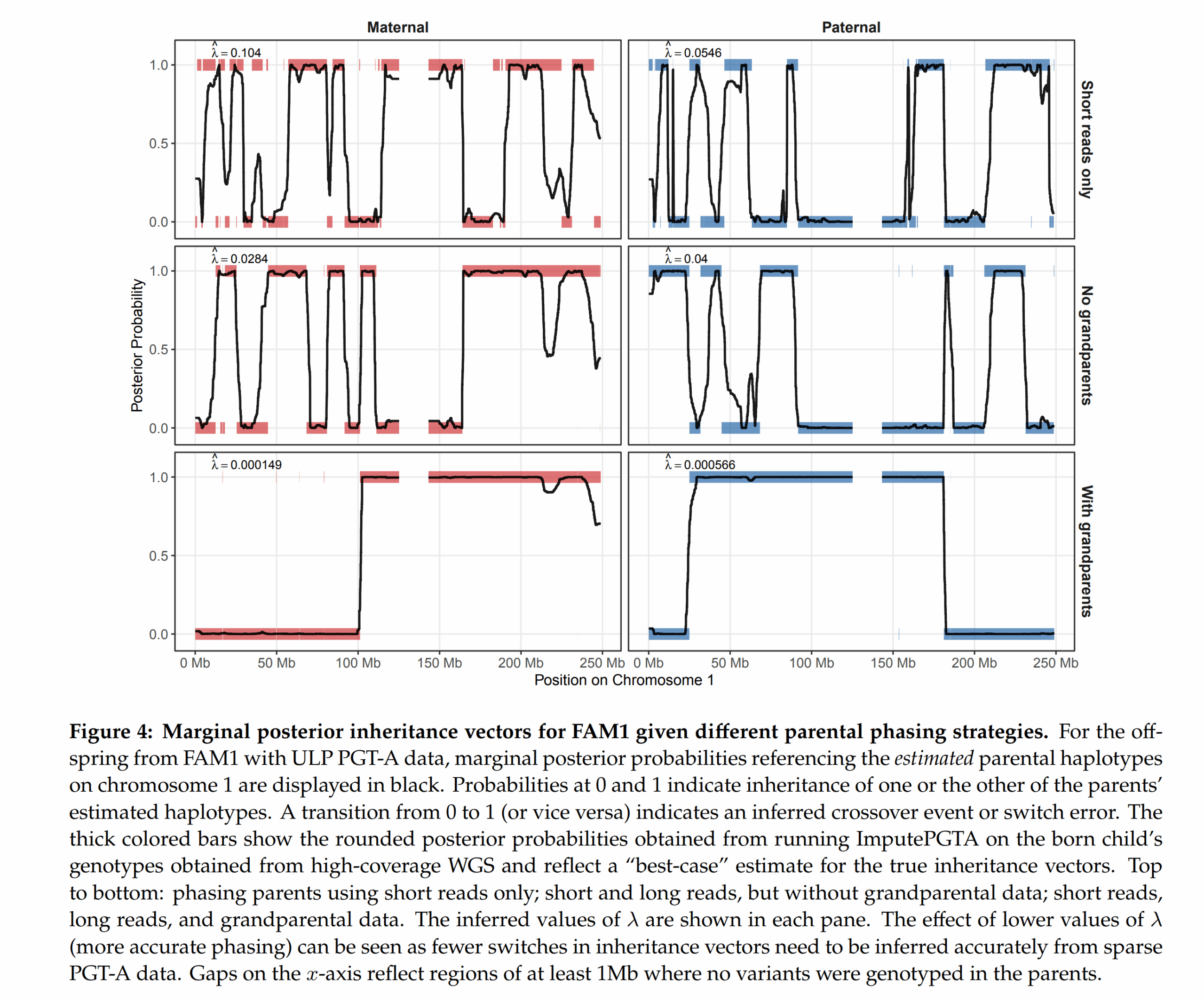
Things are moving fast in the embryo selection sector. There was never really any technological barriers here the last 10+ years, just the usual social taboos and various incompetent people…
There's a few main types of broad-side science criticism: Lowbrow religiously motivated typically focused on denial of biology (evolution) but sometimes expanding widely Verbal tilt philosophy, usually some brand of…
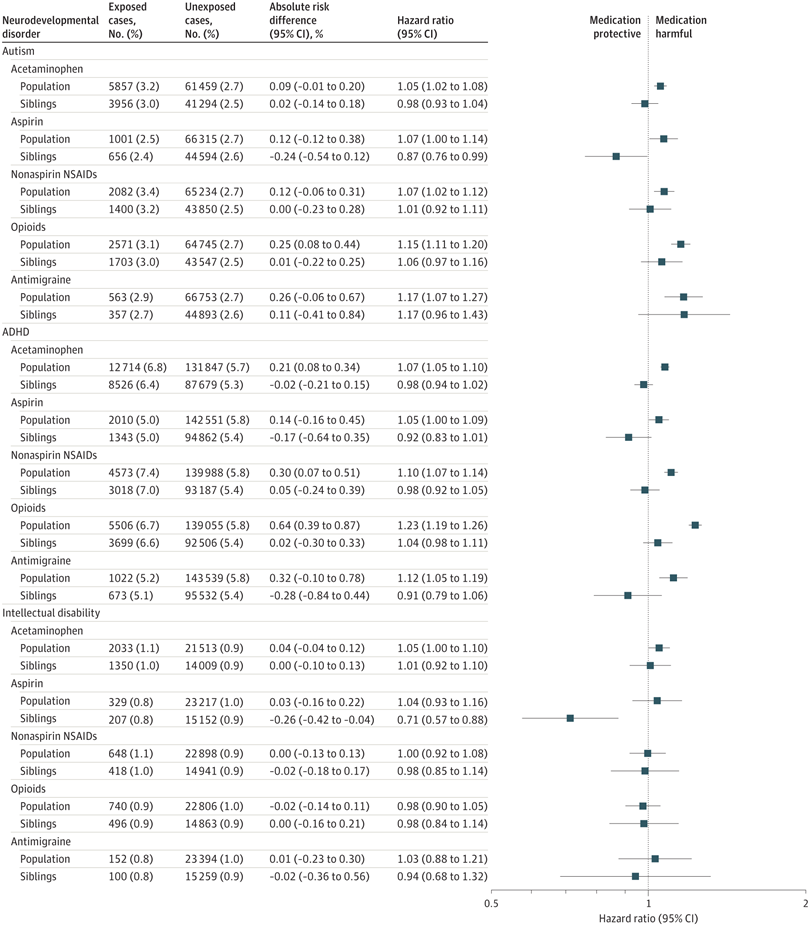
In the latest genius move, the Trump administration has claimed that the commonly used painkiller paracetamol (Tylenol, Panadol, acetaminophen, various other names) causes autism. As we have seen however, there…
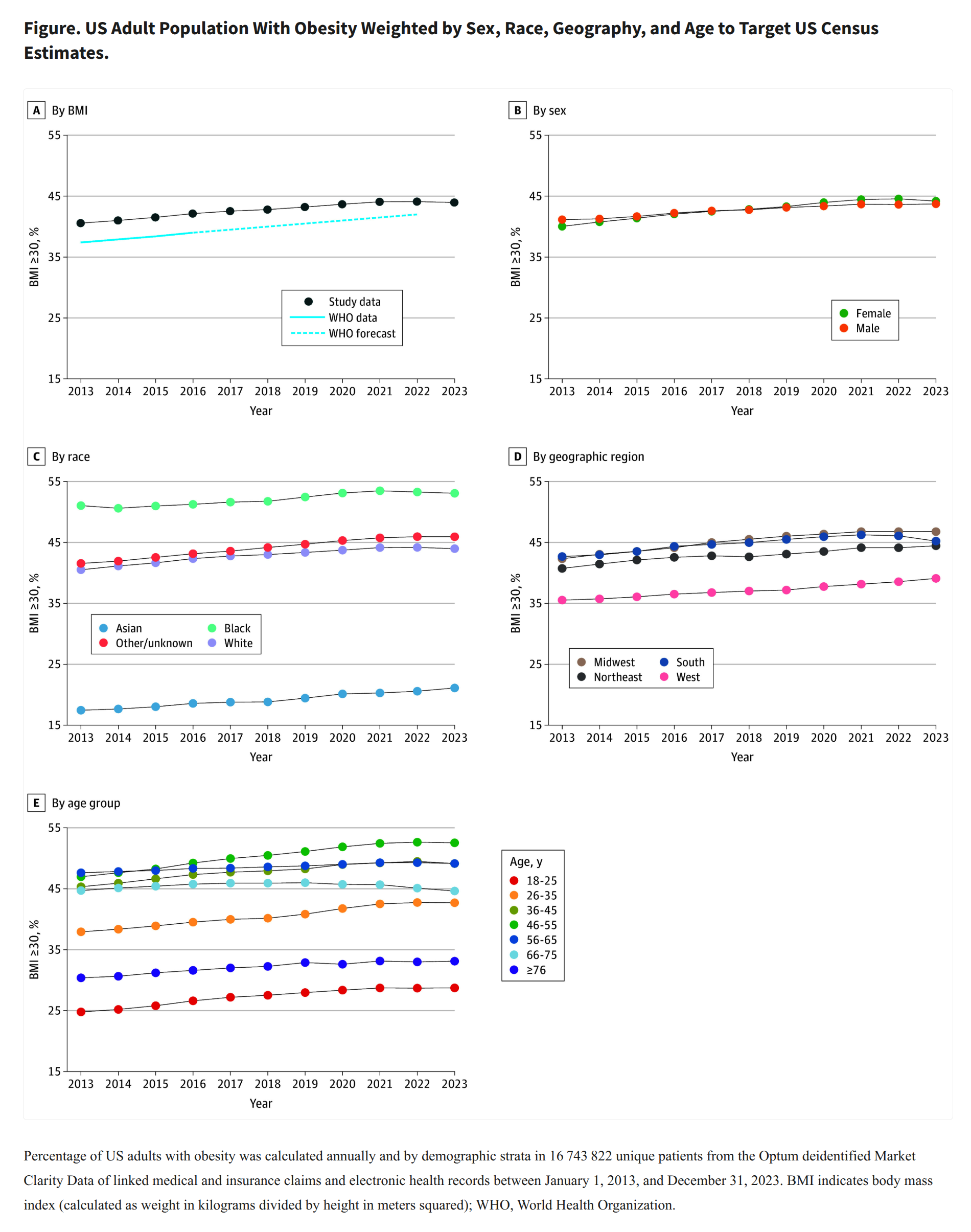
In tech circles, there has recently been many people cheering for the apparent success of Ozempic-like drugs (GLP-1 agonists) in finally reducing the American obesity rate. More and more variants…
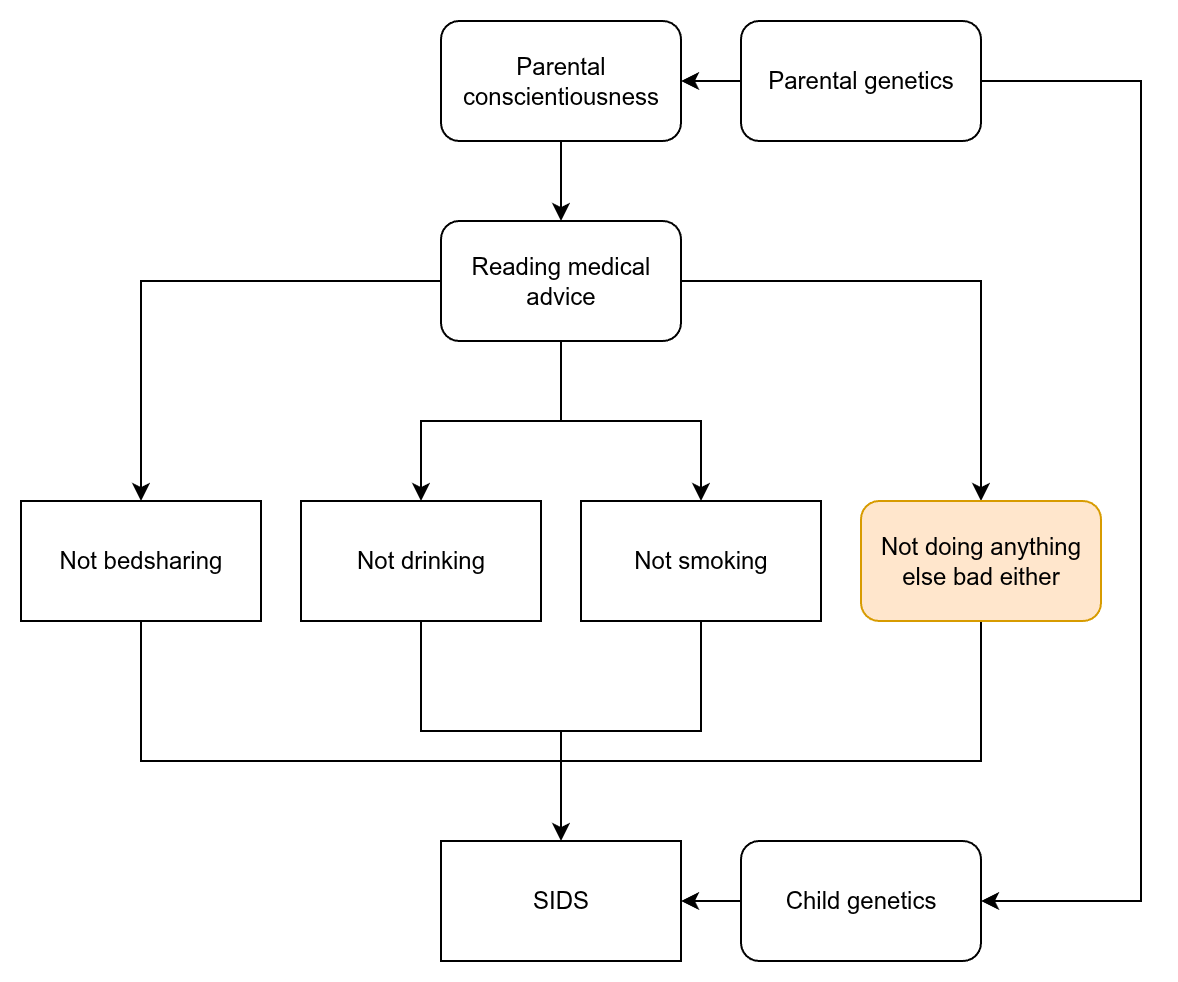
There is probably going to be a lot of baby-related science posting. You will have to forgive me. On the other hand, my own reader survey shows that the fertility…

And so the day came, August 12, our first child joined the world: Given how great early life interventions work, I started immediately with important topics like British history: Kidding…
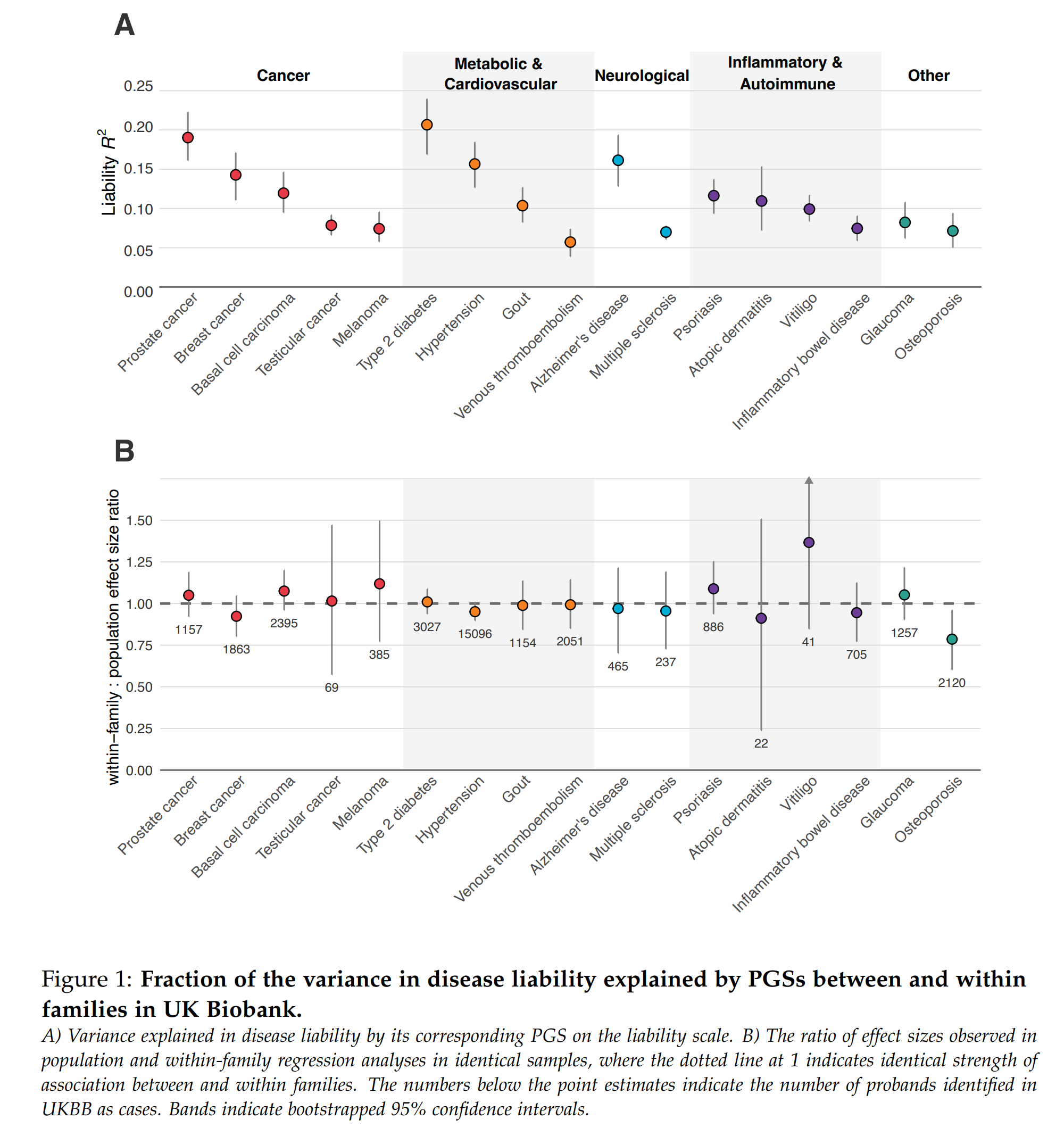
Today is an exciting day. First, the HHS announced a more open data policy (in the direction of my suggestions), and second and more importantly, a new company just went…
I've been writing about fertility for a while. Of recent interest is the COVID or post-COVID fertility decline. Birth Gauge compiles the most up to date TFR (total fertility rate)…