
Penalization for small n problems: case study of Steam games
For many kinds of ranking websites, users are naturally going to be interested in the leaderboard or top list, the best of the best. This is the same thing for…
For many kinds of ranking websites, users are naturally going to be interested in the leaderboard or top list, the best of the best. This is the same thing for…
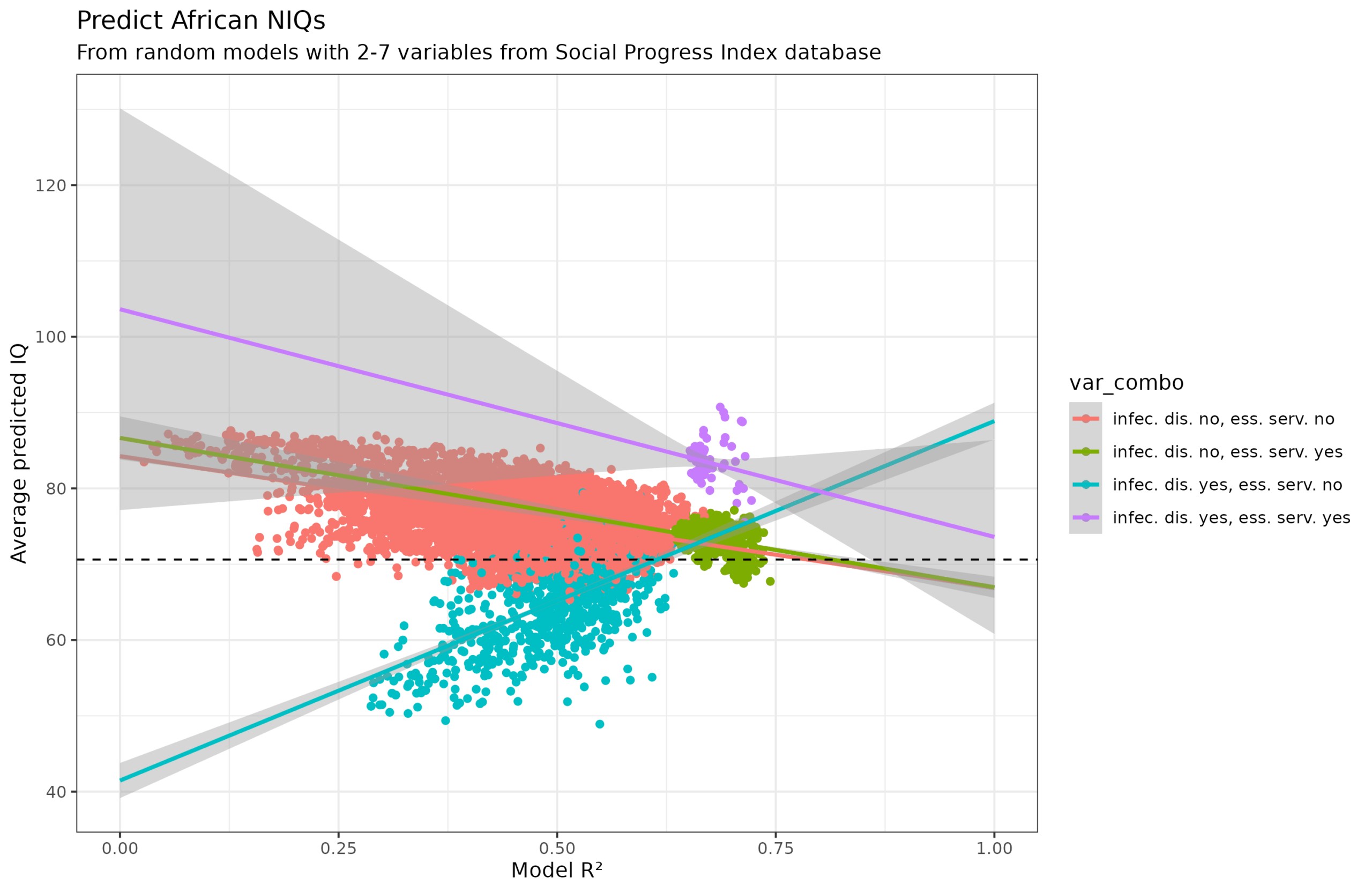
Heiner Rindermann sent me his new review paper: Rindermann, H. (2025). Low cognitive ability estimates in developing countries: A statistical analysis of their credibility. Human Evolution, 40(3–4), 257–284. https://doi.org/10.14673/HE2025341159, Developing countries…
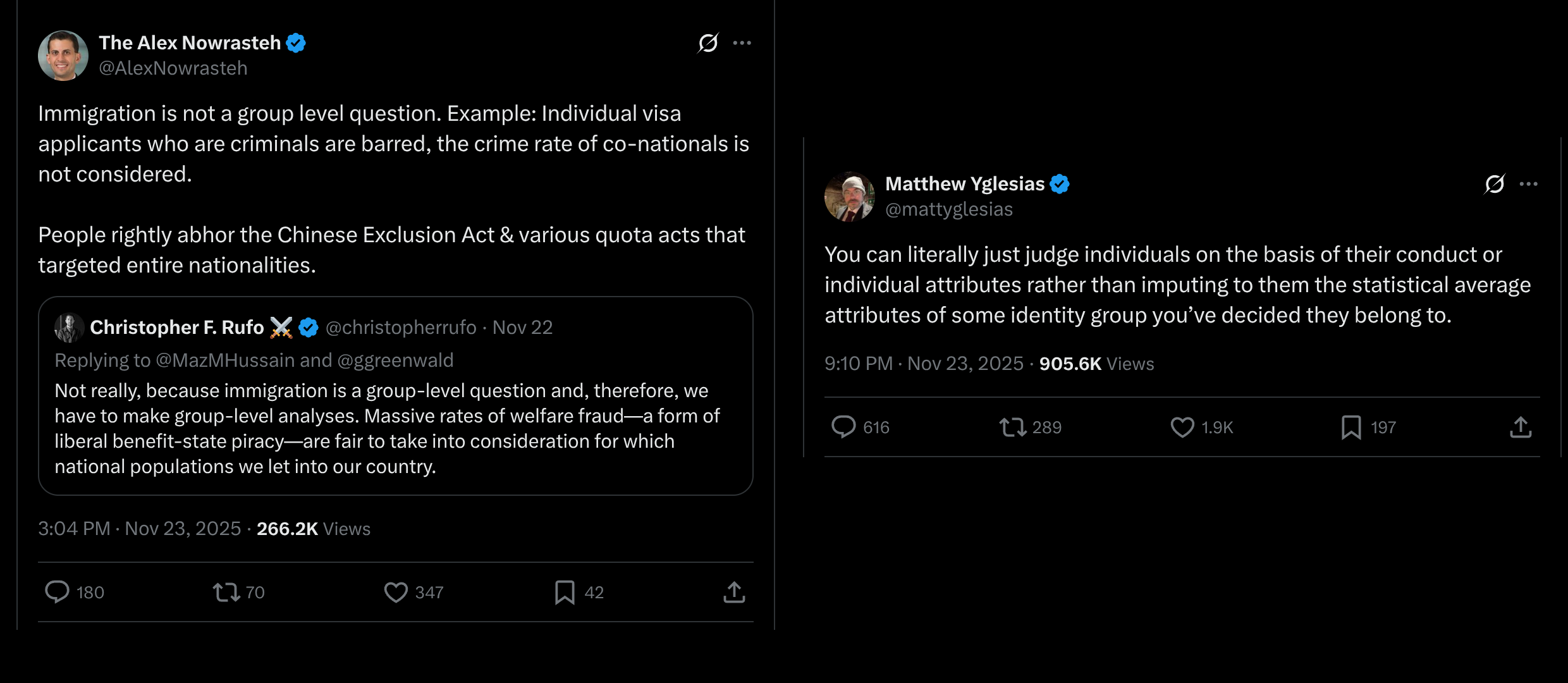
Chris Rufo wasn't happy with the recent American experience with the Somalians scamming the welfare state and wrote about how one should take into account "which national populations" people wish…
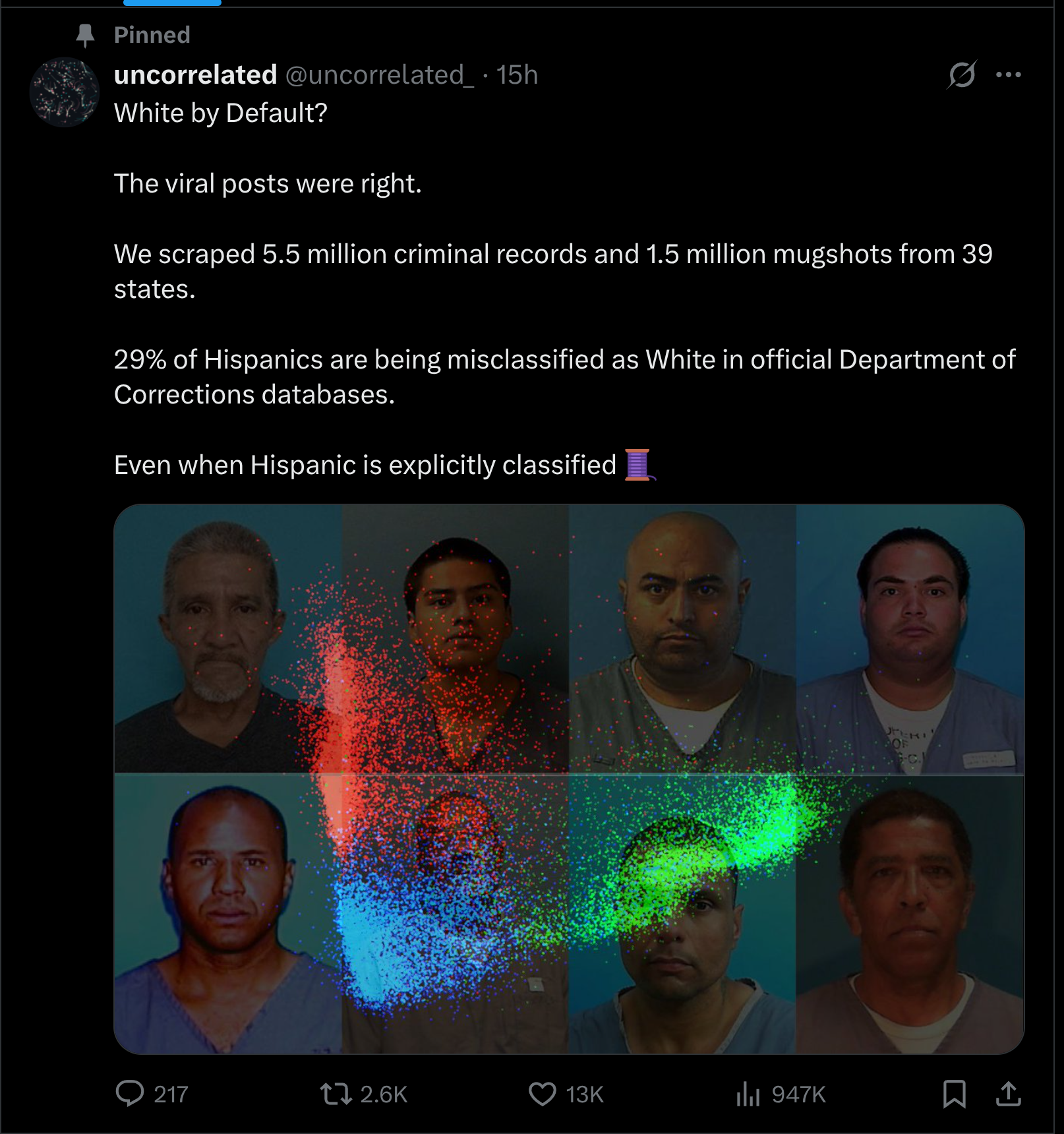
Our latest big project on mugshots and race misclassification by the US law enforcement. It is currently going viral on X: You can start by reading the thread summary, or…
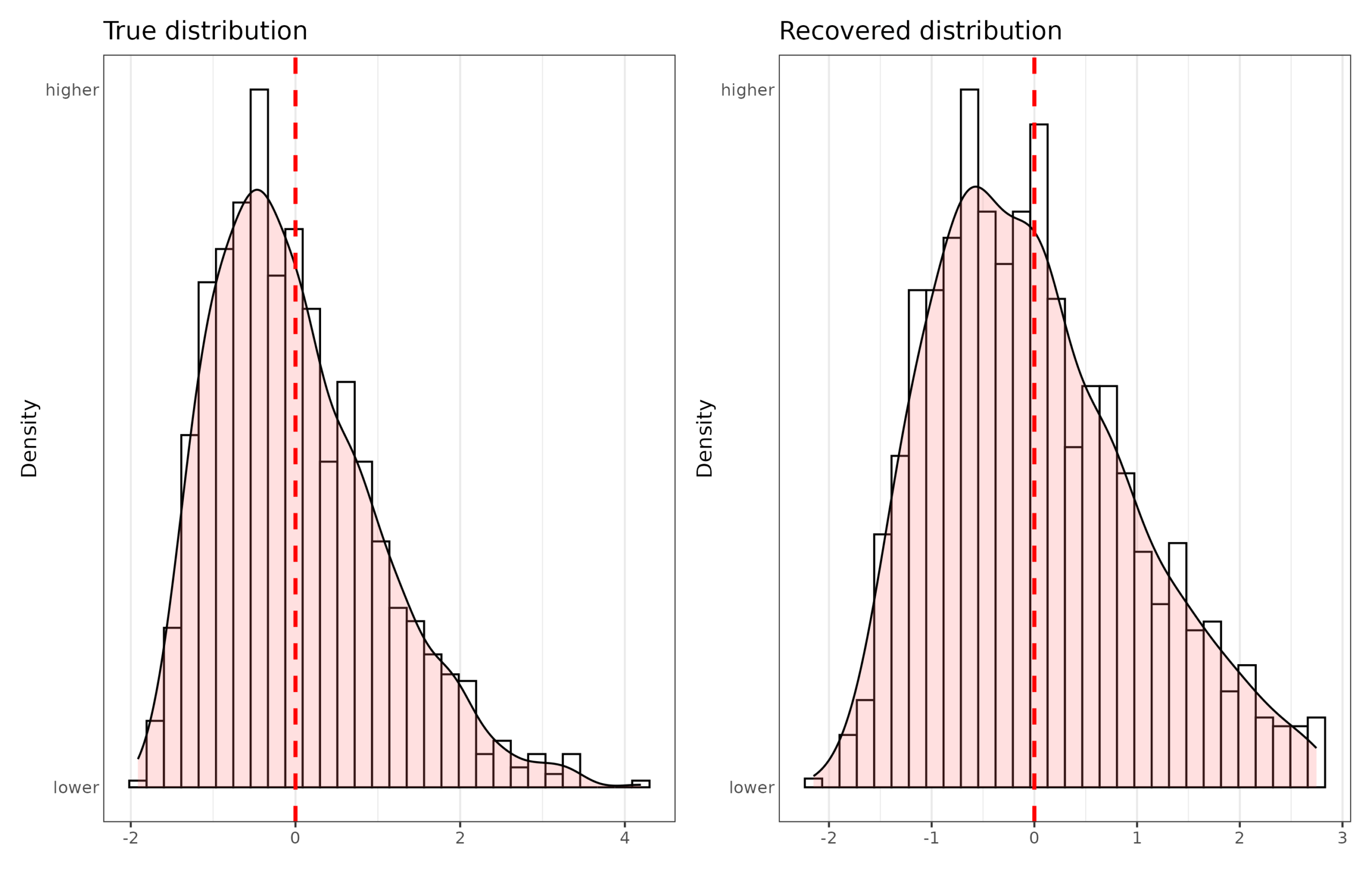
One of the more obscure objections to intelligence testing is that really the tests are only on ordinal scale, and thus many of the usual statistical operations are undefined. Recall,…
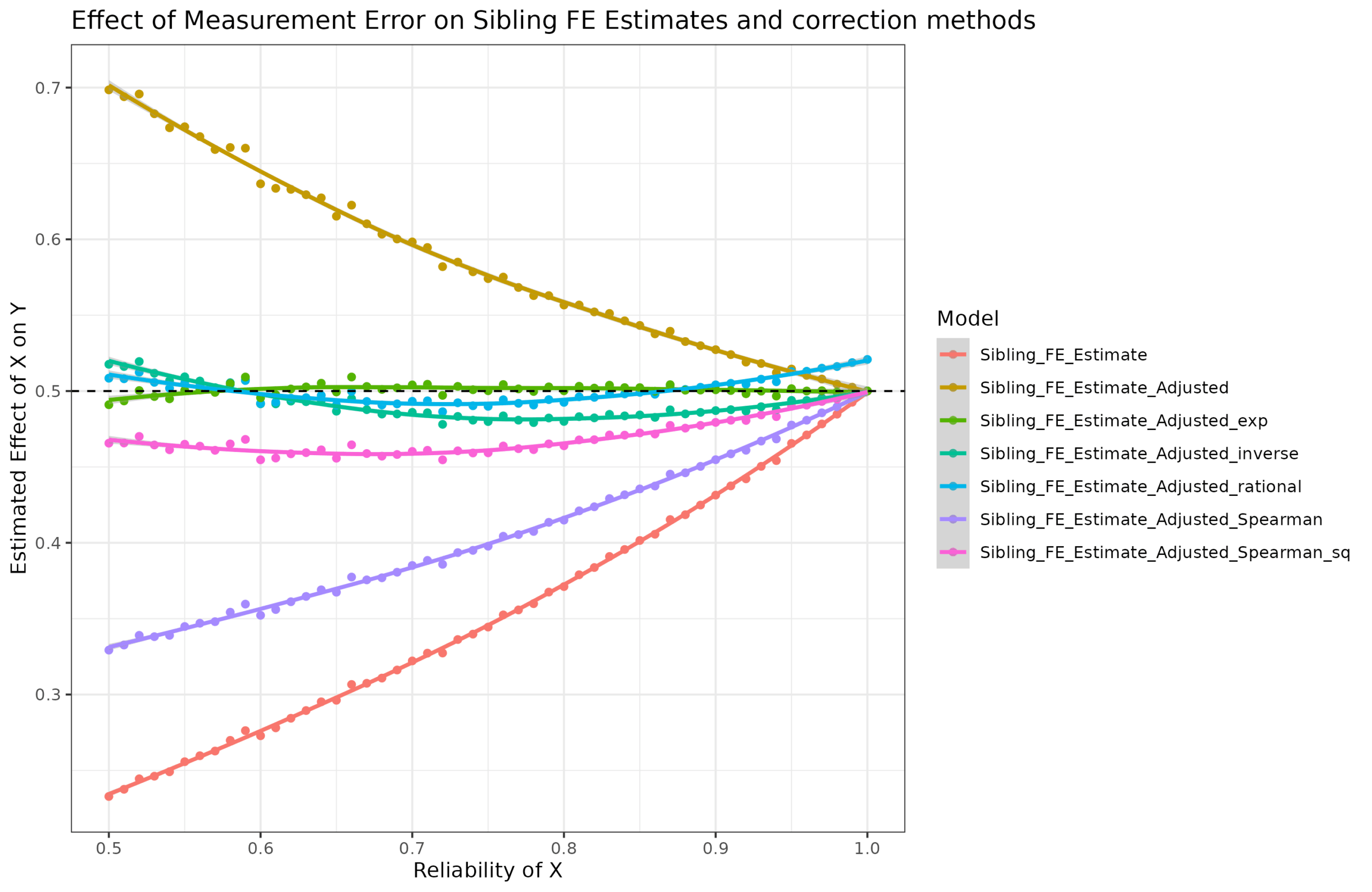
There was a lot of discussion regarding the corrections for measurement error used in the recent Herasight intelligence polygenic score paper. I covered it for Aporia. I want to dive…
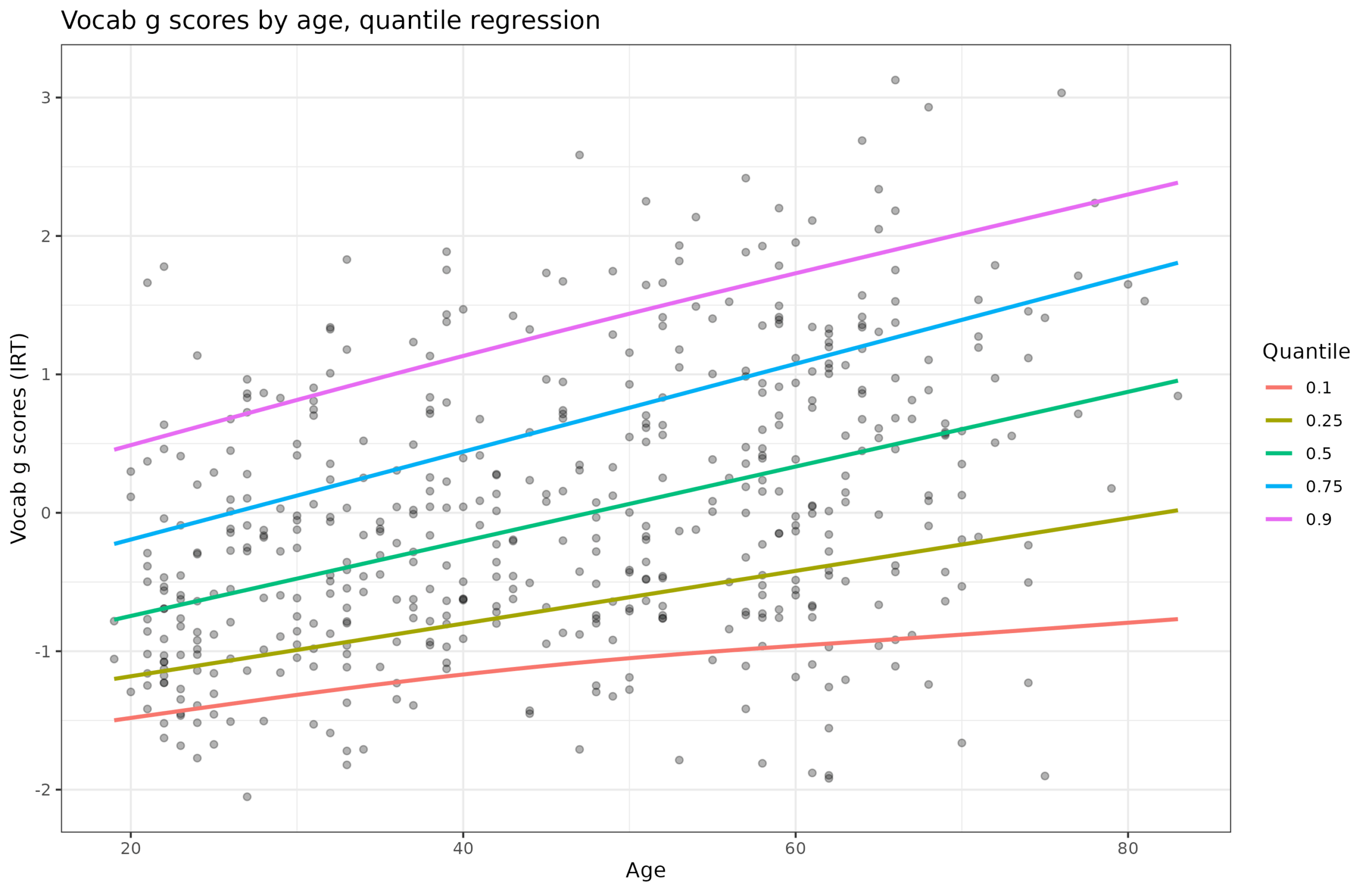
Suppose you have created a new scale of something ("Science Blog Rating Scale"). It can be psychology or some other soft science, but it doesn't have to be. Suppose you…
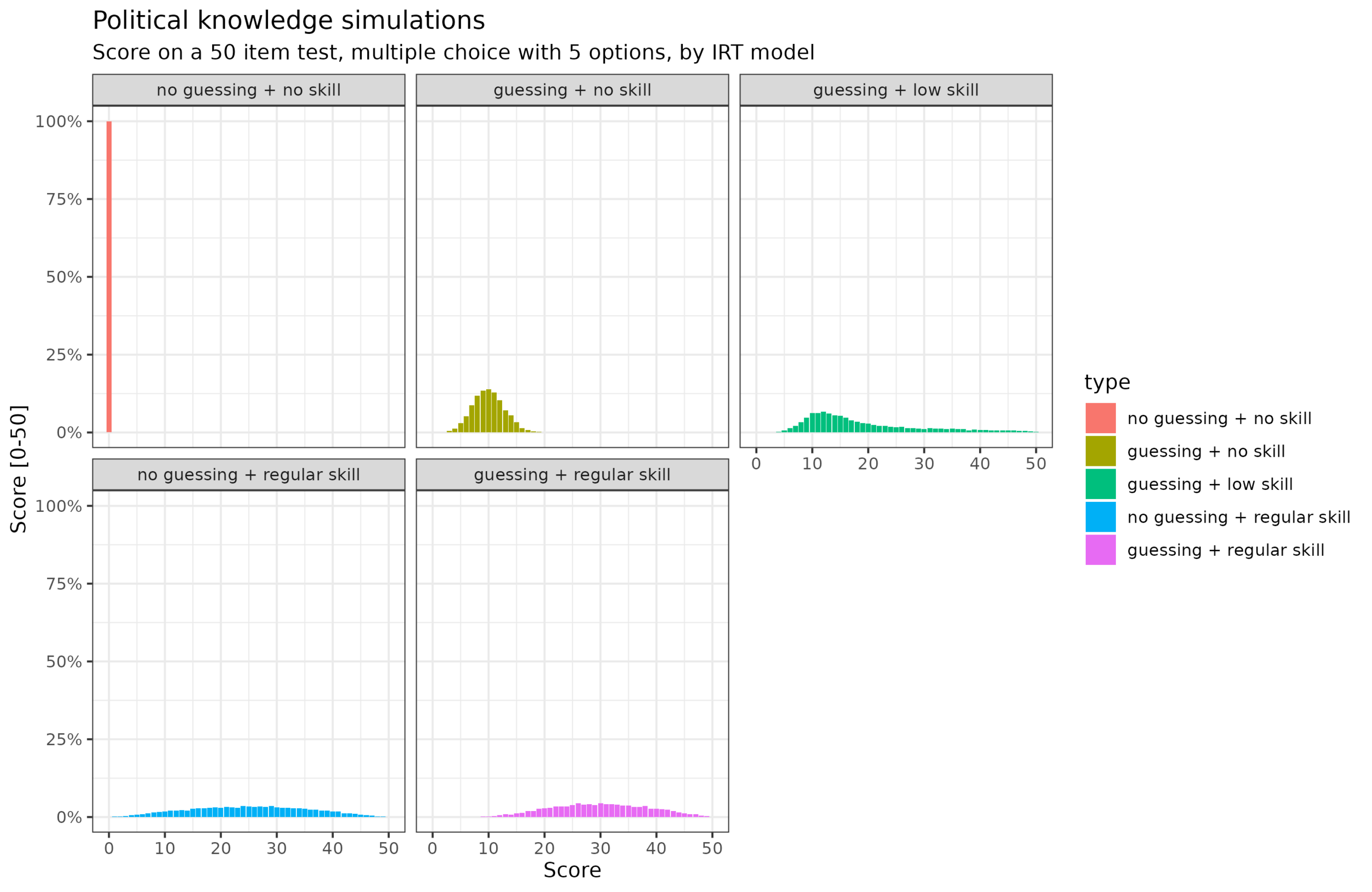
I'm reading Jason Brennan's 2016 book Against Democracy, actually in favor of votes weighted by competence, which he calls epistocracy. In discussing the very low levels of political knowledge seen…
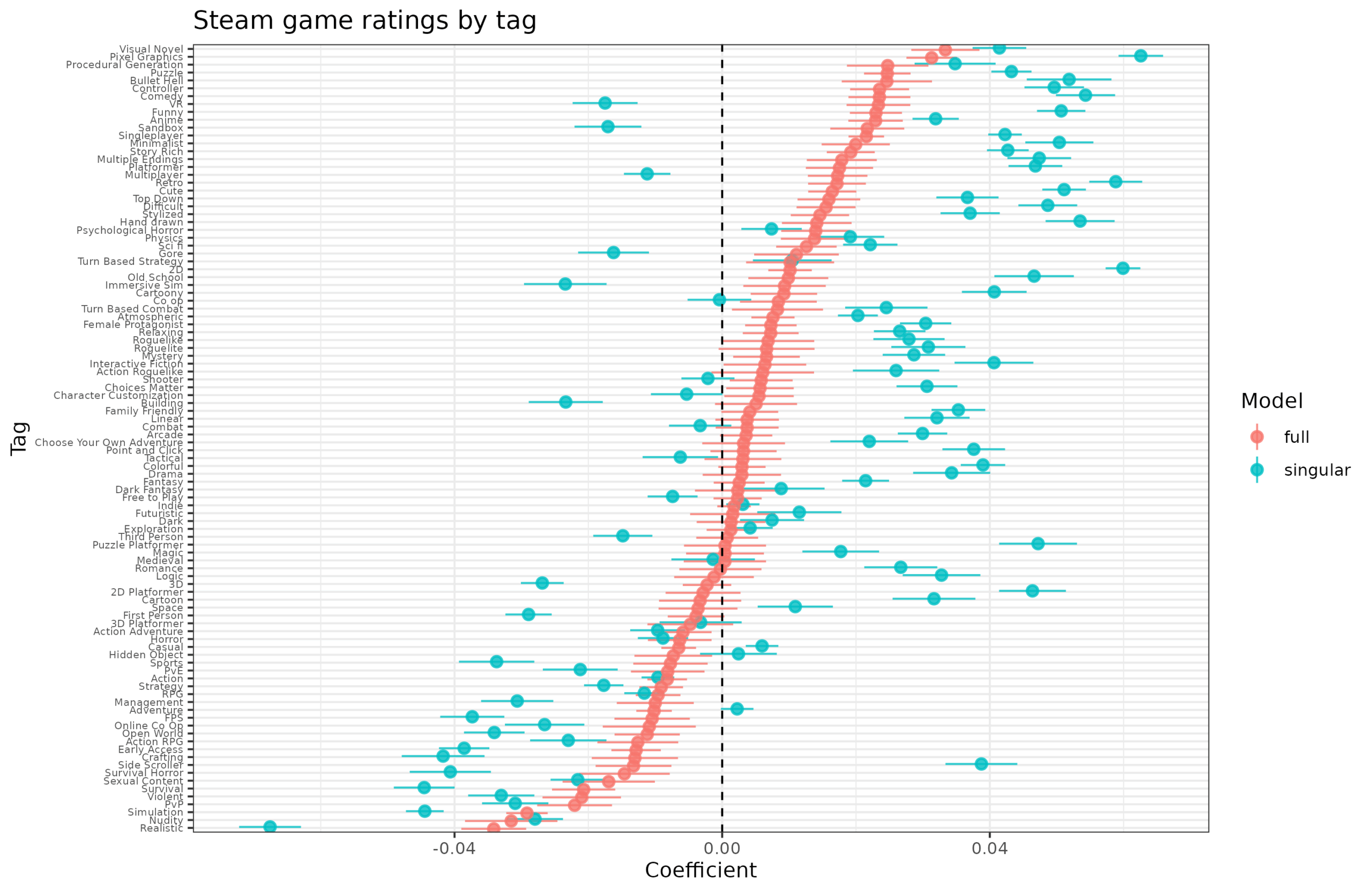
What makes a better computer game? While we can discuss game design (e.g. I studied skill vs. randomness before), we can also take an empirical approach. What we need is…
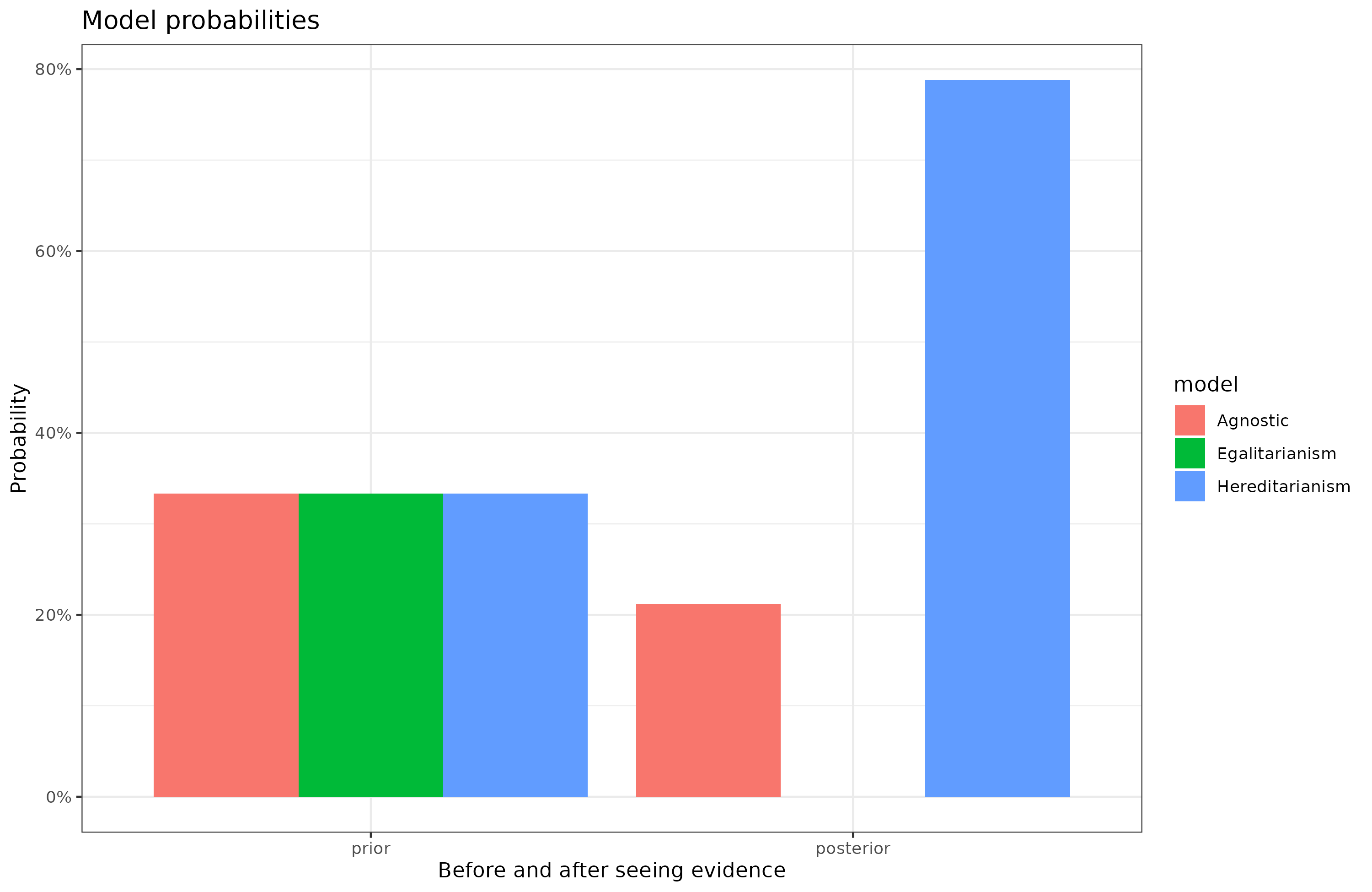
In august 2023, Sean Last wrote an important post that didn't receive enough attention. His point was that model comparisons are not correctly (Bayesically) applied in the hereditarianism vs. egalitarianism…