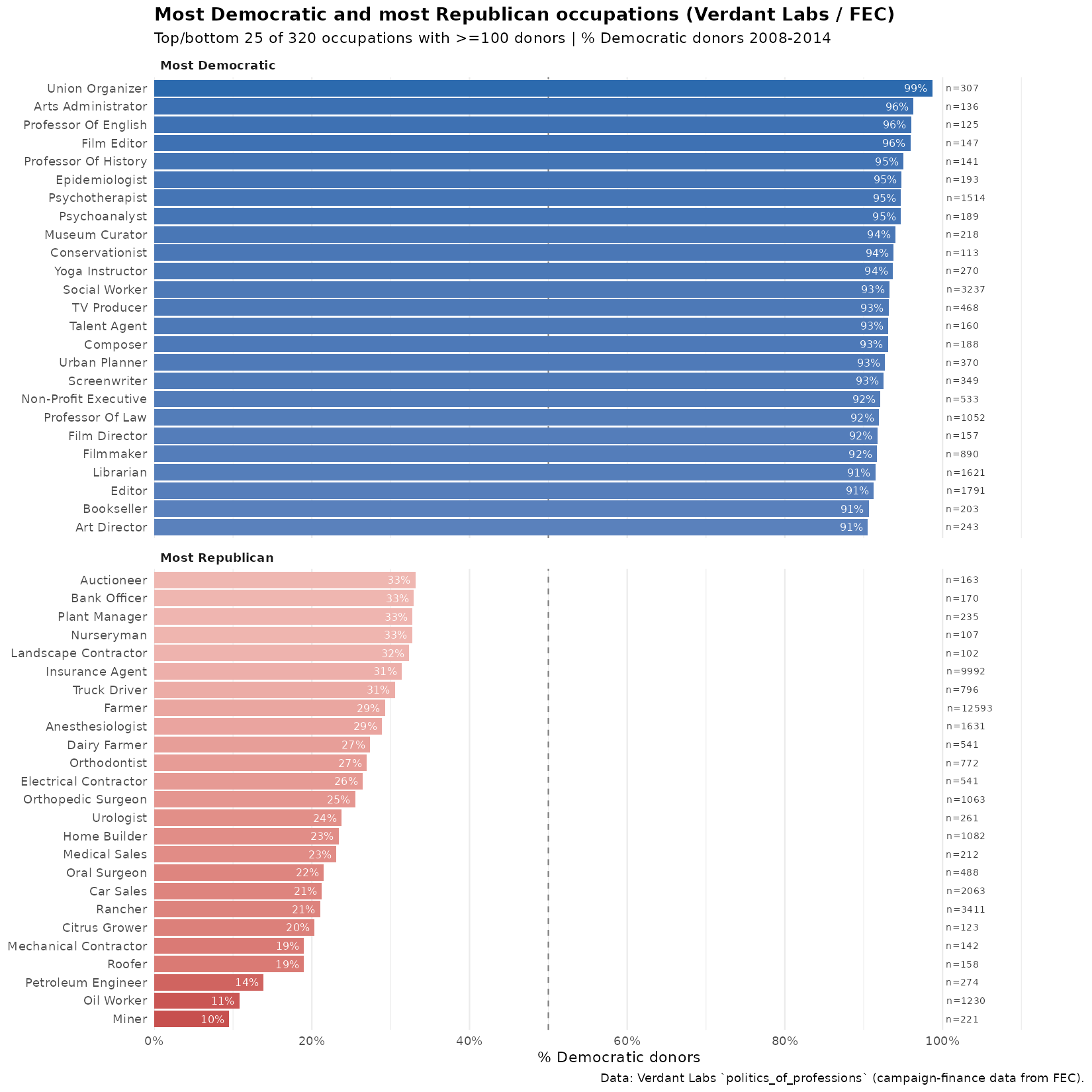
Occupations, fertility, men, and politics
In response to my prior post on the fertility rates of American women by occupation, some asked for the results for men, and others pointed out that there seems to…
In response to my prior post on the fertility rates of American women by occupation, some asked for the results for men, and others pointed out that there seems to…
In a world of declining fertility, we have to ask ourselves why it is so declining. I've spent many posts on that question. We could also ask instead, how do…
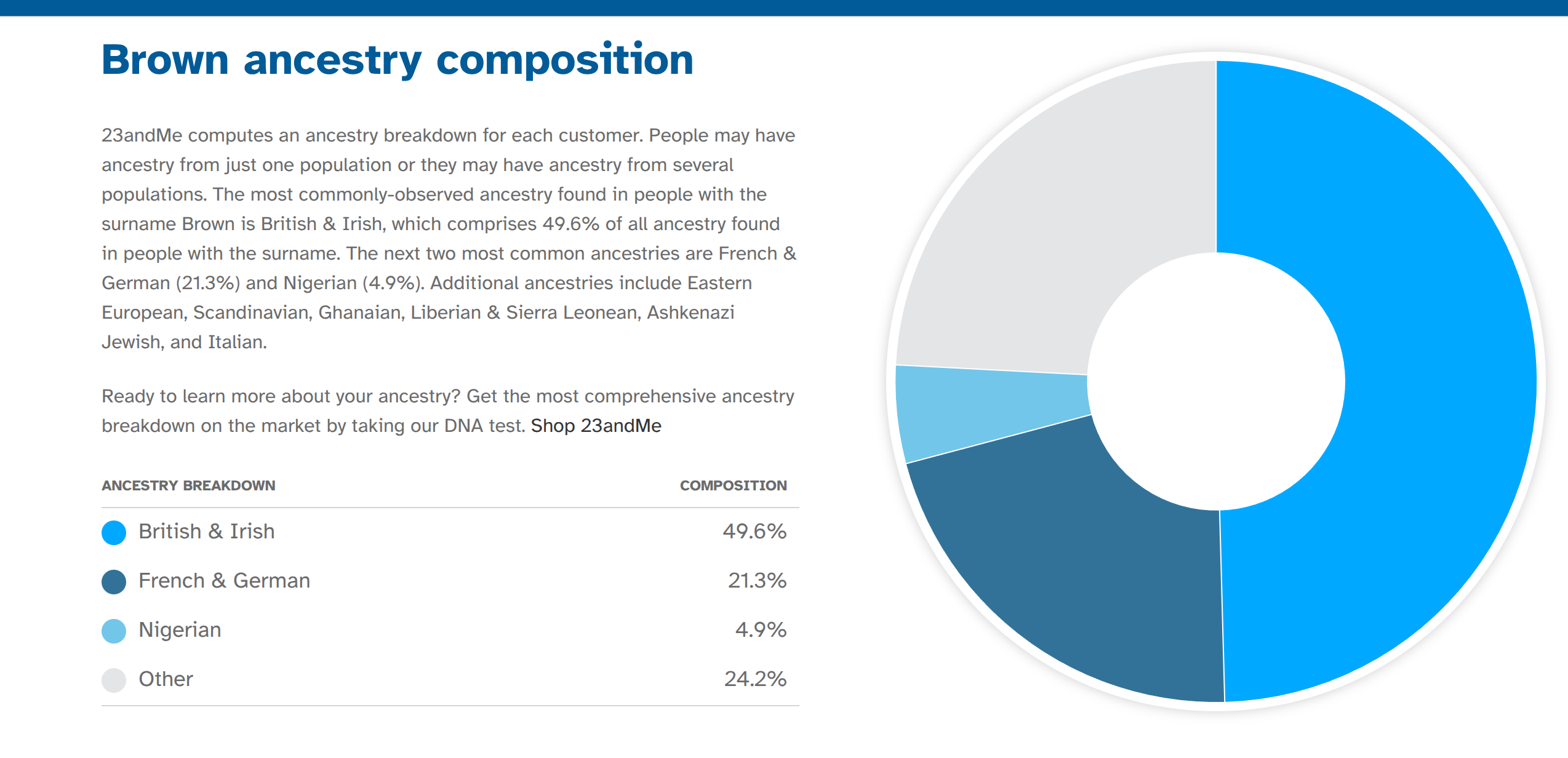
Our big project was finally published: Van Pelt, D., & Kirkegaard, E. O. (2026). Big Data, Deep Roots: Correlating Surname Genetic Ancestry and Socioeconomic Status across Millions of Americans. Comparative…
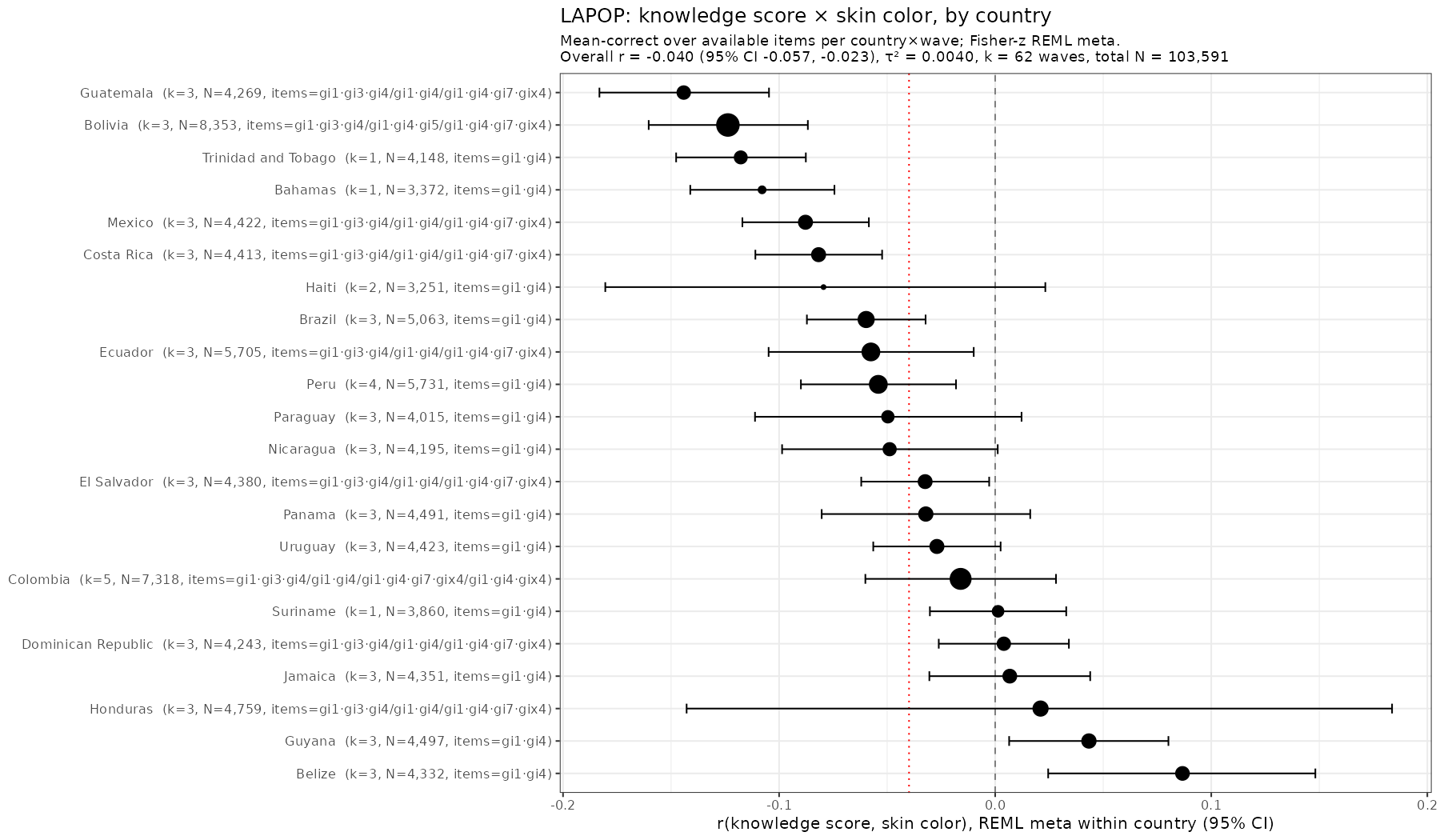
Skin color (lightness or brightness) has been used as a proxy for genetic ancestry for over 100 years. It works alright in many cases. Take this study (Parra et al…

Many years ago I discovered that Brazil publishes the subject level data for many scale testing efforts. These also come with rich surveys concerning the children's homes. The main tests…
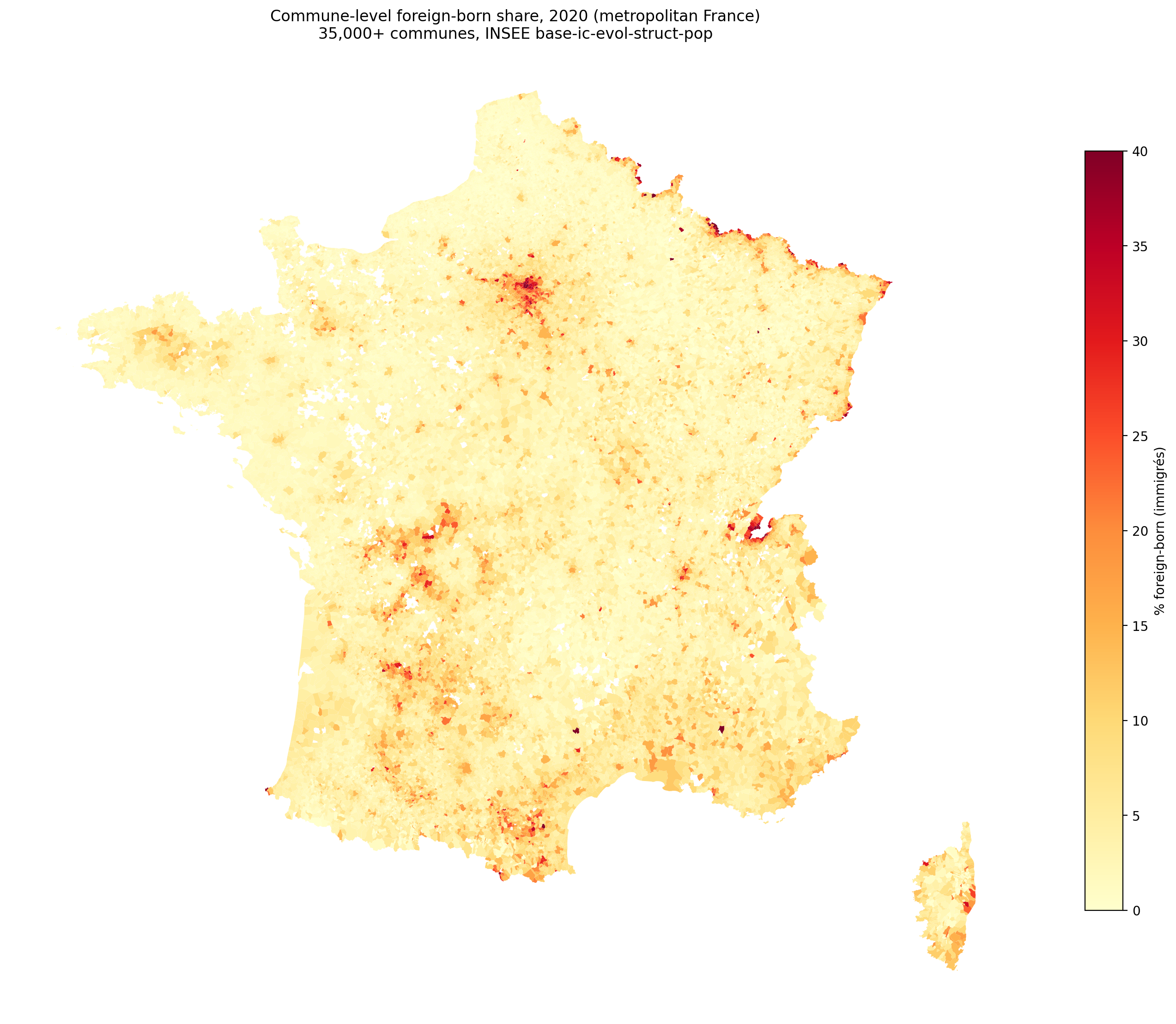
France is the 4th most populous country in Europe these days (it used to be number 1 before it had early secularization). It is also quite insular when it comes…

A politician from the Social Democrats called Frederik Vad (center-left government party) posted results of a survey about how safe citizens report feeling in various areas of the country. There…

The Danish constitution says: §44 (1) No alien shall be naturalized except by statute. (2) The extent of the right of aliens to become owners of real property shall be…

Some years ago, I gave a good idea of a study to a friend, and he did it. But then he just never published his study anywhere, it's just sitting…

I saw this funny and one might say provocative study: Schahbasi, A., Huber, S., & Fieder, M. (2021). Factors affecting attitudes toward migrants—An evolutionary approach. American Journal of Human Biology,…