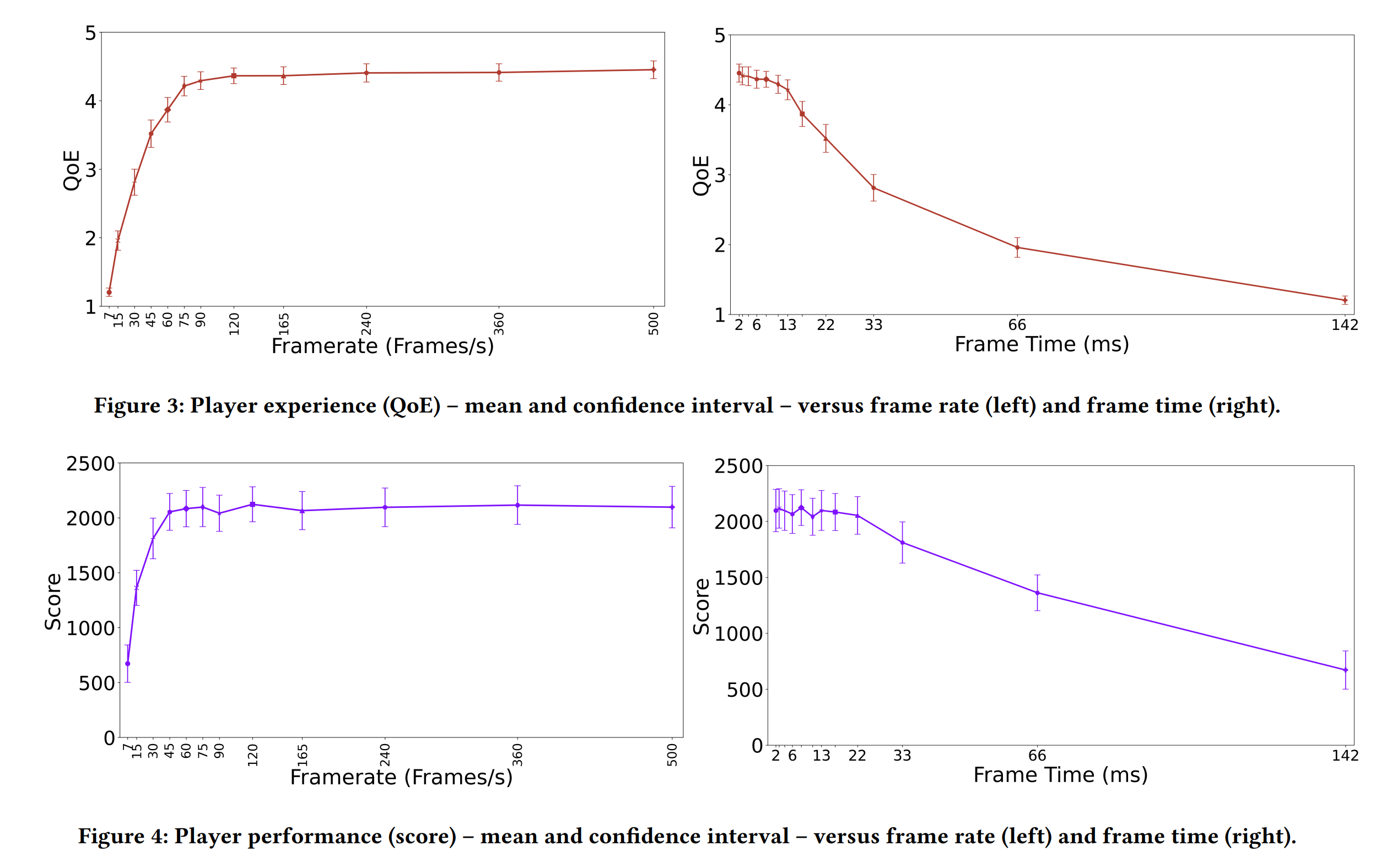
How many frames per second (fps) is enough?
In the last few years, a competition opened up among gamers about having the screens and computers generating the most frames per second. Traditionally, 60 fps was the gold standard,…
In the last few years, a competition opened up among gamers about having the screens and computers generating the most frames per second. Traditionally, 60 fps was the gold standard,…

So you've seen stuff like this: There's an endless such number of photos, nearly literally. AI will generate these on the fly for any content you desire. So since a…
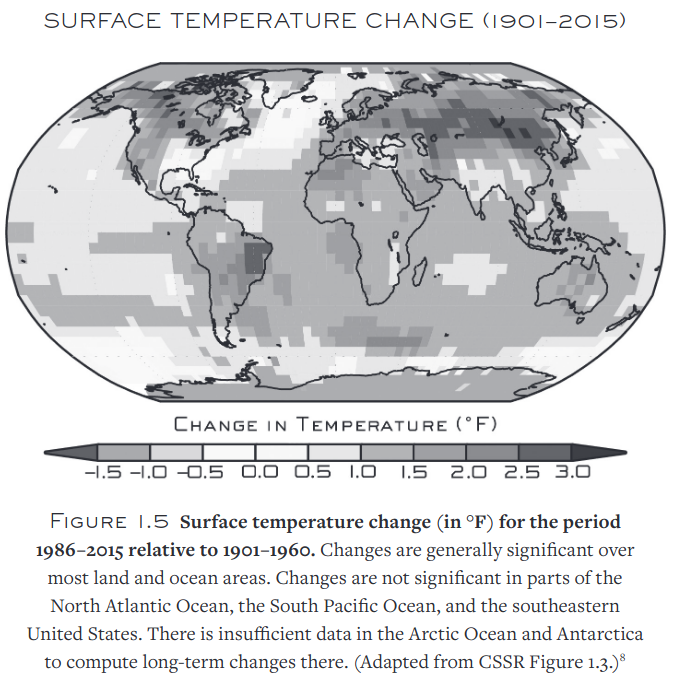
So I've gone back to my old habit of binge reading on mostly unrelated topics to my main work in the genetics-social science cluster. Climate science is a long running…
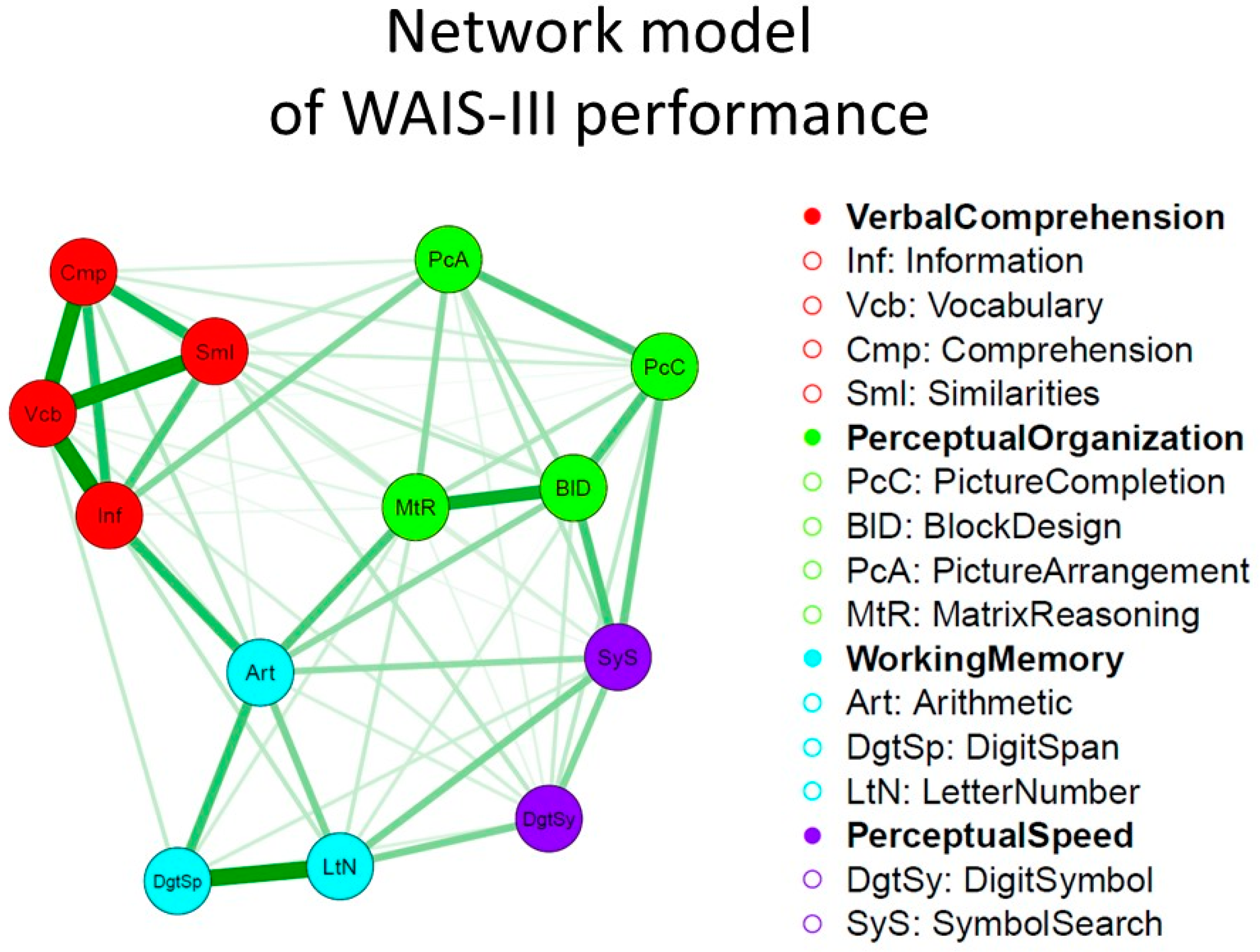
Someone sent me this email: Hello Emil I was wondering if you knew about any similar papers to this one: https://www.sciencedirect.com/science/article/abs/pii/S0160289608001591 Also, what are your thoughts on mutualism (which I…
Baumeister, H., & Montag, C. (Eds.). (2019). Digital Phenotyping and Mobile Sensing: New Developments in Psychoinformatics. Springer Nature. This book offers a snapshot of cutting-edge applications of mobile sensing for…
I came across this obscure study while doing some research on other matters. Yan, H., Lavoie, A., & Das, S. (2017). The Perils of Classifying Political Orientation From Text. Linked…
Not an endorsement of this technology or the use of it, just stating that it will happen. Given sufficient measurement precision, all humans have unique genomes and fingerprints, but also…
So, Logitech software only works for Windows. Unfortunately, the sensitivity is extremely high by default, making the mouse much less useful. The extra buttons also have no function, which is…
I could not find someone that briefly described this problem, so I'll just do a very quick job at doing so. I take it that this is a common observation…
Syncthing is a open source synchronization application. It's a replacement for the closed source Bittorrent Sync (BTS). If you are currently using BTS, I recommend switching because 1) it's closed…