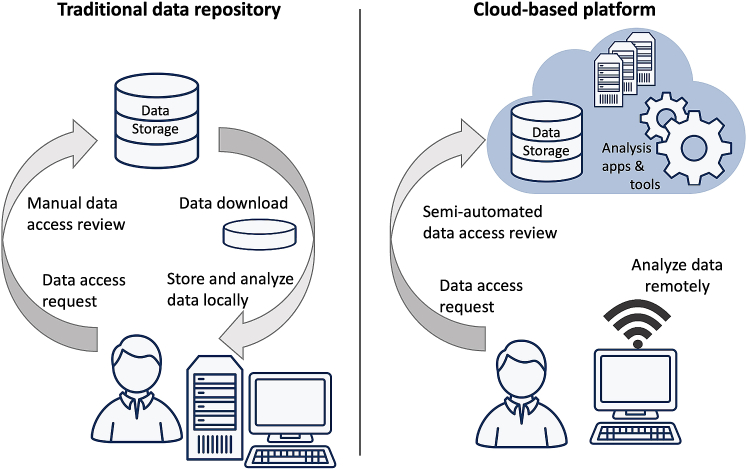
Accelerating genetic science: turning around the data access censorship
James Lee, authors of many GWAS studies wrote a piece in 2022 entitled Don't even go there saying that NIH is increasingly censorious regarding data access. Since it is short, I…

