
Race, intelligence, and inequality in Brazil
Many years ago I discovered that Brazil publishes the subject level data for many scale testing efforts. These also come with rich surveys concerning the children's homes. The main tests…
Many years ago I discovered that Brazil publishes the subject level data for many scale testing efforts. These also come with rich surveys concerning the children's homes. The main tests…
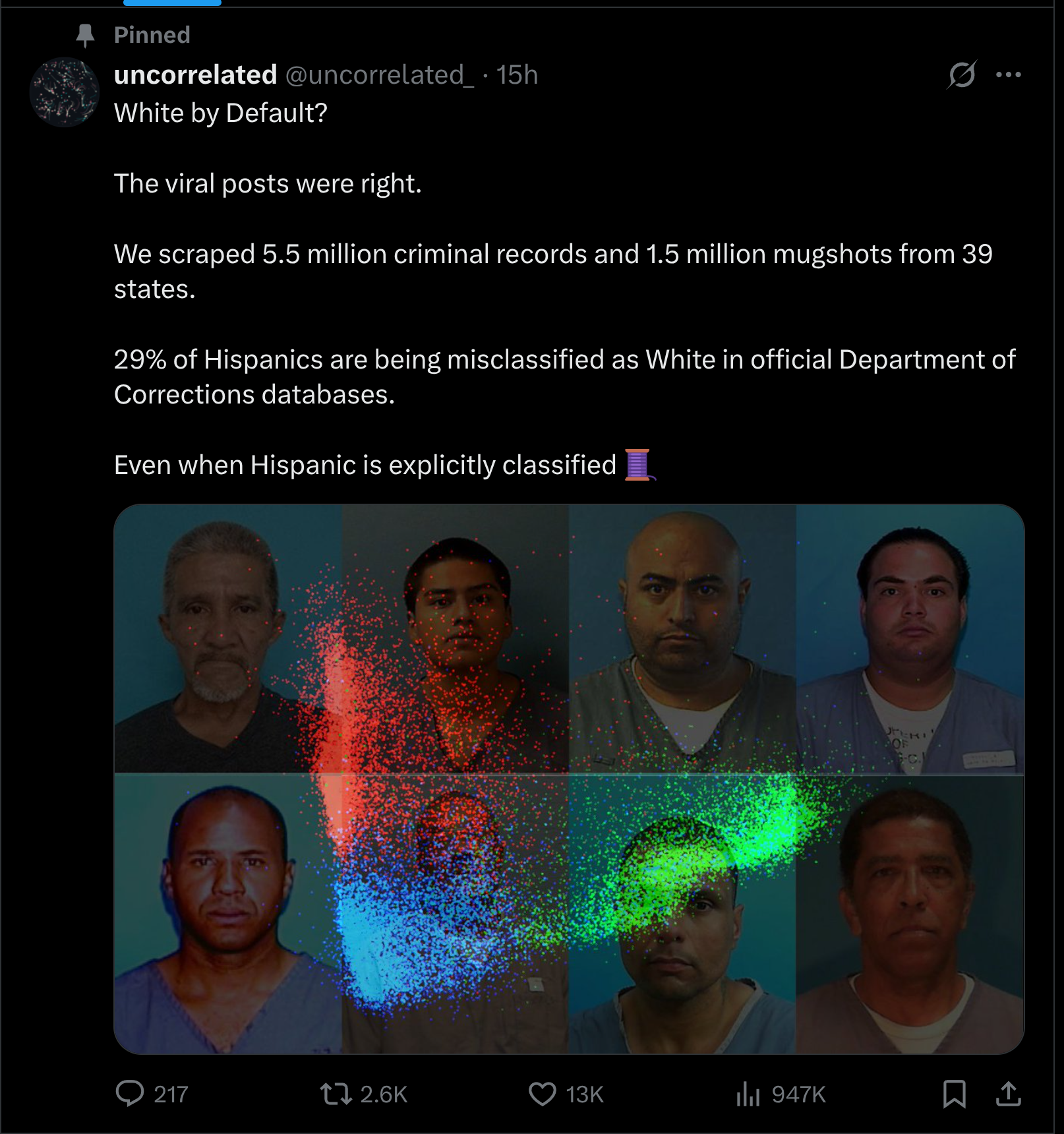
Our latest big project on mugshots and race misclassification by the US law enforcement. It is currently going viral on X: You can start by reading the thread summary, or…
The American National Election Studies (ANES) is a series of surveys that has been administered to broadly representative samples of Americans since 1948. They asked thousands of questions, though most…
I can't resist blogging this one. First, so it doesn't get lost, and second because it's scientifically interesting. Right now, Haiti is in the news due to social failure and…

There is a lot of debate about immigration. While it is relatively easy to find crime rates by various immigrants by country of origin, these don't directly tell you whether…
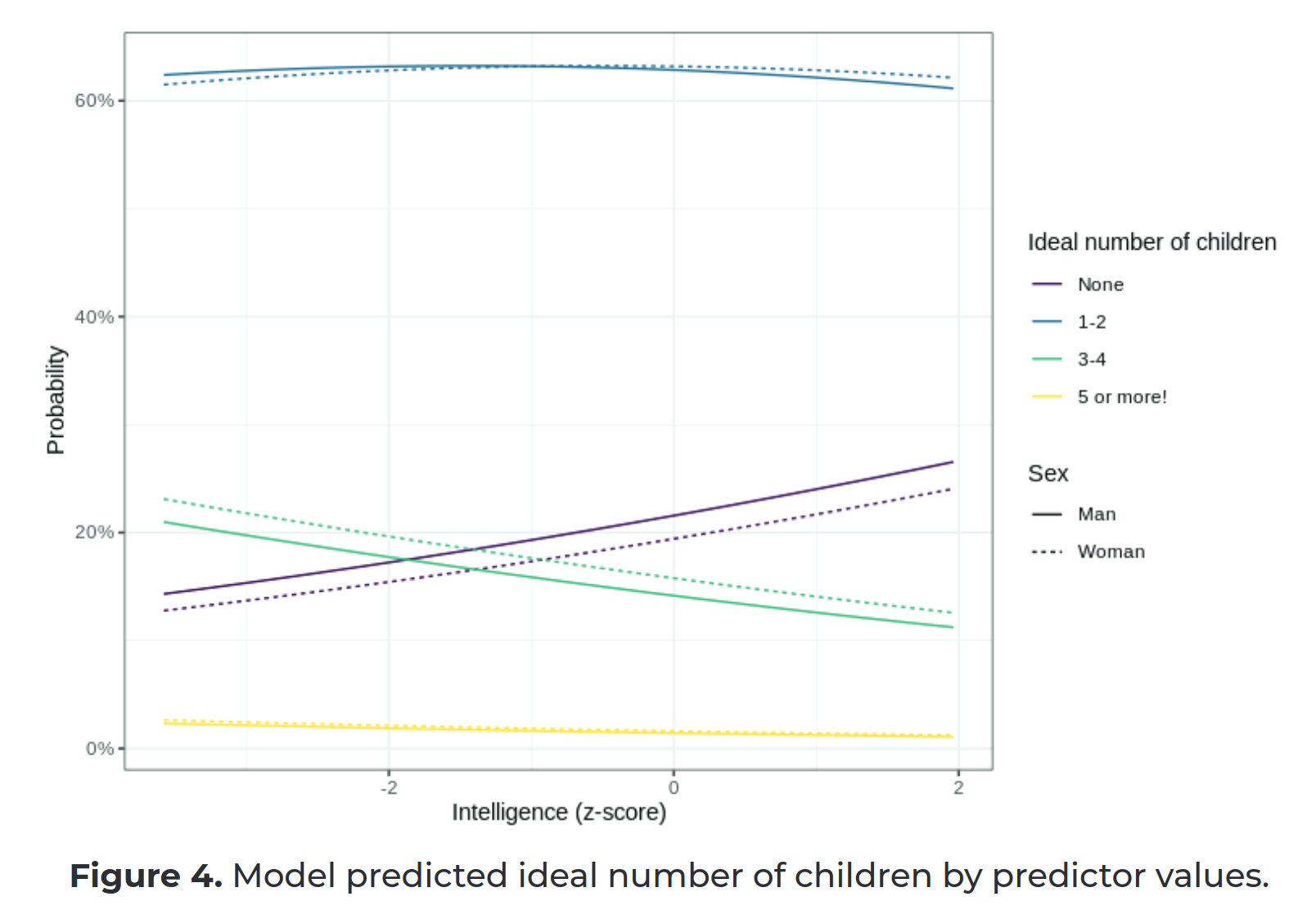
I have a new study out with Ed Dutton: Kirkegaard, E. O. W. & Dutton, E. Intelligence and Anti-Natalist Intentions on Dating Sites: An Analysis of the OKCupid Dataset. In…
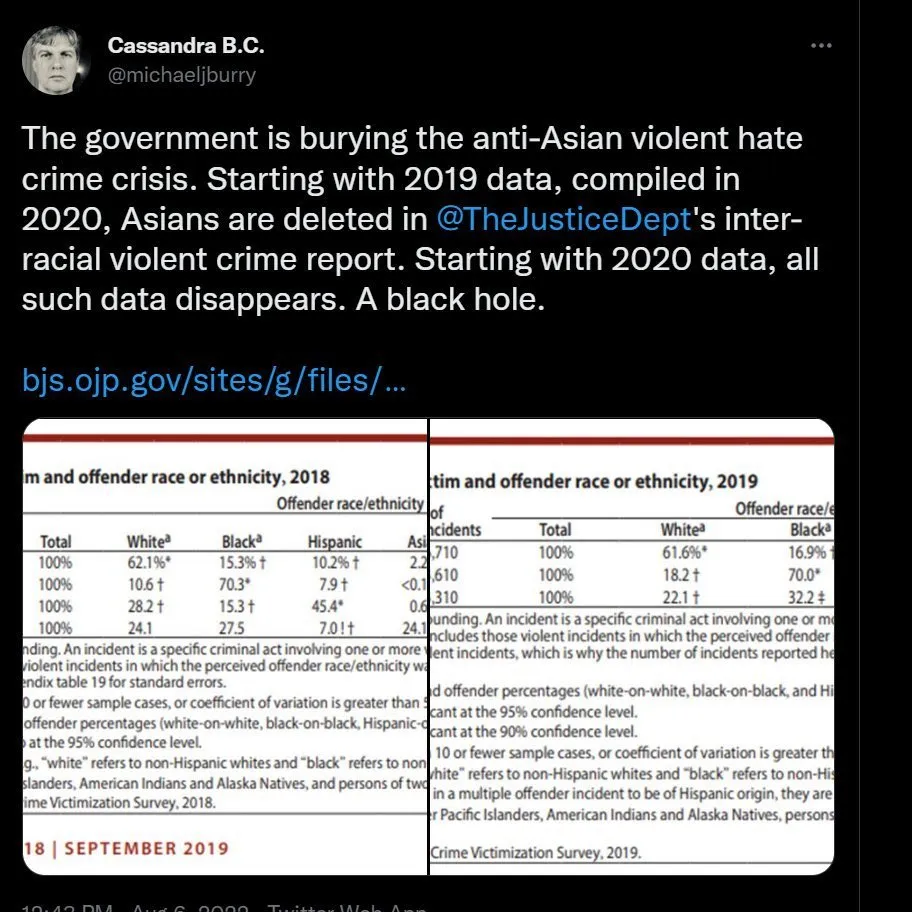
NBC: PBS: There's an endless number of govt and semi-govt websites already: Main non-profit: https://stopaapihate.org/ NYC government: https://www1.nyc.gov/site/cchr/community/stop-asian-hate.page United Nations: https://www.ohchr.org/en/stories/2022/03/if-we-stay-silent-violence-continues Of course, the conservatives are on the defensive in…

A few days ago I posted this deboonker meme on Twitter: I guess it got reposted somewhere by some woke people, since my feed has been filled with dumb replies…
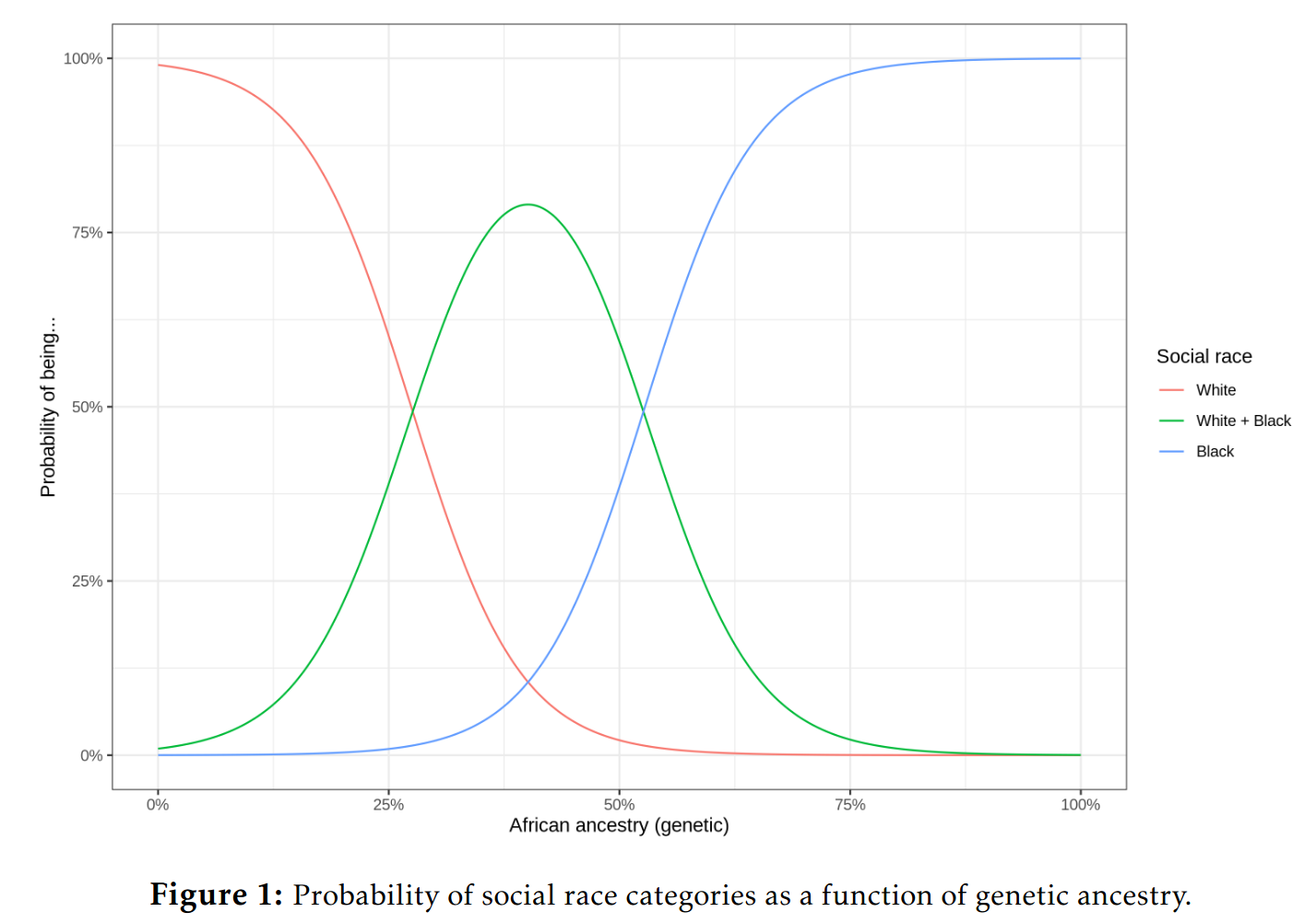
I've got a new paper out of some nontrivial interest to many. Kirkegaard, E. O. W. (2021). New paper out: Genetic ancestry and social race are nearly interchangeable. OpenPsych It…
A straightforward research idea: Compare the recognized count of subspecies (races/breeds/breeding populations/clusters etc.) with measures of genetic variation. The most obvious is the Fst but it's not an optimal metric.…