Bloggen Kulturradikalisme Smadrer Danmark har lavet en analyse som forsøger at kvantificere antallet og stigningen af muslimer i Danmark. Han har brugt en temmelig simpel metode:
- KSD har “kategoriseret et land som muslimsk, når islam er den mest udbredte religion”.
- Talt 100% af personer fra muslimske lande.
Det er dermed en approksimering som kun virker såfremt at fordelingen af muslim% er symmetrisk og at størrelsen på gruppen ikke har nogen sammenhæng med muslim%. Disse antagelser er nok ikke helt rigtige.
Det kan gøres bedre. Man kan finde muslim% i hjemlandet (via Pew Research) og gange det med antallet af personer i Danmark fra det land. Det kan man gøre over tid og dermed se ændringen. Der er dog stadig problemer:
1) Nogle personer bliver muslimer mens andre falder fra (konvertitter og dekonvertitter). Modellen giver kun rigtige tal hvis disse to grupper er lige store (evt. 0). Det er nok ikke rigtigt da jeg vil tro at der er langt flere dekonvertitter end konvertitter mht. Islam i Danmark (negativ bias).
2) DSTs tal underestimerer personer fra andre lande fordi de klassificerer personer som “dansk oprindelse” givet en relativ lempelig juridisk definition:
I statistikken kan befolkningen opdeles i tre grupper afhængig af deres oprindelse: Personer med dansk oprindelse, indvandrere og efterkommere.
En person har dansk oprindelse, hvis han eller hun har mindst én forælder, som både er dansk statsborger og født i Danmark. Hverken indvandrere eller efterkommere har én forælder, som både er dansk statsborger og født i Danmark. Forskellen mellem indvandrere og efterkommere er, at indvandrere er født i udlandet, mens efterkommere er født i Danmark.
I praksis betyder det at der er flere muslimer her end tallene viser (positiv bias).
Jeg har gjort det ovenstående og det gav følgende resultat:
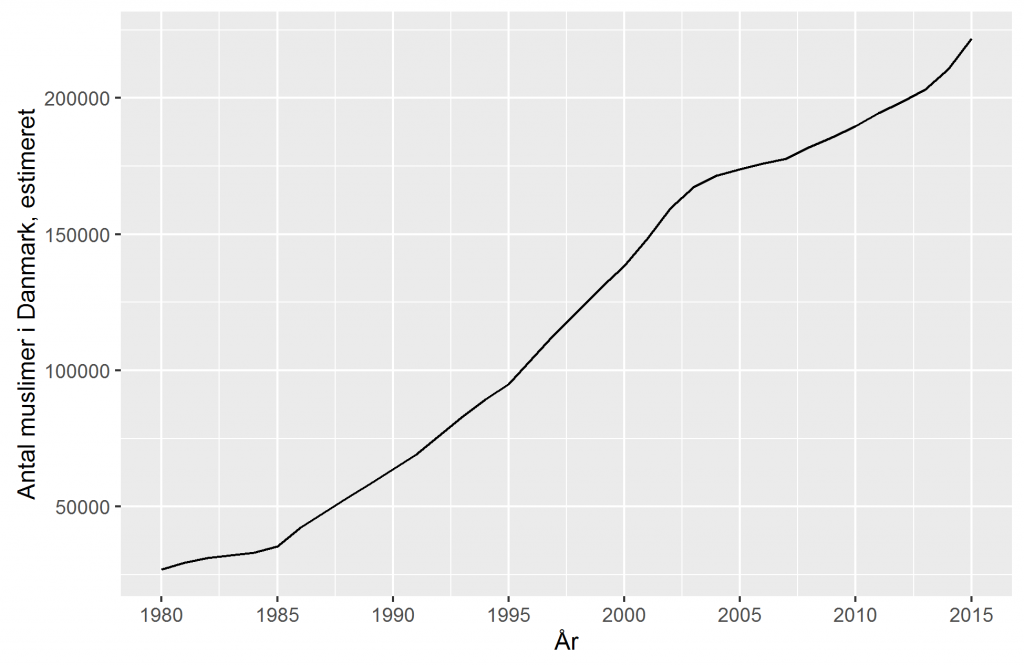
Hvis vi ser på 2005 til 2015 (som han gør), er tallene 173923.41 til 221908.34. En stigning på 27.6%. Hans estimat var 26%, så det er ca. det samme.
Der er en anden mulighed for at undersøge problemet. Man kan tælle antal personer med muslimske fornavne hvert år via DSTs side (“Hvor mange hedder”). De personer som har muslimske navne men som tælles som “dansk oprindelse” vil blive inkluderet der. Omvendt så vil personer som får et ikke-muslimsk navn ikke blive talt med. Det kan potentielt betyde at man undgår problemet med konvertitter og dekonvertitter som beskrevet ovenfor.
Det er nemt nok at skrabe dataene fra DSTs side med et lille script. Vi gjorde det i forbindelse med vores paper What is a good name? The S factor in Denmark at the name-level.
[Jeg poster scriptet her når jeg finder det.]
R kode
Jeg har brugt følgende R kode. Bemærk at det kræver at man allerede har megadatasettet. Det findes her: https://osf.io/zdcbq/files/
library(pacman)
p_load(devtools, kirkegaard, psych, plyr, stringr, dkstat, magrittr, reshape2, tidyr, ggplot2)
### estimates the number of muslims by using countries of origin and their Muslim%
# Denmark -----------------------------------------------------------------
#load data with persons from each country of origin by year
d_dk_FOLK2_meta = dst_meta(table = "FOLK2", lang = "en")
d_dk_FOLK2_meta$variables
#structure
str(d_dk_FOLK2_meta$values)
#fetch data
query = list(IELAND = d_dk_FOLK2_meta$values$IELAND$text, Tid = d_dk_FOLK2_meta$values$Tid$text)
d_dk_FOLK2 = dst_get_data(table = "FOLK2", lang = "en", meta_data = d_dk_FOLK2_meta, query = query)
#convert date to string with year
d_dk_FOLK2$TID %<>% format(format = "%Y")
#melt to wide
d_dk_FOLK2_wide = spread(d_dk_FOLK2, TID, value)
#remove empty countries (cleaning)
v_which_drop = apply(d_dk_FOLK2_wide, 1, function(x) {
x[-1] %>% as.numeric() %>% sum()
}) %>% equals(0)
d_dk_FOLK2_wide = d_dk_FOLK2_wide[!v_which_drop, ] #drop the ones we dont want
#abbreviate the names
d_dk_FOLK2_wide$abbrev = as_abbrev(d_dk_FOLK2_wide$IELAND)
#remove unrecognized names
d_dk_FOLK2_wide = d_dk_FOLK2_wide[!is.na(d_dk_FOLK2_wide$abbrev), ]
#merge rows of duplicates
d_dk_FOLK2_wide = merge_rows(d_dk_FOLK2_wide, key = "abbrev", func = sum)
#set rownames
rownames(d_dk_FOLK2_wide) = d_dk_FOLK2_wide$abbrev
#remove cols
d_dk_FOLK2_wide$IELAND = NULL
d_dk_FOLK2_wide$abbrev = NULL
#load muslim data
d_mega = read.csv("Megadataset_v2.0m.csv", sep = ";", row.names = 1)
#merge with muslim data, leftwards (keep only overlap with danish data)
d_dk_FOLK2_wide = merge_datasets(d_dk_FOLK2_wide, d_mega["IslamPewResearch2010"], join = "left")
#remove Denmark
d_dk_FOLK2_wide = d_dk_FOLK2_wide[!str_detect(rownames(d_dk_FOLK2_wide), "DNK"), ]
#calculate estimated muslims by cell
d_dk_est = apply(d_dk_FOLK2_wide, 1, function(row) {
v_len = length(row)
row[1:(v_len-1)] * row[v_len]
}) %>% t %>% as.data.frame()
#sum by year
d_dk_est_by_year = data.frame(number = colSums(d_dk_est, na.rm = T), year = as.numeric(colnames(d_dk_est)))
#plot
ggplot(d_dk_est_by_year, aes(year, number)) + geom_line() + ylab("Antal muslimer i Danmark, estimeret") + xlab("År") + scale_x_continuous(breaks = seq(1980, 2015, by = 5))
ggsave("figures/number_year.png")
#increase 2005-2015
v_temp = d_dk_est_by_year[c("2005", "2015"), "number"]
((v_temp[2] / v_temp[1]) - 1) %>% round(3)