Scraping with R
Although other languages are probably more suitable for web scraping (e.g. Python with Scrapy), R does have some scraping capabilities. Unsurprisingly, the ever awesome Hadley has written a great package for this: rvest. A simple tutorial and demonstration of it can be found here, which I the one I used. To do web scraping efficiently, one needs to be familiar with CSS selectors (this website is useful even if hated by some) and probably also regex (try this interactive tutorial).
What to scrape? & spatial autocorrelation
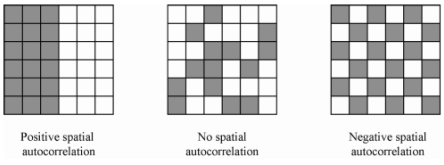
There are billions of things one could scrape and use for studies. I could spend all my time doing this if I didn’t have so many other projects that I need to work on and finish up. In this case I am in need of spatial data for the Admixture in the Americas project because a commenter told us to look into the problem of spatial autocorrelation. Essentially, spatial aurocorrelation is when your data concerns units that have some kind of location. This can be an actual location on Earth (or in space), or in some kind of abstract space such as phylogenetic space. Generally speaking, units that are closer to each other tend to be more similar (positive autocorrelation). I’ve read that this can make some predictors seem like they work when in fact they don’t. I haven’t seen an example of this yet, but I will try to see if I can simulate some data to confirm the problem (and maybe make a Shiny app?). A good rule of thumb for statistics is that if you can’t simulate data that show a given phenomenon, you don’t understand it well enough. The below visualization was offered in the R tutorial above.
Back to the topic. To control for spatial autocorrelation in an analysis, one needs some actual measures of each unit’s location. Since our units are countries and regions within countries, one needs latitude and longitude numbers. We looked around a bit and found some lists of these numbers. However, they did not cover all our units. We could only find data for US states and sovereign countries. Our dataset however also includes Mexican and Brazilian states, Colombian departments and various overseas territories.
Since we are really interested in the people living in these areas, the best measure would be the center of population, which is the demographic equivalent of center of mass in physics. This however requires having access to lots of population density information, which we could likewise not find. Theoretically, one could find a list of the largest cities of each unit and then calculate a weighted spherical geometrical central tendency of this and use that. This would probably be a good measure altho it is sensitive to differences in rates of urbanicity (proportion of people living in cities). One probably could obtain this information using Wikipedia and do the calculations, but it would be fairly time consuming and I suspect for fairly little gain (hence a new research proposal: for some units obtain both center of population and capital location data as well as some other data, compare results.). I decided on a simpler solution: finding the capital of each unit and using the location of that as a estimate. Because capitals are often located near the center of population for political reasons and because they are often the largest city as well, they should make okay approximations.
The actual scraping code
Below is the R code I wrote. Note that it is done fairly verbosely. One could create functions to make it simpler, but since I was just learning this stuff, I did it a simpler way. The code is commented, so you (and myself, when I read this post at some later point!) should be able to figure out what the code does.
library(pacman)
p_load(kirkegaard, stringr, psych, rvest)
# Colombian location scrape -----------------------------------------------
col_deps = html("https://en.wikipedia.org/wiki/Departments_of_Colombia")
#get names of deps and their capitals
dep_table = col_deps %>%
html_node(".wikitable") %>%
html_table(., fill = T)
#get links to each capital
link_caps = col_deps %>%
html_node(".wikitable") %>%
html_nodes("td:nth-child(3) a") %>%
html_attr(., "href")
#visit each capital page
for (cap in seq_along(link_caps)) {
print(str_c("fetching ", cap, " of ", length(link_caps)))
cap_page = html(str_c("https://en.wikipedia.org", link_caps[cap]))
link_geohack = cap_page %>%
html_node(".mergedbottomrow td a") %>%
html_attr("href")
#get geohack
geohack = html(str_c("https:", link_geohack))
#get lat and lon
latlon = geohack %>%
html_nodes(".geo span") %>%
html_text()
#save
dep_table[cap + 1, "lat"] = latlon[1]
dep_table[cap + 1, "lon"] = latlon[2]
}
#scrape the last one manually
dep_table[1, "lat"] = 4.598056
dep_table[1, "lon"] = -74.075833
#export
write_clipboard(dep_table)
# world capitals ----------------------------------------------------------
list_caps = html("https://en.wikipedia.org/wiki/List_of_national_capitals_in_alphabetical_order")
#get the table
table = list_caps %>%
html_node(".wikitable") %>%
html_table()
#get the capital links
cap_links = list_caps %>%
html_node(".wikitable") %>%
html_nodes("td:nth-child(1) a:nth-child(1)") %>%
html_attr("href")
#remove the wrong entry
cap_links = cap_links[-169]
#visit each capital
for (cap in seq_along(cap_links)) {
message(str_c("fetching ", cap, " out of ", length(cap_links)))
#check if already have data
if (!is.na(table[cap, "lat"])) {
msg = str_c("already have data. Skipping")
message(msg)
next
}
#fetch capital page
url = str_c("https://en.wikipedia.org", cap_links[cap])
message(url)
tried = try({
cap_page = html(url)
})
#no coordinates for that capital, skip
if (any(class(tried) == "try-error")) {
msg = str_c("error in html fetch ", cap, ". Skipping")
message(msg)
next
}
#get link to geohack
tried = try({
all_links = cap_page %>%
html_nodes("a") %>%
html_attr("href")
})
#is there a link to wmflabs?
if(!any(str_detect(all_links, "tools.wmflabs.org"), na.rm = T)) {
msg = str_c("No link to wmflabs anywhere. Skipping.")
message(msg)
next
}
#fetch url
which_url = which(str_detect(all_links, "tools.wmflabs.org"))[1] #get the first if there are multiple
url = str_c("https:", all_links[which_url])
#visit geohack
geohack = html(url)
#get lat and lon
latlon = geohack %>%
html_nodes(".geo span") %>%
html_text()
#save
table[cap, "lat"] = latlon[1]
table[cap, "lon"] = latlon[2]
msg = str_c("Success!")
message(msg)
}
# States of Mexico --------------------------------------------------------
url = "https://en.wikipedia.org/wiki/States_of_Mexico"
state_Mexico = html(url)
#get main table
Mex_table = state_Mexico %>%
html_node(".wikitable") %>%
html_table()
#links to capitals
cap_links = state_Mexico %>%
html_node(".wikitable") %>%
html_nodes("td:nth-child(4) a") %>%
html_attr("href")
#visit each state page
cap_pages = lapply(cap_links, function(x) {
html(str_c("https://en.wikipedia.org", x))
})
#fetch all the links for each page
cap_pages_links = lapply(cap_pages, function(x) {
html_nodes(x, "a") %>%
html_attr("href")
})
#fetch the geohack links
geohack_links = lapply(cap_pages_links, function(x) {
which_url = which(str_detect(x, "tools.wmflabs.org"))[1]
x[which_url]
})
#geohack pages
geohack_pages = lapply(geohack_links, function(x) {
url = str_c("https:", x)
html(url)
})
#lat and lon
latlon = ldply(geohack_pages, function(x) {
html_nodes(x, ".geo span") %>%
html_text()
})
colnames(latlon) = c("lat", "lon")
#add to df
Mex_table = cbind(Mex_table, latlon)
#export
write_clipboard(Mex_table, 99)
# US states ---------------------------------------------------------------
#main list
US_states_page = html("https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States")
#get the table
US_table = US_states_page %>%
html_node(".wikitable") %>%
html_table()
#get links to the state capitals
cap_links = US_states_page %>%
html_node(".wikitable") %>%
html_nodes("td:nth-child(3) a") %>%
html_attr("href")
#fetch pages
cap_pages = lapply(cap_links, function(x) {
url = str_c("https://en.wikipedia.org", x)
html(url)
})
#fetch geohack pages
geohacks = lapply(cap_pages, function(x) {
#find links
links = html_nodes(x, "a") %>%
html_attr("href")
#find the right one
which_link = which(str_detect(links, "tools.wmflabs.org"))
link = links[which_link][1]
url = str_c("https:", link)
html(url)
})
#fetch latlon
latlon = ldply(geohacks, function(x) {
html_nodes(x, ".geo span") %>%
html_text()
})
colnames(latlon) = c("lat", "lon")
#add to df
US_table = cbind(US_table, latlon)
#export
write_clipboard(US_table, 99)
# Brazil ------------------------------------------------------------------
#the main page we get info from
states_page = html("https://en.wikipedia.org/wiki/States_of_Brazil")
#get the table into R
BRA_table = states_page %>%
html_node(".wikitable") %>%
html_table
#get links to state caps
cap_links = states_page %>%
html_node(".wikitable") %>%
html_nodes("td:nth-child(4) a") %>%
html_attr("href")
#get each cap page
cap_pages = lapply(cap_links, function(x) {
url = str_c("https://en.wikipedia.org", x)
x = html(url)
})
#fetch geohack pages
geohacks = lapply(cap_pages, function(x) {
#find links
links = html_nodes(x, "a") %>%
html_attr("href")
#find the right one
which_link = which(str_detect(links, "tools.wmflabs.org"))
link = links[which_link][1]
url = str_c("https:", link)
html(url)
})
#fetch latlon
latlon = ldply(geohacks, function(x) {
html_nodes(x, ".geo span") %>%
html_text()
})
colnames(latlon) = c("lat", "lon")
BRA_table$lat = latlon[[1]]
BRA_table$lon = latlon[[2]]
write_clipboard(BRA_table)
write_clipboard(latlon)
# clean up the tables and merge ---------------------------------------------------------
#instead of merging into mega 5 times, we first clean up each dataset and then marge once
##Colombia
#rename Amazon because a state with the identical name exists for Brazil
dep_table[2, 2] = "Amazonas (COL)"
#abbreviations
COL_abbrev = as_abbrev(dep_table$Department)
#subset to the cols we want
col_clean = dep_table[c(2, 3, 7, 8)]
#rownames
rownames(col_clean) = COL_abbrev
##World
world_clean = table[c(2, 1, 4, 5)]
#some have multiple listed capitals, we just pick the first one mentioned
world_clean$City %<>% str_extract("[^\\(]*") %>% #get all text before parenthesis
str_trim #trim whitespace
#remove comments from country names
world_clean$Country %<>%
str_replace_all("\\[.*?\\]", "") %>%
str_trim
#abbreviations
rownames(world_clean) = as_abbrev(world_clean$Country)
##Mexico
#subset cols
MEX_clean = Mex_table[c(1, 4, 10, 11)]
#remove numbers from the names
MEX_clean$State = MEX_clean$State %>% str_replace_all("\\d", "")
#abbrevs
rownames(MEX_clean) = MEX_clean$State %>% as_abbrev
##Brazil
BRA_clean = BRA_table[c(2, 4, 16, 17)]
#add identifiers to ambiguous names
BRA_clean[4, "State"] = "Amazonas (BRA)"
BRA_clean[7, "State"] = "Distrito Federal (BRA)"
#abbrevs
rownames(BRA_clean) = BRA_clean$State %>% as_abbrev
##USA
USA_clean = US_table[c(1, 3, 11, 12)]
#clean names
USA_clean$State = USA_clean$State %>% str_replace_all("\\[.*?\\]", "")
#abbevs
rownames(USA_clean) = USA_clean$State %>% as_abbrev(., georgia = "s")
# merge into megadataset --------------------------------------------------
#give them the same colnames
colnames(col_clean) = colnames(MEX_clean) = colnames(BRA_clean) = colnames(USA_clean) = colnames(world_clean) = c("Names2", "Capital", "lat", "lon")
#stack by bow
all_clean = rbind(col_clean, MEX_clean, BRA_clean, USA_clean, world_clean)
#load mega
mega = read_mega("Megadataset_v2.0l.csv")
#merge into mega
mega2 = merge_datasets(mega, all_clean, 1)
#save
write_mega(mega2, "Megadataset_v2.0m.csv")