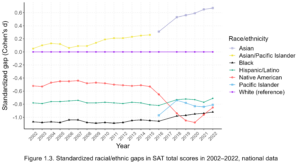
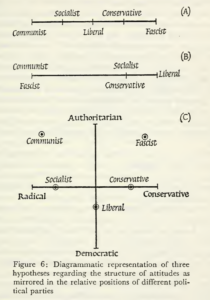
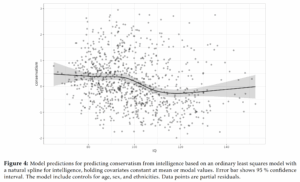
And I’m not even referring to the latest results from any Pifferian methods (e.g. this).
Currently there are many large GWAS for IQ/educational attainment/other g proxies that have data gathered from US citizens. Some of the subjects are African Americans (AAs). AAs are actually mixed ancestry with about 15-25% European ancestry (depending on sample). The simplest genetic model (without shenanigans from assortative mating or outbreeding) predicts a linear relationship between amount of Euro ancestry in AAs and higher IQ/g proxy. This is easy to check, so easy that quite a lot of science bloggers could easily do this in one day if only the data were available to them. The researchers who did the GWAS are surely aware of this method.
Now, we have not seen any such study published, either positive or negative. Surely, there are huge benefits to being the first author to publish a study that almost conclusively disproves the genetic model for AAs. Researchers with access to the data have a strong incentive to publish such a study. They will be seen as heroes (“the scientist who disproved racism”) and surely get lots of funding and many talks etc. Since they haven’t published it, we can infer that the data does not support the politically favorable non-genetic model, but instead supports the genetic model. Probably the authors with access to the data do not want to go down in history as the ones who finally proved ‘racism’. So, instead of settling the issue, they just sit on the data. Self-censorship.
In any case, useful data for testing this are gonna leak sooner or later. It can’t take many years. An admixture study for diabetes and African ancestry came very close to proving the genetic model since they included socioeconomic (SES) measures as a control. Their S2 table shows a clear relationship between higher SES and less African ancestry. Of course, a stubborn person will regard this as simply being in line with a discrimination model based on visual cues.