- Pearl, J., & Mackenzie, D. (2018). The book of why: the new science of cause and effect. Basic Books.

This is an interesting but annoying book. The basic pattern of the book goes like this:
- Scientists used to totally not know anything proper about how to do X or think about X.
- But no worries, then I, the Great Pearl (+ students), came along and invented Causal Diagrams and some equations, and now the field has been revolutionized.
The book contains basically no real life applications of these methods, and any working scientist should scoff at this. A particularly concise example toward the end of the book:
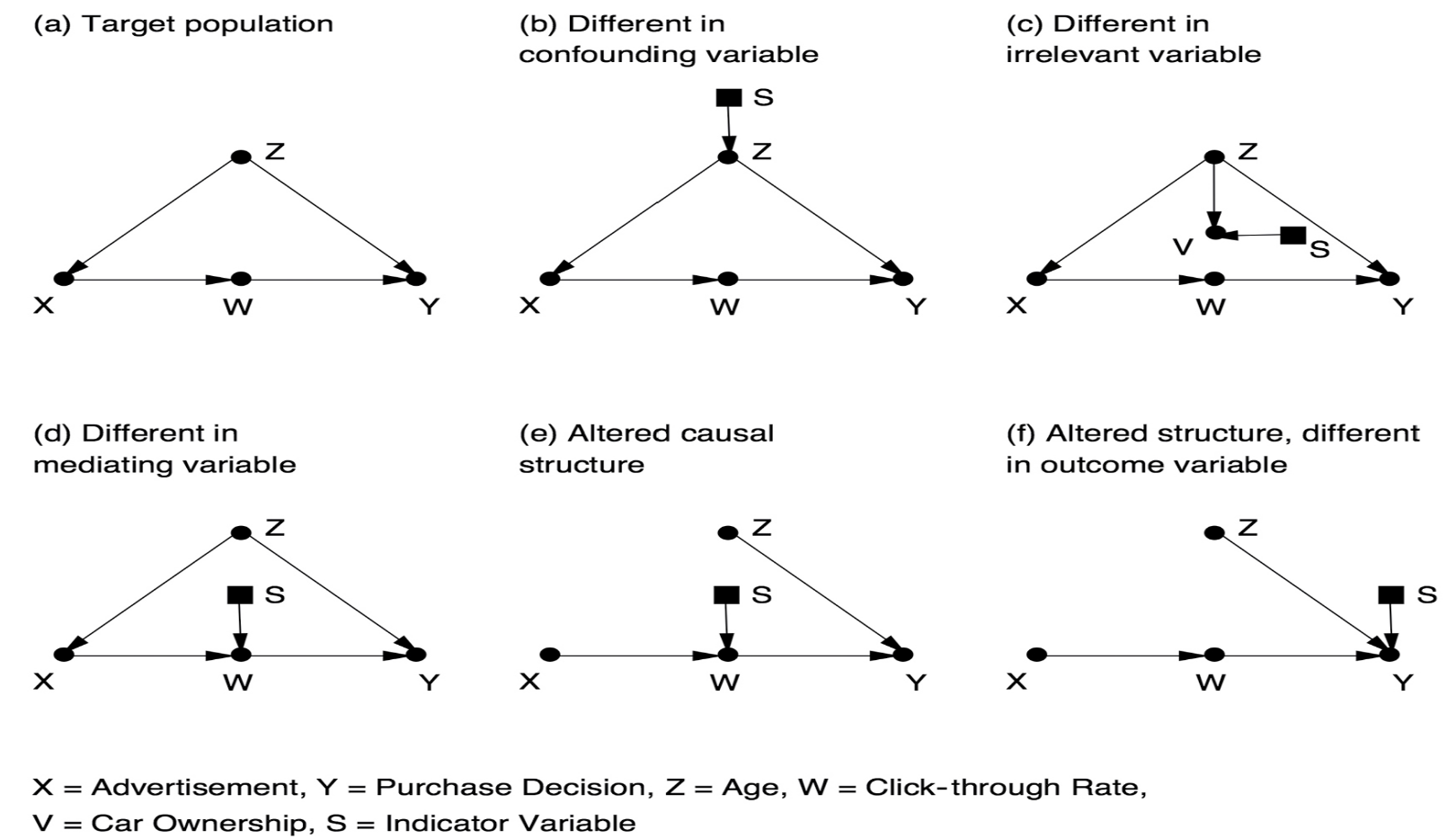
Elias Bareinboim [i.e. Pearl’s student] has managed to do the same thing for the problem of transportability [Pearl’s term for validity generalization] that Ilya Shpitser did for the problem of interventions. He has developed an algorithm that can automatically determine for you whether the effect you are seeking is transportable, using graphical criteria alone. In other words, it can tell you whether the required separation of S from the do-operators can be accomplished or not.
Bareinboim’s results are exciting because they change what was formerly seen as a threat to validity into an opportunity to leverage the many studies in which participation cannot be mandated and where we therefore cannot guarantee that the study population would be the same as the population of interest. Instead of seeing the difference between populations as a threat to the “external validity” of a study, we now have a methodology for establishing validity in situations that would have appeared hopeless before. It is precisely because we live in the era of Big Data that we have access to information on many studies and on many of the auxiliary variables (like Z and W) that will allow us to transport results from one population to another.
I will mention in passing that Bareinboim has also proved analogous results for another problem that has long bedeviled statisticians: selection bias. This kind of bias occurs when the sample group being studied differs from the target population in some relevant way. This sounds a lot like the transportability problem—and it is, except for one very important modification: instead of drawing an arrow from the indicator variable S to the affected variable, we draw the arrow toward S. We can think of S as standing for “selection” (into the study). For example, if our study observes only hospitalized patients, as in the Berkson bias example, we would draw an arrow from Hospitalization to S, indicating that hospitalization is a cause of selection for our study. In Chapter 6 we saw this situation only as a threat to the validity of our study. But now, we can look at it as an opportunity. If we understand the mechanism by which we recruit subjects for the study, we can recover from bias by collecting data on the right set of deconfounders and using an appropriate reweighting or adjustment formula. Bareinboim’s work allows us to exploit causal logic and Big Data to perform miracles that were previously inconceivable.
Words like “miracles” and “inconceivable” are rare in scientific discourse, and the reader may wonder if I am being a little too enthusiastic. But I use them for a good reason. The concept of external validity as a threat to experimental science has been around for at least half a century, ever since Donald Campbell and Julian Stanley recognized and defined the term in 1963. I have talked to dozens of experts and prominent authors who have written about this topic. To my amazement, not one of them was able to tackle any of the toy problems presented in Figure 10.2. I call them “toy problems” because they are easy to describe, easy to solve, and easy to verify if a given solution is correct.At present, the culture of “external validity” is totally preoccupied with listing and categorizing the threats to validity rather than fighting them. It is in fact so paralyzed by threats that it looks with suspicion and disbelief on the very idea that threats can be disarmed. The experts, who are novices to graphical models, find it easier to configure additional threats than to attempt to remedy any one of them. Language like “miracles,” so I hope, should jolt my colleagues into looking at such problems as intellectual challenges rather than reasons for despair.
I wish that I could present the reader with successful case studies of a complex transportability task and recovery from selection bias, but the techniques are still too new to have penetrated into general usage. I am very confident, though, that researchers will discover the power of Bareinboim’s algorithms before long, and then external validity, like confounding before it, will cease to have its mystical and terrifying power.
Alright then! For those who are wondering what he is talking about. He is merely talking about the conditions under which we can extrapolate the validity of some effect in one population to another that might differ in some characteristics. In Pearl’s world, this means that we just draw up a simple Causal Diagram for it, and then we figure out how to modify the effect size given changes to this diagram. What his student did is come up with an algorithm that can handle arbitrary changes to this diagram. Of course, in the real world, we don’t have any simple causal diagrams everybody agrees on, and neither do we know how they might differ between one population and another. So these methods, though cool, are inapplicable to the real world.
Pearl himself takes some pride in this otherworldly approach:
In Chapter 3 I wrote about some of the reasons for this slow progress. In the 1970s and early 1980s, artificial intelligence research was hampered by its focus on rule-based systems. But rule-based systems proved to be on the wrong track. They were very brittle. Any slight change to their working assumptions required that they be rewritten. They could not cope well with uncertainty or with contradictory data. Finally, they were not scientifically transparent; you could not prove mathematically that they would behave in a certain way, and you could not pinpoint exactly what needed repair when they didn’t. Not all AI researchers objected to the lack of transparency. The field at the time was divided into “neats” (who wanted transparent systems with guarantees of behavior) and “scruffies” (who just wanted something that worked). I was always a “neat.”
I was lucky to come along at a time when the field was ready for a new approach. Bayesian networks were probabilistic; they could cope with a world full of conflicting and uncertain data. Unlike the rule-based systems, they were modular and easily implemented on a distributed computing platform, which made them fast. Finally, as was important to me (and other “neats”), Bayesian networks dealt with probabilities in a mathematically sound way. This guaranteed that if anything went wrong, the bug was in the program, not in our thinking.
Even with all these advantages, Bayesian networks still could not understand causes and effects. By design, in a Bayesian network, information flows in both directions, causal and diagnostic: smoke increases the likelihood of fire, and fire increases the likelihood of smoke. In fact, a Bayesian network can’t even tell what the “causal direction” is. The pursuit of this anomaly—this wonderful anomaly, as it turned out—drew me away from the field of machine learning and toward the study of causation. I could not reconcile myself to the idea that future robots would not be able to communicate with us in our native language of cause and effect. Once in causality land, I was naturally drawn toward the vast spectrum of other sciences where causal asymmetry is of the utmost importance.
So, for the past twenty-five years, I have been somewhat of an expatriate from the land of automated reasoning and machine learning. Nevertheless, from my distant vantage point I can still see the current trends and fashions.In recent years, the most remarkable progress in AI has taken place in an area called “deep learning,” which uses methods like convolutional neural networks. These networks do not follow the rules of probability; they do not deal with uncertainty in a rigorous or transparent way. Still less do they incorporate any explicit representation of the environment in which they operate. Instead, the architecture of the network is left free to evolve on its own. When finished training a new network, the programmer has no idea what computations it is performing or why they work. If the network fails, she has no idea how to fix it.
Perhaps the prototypical example is AlphaGo, a convolutional neural-network-based program that plays the ancient Asian game of Go, developed by DeepMind, a subsidiary of Google. Among human games of perfect information, Go had always been considered the toughest nut for AI. Though computers conquered humans in chess in 1997, they were not considered a match even for the lowest-level professional Go players as recently as 2015. The Go community thought that computers were still a decade or more away from giving humans a real battle.
That changed almost overnight with the advent of AlphaGo. Most Go players first heard about the program in late 2015, when it trounced a human professional 5–0. In March 2016, AlphaGo defeated Lee Sedol, for years considered the strongest human player, 4–1. A few months later it played sixty online games against top human players without losing a single one, and in 2017 it was officially retired after beating the current world champion, Ke Jie. The one game it lost to Sedol is the only one it will ever lose to a human.
All of this is exciting, and the results leave no doubt: deep learning works for certain tasks. But it is the antithesis of transparency. Even AlphaGo’s programmers cannot tell you why the program plays so well. They knew from experience that deep networks have been successful at tasks in computer vision and speech recognition. Nevertheless, our understanding of deep learning is completely empirical and comes with no guarantees. The AlphaGo team could not have predicted at the outset that the program would beat the best human in a year, or two, or five. They simply experimented, and it did.
Some people will argue that transparency is not really needed. We do not understand in detail how the human brain works, and yet it runs well, and we forgive our meager understanding. So, they argue, why not unleash deep-learning systems and create a new kind of intelligence without understanding how it works? I cannot say they are wrong. The “scruffies,” at this moment in time, have taken the lead. Nevertheless, I can say that I personally don’t like opaque systems, and that is why I do not choose to do research on them.
I still want to give this book 4/5 stars because it certainly is informative about how Pearl works, and Pearl is an interesting guy and no doubt has had a big impact. The book should thus be seen as an inadvertent semi-autobiography of Pearl. And of course, it presents a lot of interesting information about how one can think in simplified causal pathways, even though these aren’t usually so useful in practice.
