I recently posted a book review of Garett Jones’ 10% less Democracy. My main beef with the book is that it relies on lots of studies with dubious p values, suggesting extensive statistical cheating or selective citations by Jones. Jones however doesn’t back down. On the Ideas Sleep Furiously show, he said:
Matt: What do you think about P values? So this this questioner went through a few of the studies in 10% Less Democracy. He said, actually a few of these studies, he didn’t think the P values were high enough. Do you think that what what is your take
Jones: generally on on on that type of 1000%? McCloskey, Deirdre McCloskey
Matt: do you want to explain that to me?
Jones: P values are overrated. Obsessing over P values is to put a joke on it, the standard error of regressions. And it’s going to be common for P values to be low when we’re looking at small samples and moderate correlations. I mean, you can just go online and look at any P value calculator, but when you see something showing up in 10-20 different studies using bunch of different measures, a bunch of different proxies for your underlying variables of interest, that’s a sign that your real P value is a lot higher. So, you know, and in different less democracy in particular, we know that for instance the value of central bank independence having basically having central banks run by oligarchs doesn’t stand up to a lot of statistical significance tests. But when you run when you run normal regressions, but whenever you look at a case study and you’re like one country switch from um democratically run central banks to insider run central banks, the inflation rate falls. So there are different kinds of knowing and different kinds of learning and that can complement each other. So before and after case studies can tell us a lot that a bunch of fancy state of regressions can tell us. So yeah, obsession over asterisks is a huge mistake, both for good and ill. It’s weird that people, I mean it’s disappointing because it’s unsurprising that people p hack because editors and reviewers are lazy and they assess over that, but we can learn a lot from studies from multiple studies in the same field that have P equal .06.
I will bite the bullet: I think case studies should also be evaluated on statistical grounds because I’m a 1000% Lord Kelvinist:
“When you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind.”
But that aside, Jones is talking like it’s 2010. The idea in social science used to be that constructive replications are a sign of a healthy claim. It makes sense intuitively. If a claim generates some broad set of predictions tested using different proxies or measures, and in different datasets, and they all agree in one direction, this is a sign of a true claim even if each of the findings are statistically weak. However, in the case where these studies are almost all p = .03 type results this is not actually a good sign, and it’s even worse when there’s no direct replications to see. This is a very bad sign. Lack of direct replications can mean publication bias — the studies without positive findings weren’t published at all. The fact that they all use different methods and datasets suggests not generality but p-hacking: trying out a lot of different methods and datasets until you get what you want. Jones quote is saying the same things that the early defenders against the replication crisis said, and they look very foolish in hindsight. Check the results of any of the big replication studies if you aren’t familiar with them.
I don’t know why Jones hasn’t learned from the errors of psychologists. It is certainly not that economists are beyond such things. In fact, economists seem the most adept at this according to a new meta-analysis:
- Bartoš, F., Maier, M., Wagenmakers, E. J., Nippold, F., Doucouliagos, H., Ioannidis, J., … & Stanley, T. D. (2022). Footprint of publication selection bias on meta-analyses in medicine, economics, and psychology. arXiv preprint arXiv:2208.12334.
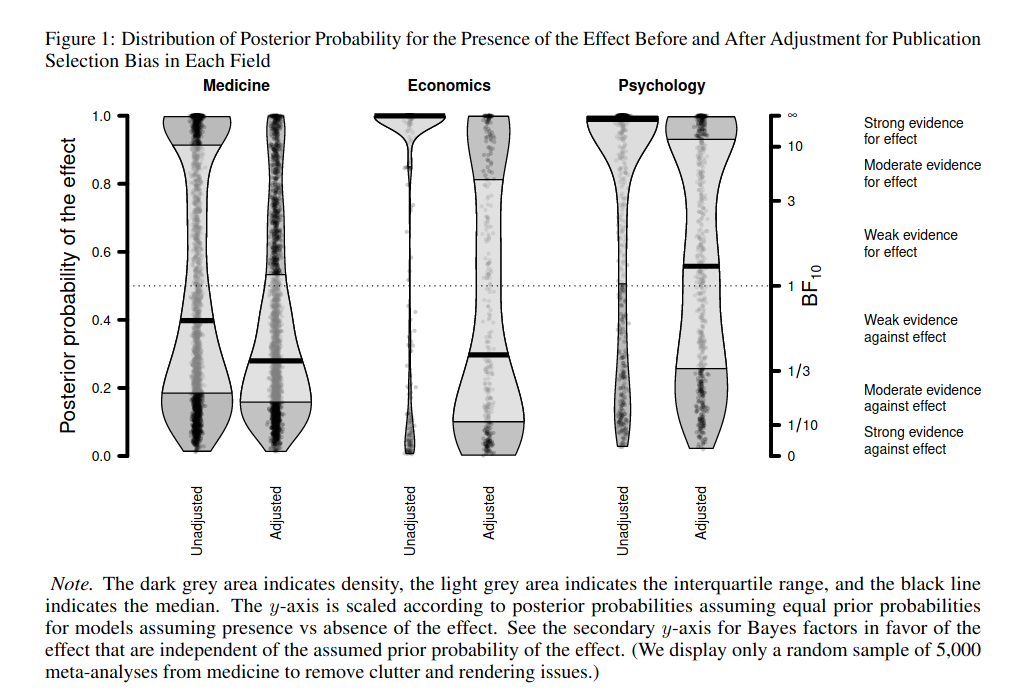
Publication selection bias undermines the systematic accumulation of evidence. To assess the extent of this problem, we survey over 26,000 meta-analyses containing more than 800,000 effect size estimates from medicine, economics, and psychology. Our results indicate that meta-analyses in economics are the most severely contaminated by publication selection bias, closely followed by meta-analyses in psychology, whereas meta-analyses in medicine are contaminated the least. The median probability of the presence of an effect in economics decreased from 99.9% to 29.7% after adjusting for publication selection bias. This reduction was slightly lower in psychology (98.9% → 55.7%) and considerably lower in medicine (38.0% → 27.5%). The high prevalence of publication selection bias underscores the importance of adopting better research practices such as preregistration and registered reports.
Visually:
How did the authors estimate the true effect sizes?
We use a state-of-the-art PSB detection and correction technique RoBMA-PSMA [ 29, 30]. RoBMA combines the best of two well performing methods: selection models [ 31 ] and PET-PEESE [32], through Bayesian model-averaging and achieves better performance in both simulation studies and real data examples than either of the methods alone [30].
RoBMA uses Bayesian model-averaging to combine Bayesian implementation of selection models and PET-PEESE adjustments for PSB. In other words, RoBMA combines these methods based on their predictive adequacy, such that models that predict well have a large impact on the inference. Predictive adequacy is also a yardstick to compare different subsets of models and methods directly. In that way, we can evaluate the evidence in favor or against the hypothesis of PSB without the need to commit to a single specific estimation method, e.g., [33].
In addition, RoBMA incorporates both models based on the correlation between effect sizes and standard errors (i.e., PET-PEESE) and those based on selection for significance (i.e., 3PSM). This allows us to compare these different types of models with each other and to use the strength of each to calculate a corrected estimate.
So according to this three-way comparison, economist meta-analyses show the most bias from bad statistical practices. In other words, they cheat harder than psychologists and doctors. By their estimate, if an economics meta-analysis — the gold standard for many years — claims there is an effect, there is only about 30% that’s true, and if so, it’s going to be inflated a lot. Consider how crazy that is. A meta-analysis if a collection and quantitative summary of all prior research on some research question. The theory is that when averaging over studies which use somewhat different methods, we will average out some noise and get an overall estimate of phenomenon of interest. But in reality, it seems that because there is so much bias in how studies get done, written up, and published (if they do!), doing a meta-analysis actually ends up just aggregating a lot of bias from this process of statistical cheating. Fortunately, there are patterns in the data when researchers do this stuff, so one can do a kind of post-mortem and figure out when not to trust a given meta-analysis’ results.
But there’s a lot more of this kind of research about economics in particular showing the prevalence of cheating:
- Ioannidis, J. P., Stanley, T. D., & Doucouliagos, H. (2017). The power of bias in economics research. The Economic Journal, Volume 127, Issue 605, October 2017, Pages F236–F265, https://doi.org/10.1111/ecoj.12461
We investigate two critical dimensions of the credibility of empirical economics research: statistical power and bias. We survey 159 empirical economics literatures that draw upon 64,076 estimates of economic parameters reported in more than 6,700 empirical studies. Half of the research areas have nearly 90% of their results under‐powered. The median statistical power is 18%, or less. A simple weighted average of those reported results that are adequately powered (power ≥ 80%) reveals that nearly 80% of the reported effects in these empirical economics literatures are exaggerated; typically, by a factor of two and with one‐third inflated by a factor of four or more.
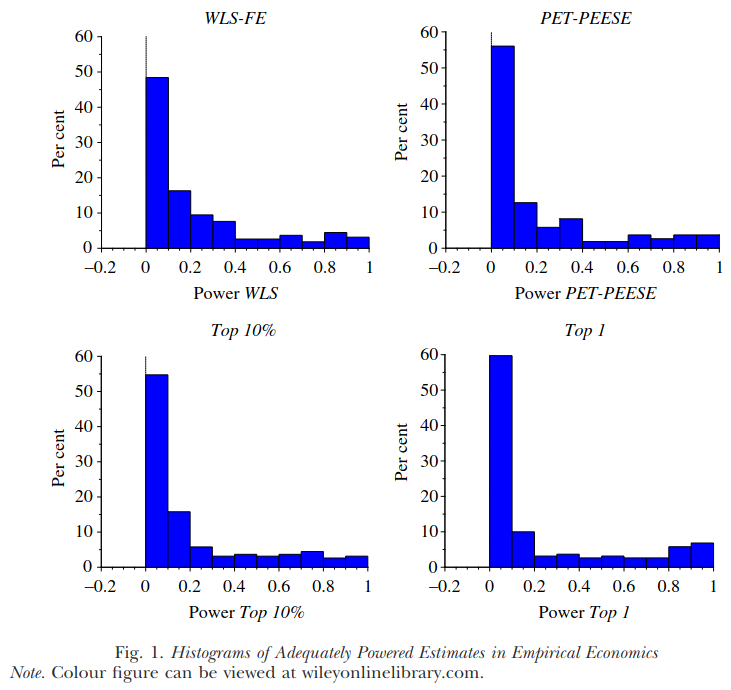
Power levels are abysmal. Almost all the research is statistically incapable of answering the questions the authors are trying to investigate with the data. This is just another way to say that the p values are very often in the dubious area. Another study shows us that this differs by causal identification method too:
-
Brodeur, A., Cook, N., & Heyes, A. (2020). Methods matter: P-hacking and publication bias in causal analysis in economics. American Economic Review, 110(11), 3634-60.
The credibility revolution in economics has promoted causal identification using randomized control trials (RCT), difference-in-differences (DID), instrumental variables (IV) and regression discontinuity design (RDD). Applying multiple approaches to over 21,000 hypothesis tests published in 25 leading economics journals, we find that the extent of p-hacking and publication bias varies greatly by method. IV (and to a lesser extent DID) are particularly problematic. We find no evidence that (i) papers published in the Top 5 journals are different to others; (ii) the journal “revise and resubmit” process mitigates the problem; (iii) things are improving through time.
It looks like this:
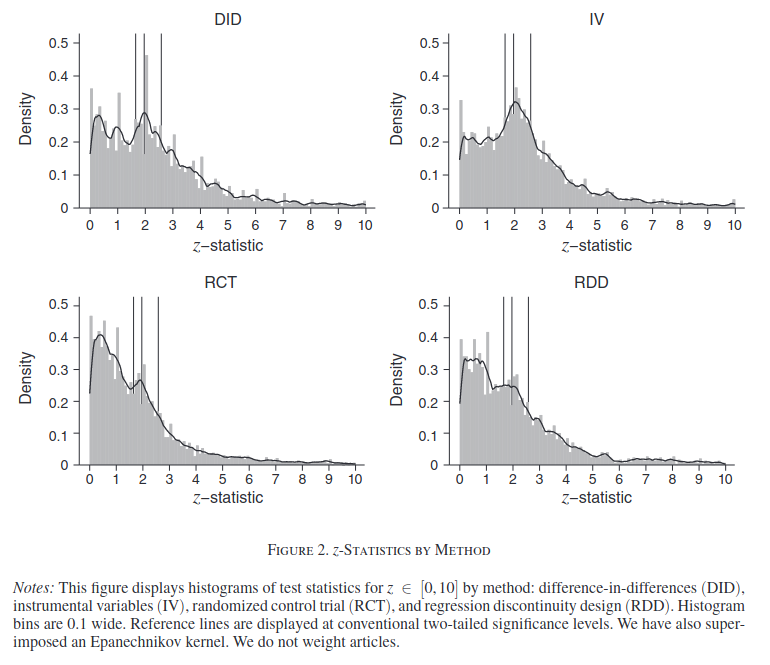
Any spike of p values around 2 is bad, as this corresponds to p = .05 cutoff and indicates hacking (there can be spikes around the z values that correspond to 10% and 1% as well). IV shows extreme amounts of hacking, basically you shouldn’t trust it unless p < .001, DID shows a lot of hacking, maybe p < .005 is enough. RDD shows less hacking, so maybe p < .01 is enough to pay attention, which is also the standard I would use for RCT’s.
Look, I want to say nice things about economists. Most social scientists aren’t even trying to get at causality. Their method consists of just assuming that parental traits cause children’s behavior, whereas this could of course be do to any number of confounders, chiefly genetic ones that aren’t even mentioned. Social scientists, though, have come around on genetics in large numbers. There’s no going back now to the time of only blank slate and where results could be denied by blaming Cyril Burt for fraud. There’s 100,000s of twins in various registers and 1000+ of studies on these. Still, overall social scientists shirk at causal talk and their papers are often causally uninterpretable. Economists deserve credit for thinking about causality and methods for getting at it a long time before most people in the other social sciences were doing this. The various causal identification methods were generally spearheaded by economists. And it is true, when appropriately used, IV, DID, and RDD are powerful methods of estimating causality. But in practice, these methods are very flexible in their execution, so this just ends up with people overfitting their data by trying a lot of method variation until they get the desired p = .04. No one working in machine learning would be particularly surprised by this kind of outcome. No test set? Well, good luck with your findings!
So what I am really saying: