-
Baumeister, H., & Montag, C. (Eds.). (2019). Digital Phenotyping and Mobile Sensing: New Developments in Psychoinformatics. Springer Nature.
This book offers a snapshot of cutting-edge applications of mobile sensing for digital phenotyping in the field of Psychoinformatics. The respective chapters, written by authoritative researchers, cover various aspects related to the use of these technologies in health, education, and cognitive science research. They share insights both into established applications of mobile sensing (such as predicting personality or mental and behavioral health on the basis of smartphone usage patterns) and emerging trends. Machine learning and deep learning approaches are discussed, and important considerations regarding privacy risks and ethical issues are assessed.
In addition to essential background information on various technologies and theoretical methods, the book also presents relevant case studies and good scientific practices, thus addressing researchers and professionals alike. To cite Thomas R. Insel, who wrote the foreword to this book: “Patients will only use digital phenotyping if it solves a problem, perhaps a digital smoke alarm that can prevent a crisis. Providers will only use digital phenotyping if it fits seamlessly into their crowded workflow. If we can earn public trust, there is every reason to be excited about this new field. Suddenly, studying human behavior at scale, over months and years, is feasible.”
I try to read diverse books to get good ideas. This is one such book I read I feel really was worth it. Because I am short on time, I will mainly just post the abstracts of the individual chapters. This is an edited book.
Chapter 3 Computerized Facial Emotion Expression Recognition
Mattis Geiger and Oliver Wilhelm
Facial emotion expressions are an important gateway for studying human emotions. For many decades, this research was limited to human ratings of arousal and valence of emotional expressions. Such ratings are very time-consuming and have limited objectivity due to rater biases. By exploiting improvements in machine learn- ing, the demand for a swifter and more objective method to assess facial emotional expressions was met by a plethora of software. These novel approaches are based on theories of human perception and emotion and their algorithms are often trained with massive and almost-generalizable data bases. However, they still face limita- tions such as 2D recognition and cultural biases. Nevertheless, the accuracy of computerized emotion recognition software has surpassed human raters in many cases. Consequently, such software has become instrumental in psychological research and has delivered remarkable findings, e.g. on human emotional abilities and dynamic expressions. Furthermore, recent developments for mobile devices have introduced such software into daily life, allowing for the immediate and ambulatory assessment of facial emotion expression. These trends provide intriguing new opportunities for studying human emotions, such as photograph-based experience sampling, incidental or implicit data recording in interventions, and many more.

Chapter 4 An Overview on Doing Psychodiagnostics in Personality Psychology and Tracking Physical Activity via Smartphones
Rayna Sariyska and Christian Montag
The aim of this chapter is to introduce and describe how digital technologies, in particular smartphones, can be used in research in two areas, namely (i) to conduct personality assessment and (ii) to assess and promote physical activity. This area of research is very timely, because it demonstrates how the ubiquitously avail- able smartphone technology—next to its known advantages in day-to-day life—can provide insights into many variables, relevant for psycho-social research, beyond what is possible within the classic spectrum of self-report inventories and laboratory experiments. The present chapter gives a brief overview on first empirical studies and discusses both opportunities and challenges in this rapidly developing research area.
–
The link between extraversion and call variables, reported by Chittaranjan et al. (2013) was supported in two independent studies by Montag et al. (2014, 2019). In those two studies participants from Germany were tested using an application called Menthal for the duration of four weeks and the NEO-Five-Factor Inventory (NEO- FFI) in Montag et al. (2014), and another smartphone application called Insights for the duration of 12 days and the Trait Self-Description Inventory (TSDI, see Olaru et al. 2015) to assess personality in Montag et al. (2019). Nearly all investigated call variables (e.g. number of calls, duration of calls) were positively linked to extraversion. Conscientiousness was positively linked to the duration of calls in Montag et al. (2014) and neuroticism was negatively associated with the number of incoming calls in Montag et al. (2019). Moreover, Montag et al. (2014) reported excellent reliabilities of the tracked variables (calls) for the period of four weeks, which indicates that call behaviour is a stable variable on the phones and that a few weeks/perhaps even few days of tracking might provide already sufficient insights into call behaviour.
Stachl et al. (2017) also demonstrated a positive association between the frequency of calls, recorded on a smartphone for 60 days, and extraversion. However, extraversion was negatively linked to the duration of calls. Furthermore, positive associations between extraversion and application use related to photography and communication were reported. Regarding agreeableness, a positive relation with the use of transportation apps was reported, while conscientiousness was linked to lower use of gaming apps.
In another study, Montag et al. (2015b) addressed the role of social networking channels used on the smartphone. Here, 2418 participants with an average age of 25 years were tracked using the same Menthal application, introduced earlier in this section for the duration of four weeks (for more information on the actual data analysis see the original work). Participants received feedback regarding their smartphone use (e.g. duration of smartphone use per day or most frequently used applications) through the Menthal application as an incentive for their participation. Self-reported personality data was collected with the ten-item version of the Big Five Inventory (BFI), integrated in the app. Results showed that participants spent 162 min per day on average on their smartphones, with about 20% of this time dedicated to WhatsApp use (ca. 32 min per day) and with less than 10% (ca. 15 min) dedicated to Facebook use. Additionally, results showed that younger age and the female gender were linked to longer WhatsApp use. With respect to personality, extraversion was positively and conscientiousness negatively associated with the duration of WhatsApp use. Similar, but weaker patterns could be observed for the duration of Facebook use. Again, the observed associations were rather weak.
These values would be substantially higher if a better measurement was taken.
Chapter 5 Smartphones in Personal Informatics: A Framework for Self-Tracking Research with Mobile Sensing
Sumer S. Vaid and Gabriella M. Harari
Recent years have seen a growth in the spread of digital technologies for self-tracking and personal informatics. Smartphones‚ in particular, stand out as being an ideal self-tracking technology that permits both active logging (via self-reports) and passive tracking of information (via phone logs and mobile sensors). In this chapter, we present the results of a literature review of smartphone-based personal informatics studies across three different disciplinary databases (computer science, psychology, and communication). In doing so, we propose a conceptual framework for organizing the smartphone-based personal informatics literature. Our framework situates self-tracking studies based on their substantive focus across two domains: (1) the measurement domain (whether the study uses subjective or objective data) and (2) the outcome of interest domain (whether the study aims to promote insight or change in physical and/or mental characteristics). We use this framework to identify and discuss research trends and gaps in the literature. For example, most research has been concentrated on tracking of objective measurements to change either physical or mental characteristics, while less research used subjective measures to study a physical outcome of interest. We conclude by pointing to promising future directions for research on self-tracking and personal informatics and emphasize the need for a greater appreciation of individual differences in future self-tracking research.
These chapters scream “Gwern, please read me!”
Chapter 6 Digital Brain Biomarkers of Human Cognition and Mood
Paul Dagum
By comparison to the functional metrics available in other medical disciplines, conventional measures of neuropsychiatric and neurodegenerative disorders have several limitations. They are obtrusive, requiring a subject to break from their normal routine. They are episodic and provide sparse snapshots of a patient only at the time of the assessment. They require subjects to perform a task outside of the context of everyday behavior. And lastly, they are poorly scalable, taxing limited resources. We present validation studies that demonstrate the clinical efficacy of a new approach in reproducing gold-standard neuropsychological measures. We discuss the neuroscience constructs and mathematical underpinnings of cognition and mood measurement from human-computer interaction data. We conclude with a discussion on four areas that we predict will be impacted by these new clinical measurements: (i) understanding of the interdependency between cognition and mood; (ii) nosology of psychiatric illnesses; (iii) drug discovery; and (iv) delivery of healthcare services.
–
6.3 Digital Biomarkers of Cognition
In January of 2014, we launched a study to demonstrate the feasibility of decoding human-computer interactions into clinical measures of neuropsychological func- tion. We recruited 27 subjects (ages 18–34 years, education 14.1 ± 2.3 years, M:F 8:19) volunteered for neuropsychological assessment and installed an app on their smartphone that passively captured their HCI from touchscreen activity. All par- ticipants, recruited via social media, signed an informed consent form. Inclusion criteria required participants to be functional English speaking and active users of a smartphone. The protocol involved 3 h of psychometric assessment followed by installation of an app on their smartphone. The test battery is shown in the first column of Table 6.1. A single psychometrician performed all testing in a standard assessment clinic. The app on the phone ran passively in the background and captured patterns and timings of touch-screen user activity that included swipes, taps, and keystroke events, comprising the human-computer interactions.
From the HCI events we identified 45 interaction patterns using high- dimensionality reduction. Each pattern represents a task that is repeated up to several hundred times per day by a user during normal use of their phone. Most patterns con- sisted of two successive events, such as tapping on the space-bar followed by the first character of a word, or tapping the “delete” key followed by another “delete” key tap. Some patterns were collected in a specific context of use. For example, tapping on a character followed by another character could be collected at the beginning of a word, middle of a word, or end of a word. Each pattern generated a time-series composed of the time interval between patterns. The time-series were segmented into daily time-series. To each daily time-series we applied 23 mathematical transforms to produce 1,035 distinct daily features that we term digital biomarkers.
For each participant we selected the first 7 days of data following their test date. A biomarker was considered a candidate for a neurocognitive test if over the 7 day window the 7 correlations between sorted biomarker values and the test scores were stable (meaning of the same sign). The 2-dimensional design matrix for the super- vised kernel principal component analysis (PCA) was constructed by selecting the peak value of each candidate biomarker over the 7 days. For each test, we con- structed a linear reproducing Hilbert space kernel from the biomarkers and used a supervised kernel principal component analysis (Dagum 2018b) with leave-one-out- cross-validation (LOOCV) as follows. To predict the 1st participant test result the model fitting algorithm was run on the remaining participants without access to the 1st participant’s data, and so forth iterating 27 times to generate the 27 predictions. Cross-validation allows us to control the risk of over-fitting the data because each participant’s data is never used in fitting the model used to predict that participant’s results.
These preliminary results suggested that passive HCI measures from smartphone use could be a continuous ecological surrogate for laboratory-based neuropsycho- logical assessment. Smartphone human-computer interaction data from the 7 days following the neuropsychological assessment showed a range of correlations from 0.62 to 0.83 with the neurocognitive test scores. Table 6.1 shows the correlation between each neurocognitive test and the cross-validated predictions of the super- vised kernel PCA constructed from the biomarkers for that test. Figure 6.2 shows each participant test score and the digital biomarker prediction for (a) digits back- ward, (b) symbol digit modality, (c) animal fluency, (d) Wechsler Memory Scale-3rd Edition (WMS-III) logical memory (delayed free recall), (e) brief visuospatial mem- ory test (delayed free recall), and (f) Wechsler Adult Intelligence Scale-4th Edition (WAIS-IV) block.
An obvious limitation of this study was the small size (n = 27) relative to the large number of potential biomarkers (n = 1,035). To counter the risk of over-fitting these results, predictions were made using LOOCV, stringent confidence level (p < 10 − 4 ) and a simple linear kernel that was regularized. A further limitation was that the neuropsychological assessment occurred at one time point and the digital features were collected ecologically over the first 7 days following the assessment. For clinical assessments, we have found that the real-world, continuous assessment yields critical information relevant to function.


The tiny sample is dodgy, but the use of cross-validation makes one somewhat more trusting in the results. The findings make a lot of sense and the correlations are remarkably high. But we expect this because life is an IQ test, and all we need to get a good signal is aggregate many small signals.
Chapter 8 Orderliness of Campus Lifestyle Predicts Academic Performance: A Case Study in Chinese University
Yi Cao, Jian Gao and Tao Zhou
Different from the western education system, Chinese teachers and parents strongly encourage students to have a regular lifestyle. However, due to the lack of large-scale behavioral data, the relation between living patterns and academic performance remains poorly understood. In this chapter, we analyze large-scale behavioral records of 18,960 students within a Chinese university campus. In particular, we introduce orderliness, a novel entropy-based metric, to measure the regularity of campus lifestyle. Empirical analyses demonstrate that orderliness is significantly and positively correlated with academic performance, and it can improve the prediction accuracy on academic performance at the presence of diligence, another behavioral metric that estimates students’ studying hardness. This work supports the eastern pedagogy that emphasizes the value of regular lifestyle.


Chapter 9 Latest Advances in Computational Speech Analysis for Mobile Sensing
Nicholas Cummins and Björn W. Schuller
The human vocal anatomy is an intricate anatomical structure which affords us the ability to vocalisea large variety of acoustically rich sounds. As a result, any given speech signal contains an abundant array of information about the speaker in terms of both the intended message, i.e., the linguistic content, and insights into particular states and traits relating to the speaker, i.e., the paralinguistic content. In the field of computational speech analysis, there are substantial and ongoing research efforts to disengage these different facets with the aim of robust and accurate recognition. Speaker states and traits of interest in such analysis include affect, depressive and mood disorders and autism spectrum conditions to name but a few. Within this chapter, a selection of state-of-the-art speech analysis toolkits, which enable this research, are introduced. Further, their advantages and limitations concerning mobile sensing are also discussed. Ongoing challenges and possible future research directions in relation to the identified limitations are also highlighted.
–
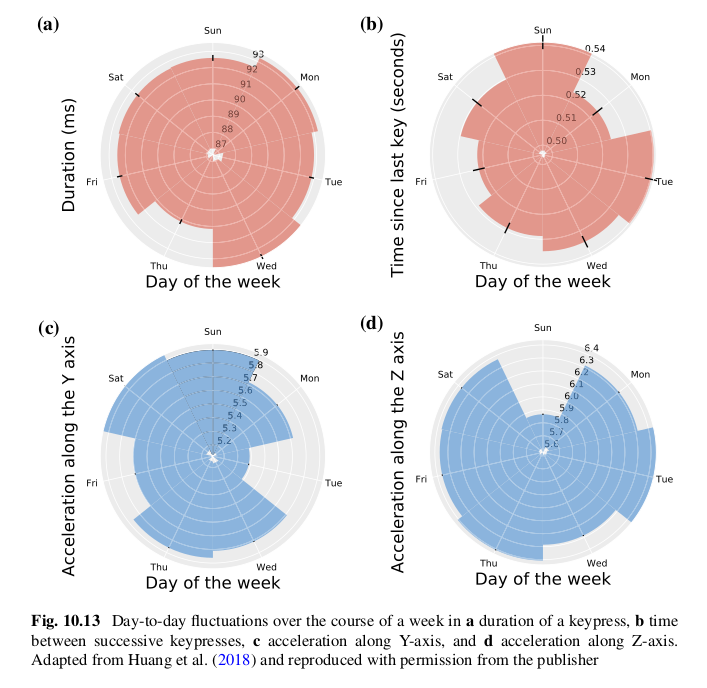
Chapter 10 Passive Sensing of Affective and Cognitive Functioning in Mood Disorders by Analyzing Keystroke Kinematics and Speech Dynamics
Faraz Hussain, Jonathan P. Stange, Scott A. Langenecker, Melvin G. McInnis, John Zulueta, Andrea Piscitello, Bokai Cao, He Huang, Philip S. Yu, Peter Nelson, Olusola A. Ajilore and Alex Leow
Life is too sweet and too short to express our affection with just our thumbs. Touch is meant for more than a keyboard. —Kristin Armstrong, Olympic cyclist
Mood disorders can be difficult to diagnose, evaluate, and treat. They involve affective and cognitive components, both of which need to be closely monitored over the course of the illness. Current methods like interviews and rating scales can be cumbersome, sometimes ineffective, and oftentimes infrequently administered. Even ecological momentary assessments, when used alone, are susceptible to many of the same limitations and still require active participation from the subject. Passive, continuous, frictionless, and ubiquitous means of recording and analyzing mood and cognition obviate the need for more frequent and lengthier doctor’s visits, can help identify misdiagnoses, and would potentially serve as an early warning system to better manage medication adherence and prevent hospitalizations. Activity trackers and smartwatches have long provided exactly such a tool for evaluating physical fitness. What if smartphones, voice assistants, and eventually Internet of Things devices and ambient computing systems could similarly serve as fitness trackers for the brain, without imposing any additional burden on the user? In this chapter, we explore two such early approaches—an in-depth analytical technique based on examining meta-features of virtual keyboard usage and corresponding typing kinematics, and another method which analyzes the acoustic features of recorded speech—to passively and unobtrusively understand mood and cognition in people with bipolar disorder. We review innovative studies that have used these methods to build mathematical models and machine learning frameworks that can provide deep insights into users’ mood and cognitive states. We then outline future research considerations and close by discussing the opportunities and challenges afforded by these modes of researching mood disorders and passive sensing approaches in general.
Chapter 18 Optimizing mHealth Interventions with a Bandit
Mashfiqui Rabbi, Predrag Klasnja, Tanzeem Choudhury, Ambuj Tewari and Susan Murphy
Mobile health (mHealth) interventions can improve health outcomes by intervening in the moment of need or in the right life circumstance. mHealth interventions are now technologically feasible because current off-the-shelf mobile phones can acquire and process data in real time to deliver relevant interventions in the moment. Learning which intervention to provide in the moment, however, is an optimization problem. This book chapter describes one algorithmic approach, a “bandit algorithm,” to optimize mHealth interventions. Bandit algorithms are well-studied and are commonly used in online recommendations (e.g., Google’s ad placement, or news recommendations). Below, we walk through simulated and real-world examples to demonstrate how bandit algorithms can be used to personalize and contextualize mHealth interventions. We conclude by discussing challenges in developing bandit-based mhealth interventions.
–
Bandit algorithms: “Bandit algorithms” are so called because they were first devised for the situation of a gambler playing one-armed bandits (slot machines with a long arm on the side instead of a push button). Each time the gambler picks a slot machine, he/she receives a reward. The bandit problem is to learn how to best sequentially select slot machines so as to maximize total rewards. The fundamental issue of bandit problems is the exploitation-exploration tradeoff; here exploitation means re-using highly rewarding slot machines from the past and exploration means trying new or less-used slot machines to gather more information. While exploration may yield less short-term payoff, an exploitation-only approach may miss a highly rewarding slot machine. Researchers have proposed solutions to the bandit’s exploit-explore tradeoff across many areas. In particular, once the relevance of bandit algorithms to internet advertising was understood, there was a flurry of work (Bubeck and Cesa- Bianchi 2012). Nowadays, bandit algorithms are theoretically well understood, and their benefits have been empirically demonstrated (Bubeck and Cesa-Bianchi 2012; Chapelle et al. 2012).
An important class of bandit problems is the contextual bandit problem that considers additional contextual information in selecting the slot machine (Woodroofe 1979). Contextual bandit problems provide a natural model for developing mobile health interventions. In this model, the context is the information about the individual’s current circumstances, the slot machines correspond to the different intervention options, and the rewards are near-time, proximal, outcomes (Nahum-Shani et al. 2017). In this setup, optimizing mHealth intervention delivery is the act of learning the intervention option that will result in the best proximal outcome in a given circumstance. This is same as solving the contextual bandit problem.
–
An effective approach to delivering less useful suggestions as little as possible is “optimism in the face of uncertainty” epitomized by the Upper Confidence Bound (UCB) technique (Auer et al. 2002; Li et al. 2010). Bandit algorithms based on the UCB have been well studied and possess guarantees of minimizing the number of less useful suggestions. The key intuition behind the UCB idea is the following: First, for each choice of action a t , a confidence interval is constructed for the linear combination β T a t . Recall this linear combination represents E[Y t |A t = a t ], the expected proximal outcome after receiving action, a t . Then the UCB bandit algorithm selects the action with the highest upper confidence limit. Note that the upper confidence limit for β T a t can be high for either of two reasons: (1) either β T a t is large and thus a t is a good action to make Jane active, or (2) the confidence interval is very wide with a high upper limit, indicating that there is much uncertainty about the value of β T a t . Using the upper confidence limit represents UCB’s optimism; UCB is optimistic that actions with high upper confidence limits will be the best actions, even though a larger upper confidence limit can mean more uncertainty. However, if an action with high upper confidence is indeed not the optimal action, then selecting the action will reduce the uncertainty about the effect of this action. This will help UCB realize that the action is indeed not useful. [the math symbols are broken here, read the book]
Never heard of this algorithm before, but this is intriguing! It’s also my general approach to science. Try the areas with potential high payoffs first, especially the ones that others are avoiding for political or taboo reasons. I feel like historically this approach has worked well in biology.