I came across this obscure study while doing some research on other matters.
-
Yan, H., Lavoie, A., & Das, S. (2017). The Perils of Classifying Political Orientation From Text. Linked Democracy: Artificial Intelligence for Democratic Innovation, 858, 8.
Political communication often takes complex linguistic forms. Understanding political ideology from text is an important methodological task in studying political interactions between people in both new and traditional media.Therefore, there has been a spate of recent research that either relies on, or pro-poses new methodology for, the classification of political ideology from text data. In this paper, we study the effectiveness of these techniques for classifying ideology in the context of US politics. We construct three different datasets of conservative and liberal English texts from (1) the congressional record, (2) prominent conservative and liberal media websites, and (3) conservative and liberal wikis,and apply text classification algorithms with a domain adaptation technique. Our results are surprisingly negative. We find that the cross-domain learning performance, bench marking the ability to generalize from one of these datasets to an-other, is poor, even though the algorithms perform very well in within-dataset cross-validation tests. We provide evidence that the poor performance is due to differences in the concepts that generate the true labels across datasets, rather than to a failure of domain adaptation methods. Our results suggest the need for extreme caution in interpreting the results of machine learning methodologies for classification of political text across domains. The one exception to our strongly negative results is that the classification methods show some ability to generalize from the congressional record to media websites. We show that this is likely be-cause of the temporal movement of the use of specific phrases from politicians to the media.
So the TL;DR is:
- They trained ML methods to classify politics based on different kinds of texts: congressional records, online magazines, Wikis (conservapedia and rationalwiki)
- They used cross-validation within and between sources to examine accuracy
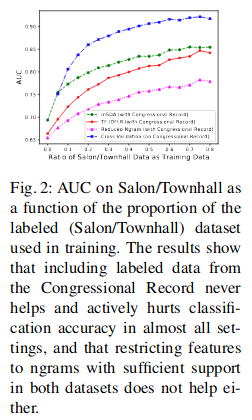
- Accuracy was very low when training on one kind of source and predicting into another
- This calls into question all the previous ML text based methods
Main results: