Abstract
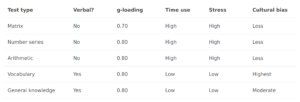
I reanalyze data published by Lynn and Yadav (2015) for Indian states. I find both G and S factors which correlate at .61. Method of correlated vectors was applied to both factors which yielded correlations of .87 and .97. In an experimental method, it variant of the method was applied to both factors combined, which yielded a correlation of .89.
Key words: intelligence, IQ, cognitive ability, S factor general socioeconomic factor, India, Indian states, inequality
Study materials: https://osf.io/3uz4f/files/
R notebook: http://rpubs.com/EmilOWK/Indian_states_reanalysis_2015
Main figure