Over the years I have been involved in quite a number of studies that measured intelligence (g) online in some way or another. Since people occasionally ask what is a good method, it seems worth writing a post about this.
When you do surveys online, you pay per time use per participant. Taking Prolific as an example, the price is at least 8 USD/hour. So if you wanted 500 participants to take a 20 minute survey, that would be at least (20/60)*8*500 = 1333 USD. Clearly, then, the main way to cut down in price is to measure things briefly. This necessity for low time cost has spawned a large literature on making abbreviated tests of various standard tests and questionnaires. In this post, I will focus on g, as I am most familiar with this trait. This post was inspired by a professor asking me about the ICAR5 abbreviated test that we made back in 2016. Back then, I was excited about the ICAR test. This paper has a nice review of the findings using it:
- Dworak, E. M., Revelle, W., Doebler, P., & Condon, D. M. (2021). Using the International Cognitive Ability Resource as an open source tool to explore individual differences in cognitive ability. Personality and Individual Differences, 169, 109906.
Although the measurement of intelligence is important, researchers sometimes avoid using them in their studies due to their history, cost, or burden on the researcher. To encourage the use of cognitive ability items in research, we discuss the development and validation of the International Cognitive Ability Resource (ICAR), a growing set of items from 19 different subdomains. We consider how these items might benefit open science in contrast to more established proprietary measures. A short summary of how these items have been used in outside studies is provided in addition to ways we would love to see the use of public-domain cognitive ability items grow.
ICAR wasn’t designed to be brief, but to be an open source, public domain alternative to the existing very expensive standardized tests. I used to be active in the Pirate Party so this goal appealed to me. The ICAR team made several hundred items of which they selected 60 for the ICAR60, and another 16 for the ICAR16. Both of these have been validated against existing g tests, and seem just fine. In general, it is not too difficult to make a g test. Just about any question or task (item) with some some obvious cognitive demand will measure g to some degree. Later on, I wanted to do a study of various Danish students, so I picked the most optimal set of 5 items from the ICAR16 to make the ICAR5. This was then used in a few papers as a really brief measure of g. But how well does this work? Think of it as optimizing a few different things at once:
- Least time use
- Least participant stress (to avoid drop-out and selective participation)
- Highest g-loading
- Least bias (items should work equally well for everybody)
A few recent posts have focused on the partial solution to this, namely, which kind of test (of many items) have the highest g-loading. I wrote a post and so did Seb Jensen. Generally, the best tests seem to be vocabulary, general knowledge, basic arithmetic, and number series (g-loading around .80). There may be others with very good loadings, but which were not used often enough to show up in the studies we reviewed. Matrices (Raven type) were also decent (g-loading around .70), but somewhat worse than the top 4. But which of the 4 to use? Ideally, a mix of items should be used because this reduces the non-g variance in the scores. Any type of item will have some relationship to g, some relationship to non-g abilities, and some noise (error). If you use items of only one type, the non-g variance will accumulate and this will result in some ‘coloring’ or ‘flavoring’ of the g scores, as they now reflect a mix of g and the non-g abilities related to the items. To avoid this, one can mix the items, and the non-g abilities will then cancel out among each other given a perfect balance of items (their information contribution, to be specific).
But what about the other criteria? Two of the top 4 test types are verbal and either highly or moderately culturally specific. Vocabulary works well for native speakers of a given language, but has a notable bias on non-native speakers in proportion to their familiarity with the language. Even someone who has spent decades learning a foreign language will not usually be as fluent as in their native language. General knowledge can be made more culturally neutral, but it is difficult to ask questions that people of the same g are equally likely to know across all cultures and ages. Even across European cultures, there will be differences in what is taught in school, and what kind of facts people are likely to acquire elsewhere. General knowledge thus can be used, but one has to take care to avoid bias.
Should one go for nonverbal tests like number series and arithmetic then? Perhaps! But these kinds of tests take quite a bit more effort, as one has to do actual thinking in the moment rather than retrieve information from memory. Each item takes 3-10 times as much time to answer as a vocabulary or general knowledge item, but their g-loadings are not higher to compensate for this. In fact, they are often lower. Because of this inefficiency, using nonverbal tests is usually time inefficient, more stressful, but less biased.
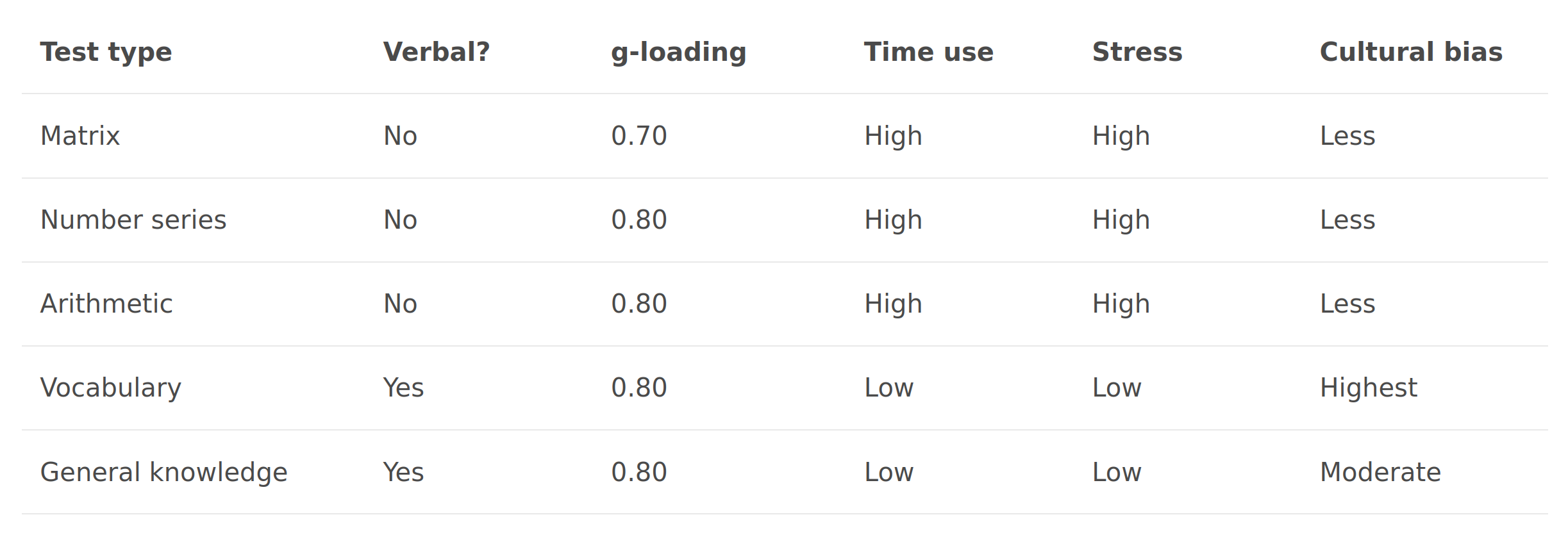
To sum things up with the top 4 tests, we can make this matrix:
| Test type | Verbal? | g-loading | Time use | Stress | Cultural bias |
| Matrix | No | 0.70 | High | High | Less |
| Number series | No | 0.80 | High | High | Less |
| Arithmetic | No | 0.80 | High | High | Less |
| Vocabulary | Yes | 0.80 | Low | Low | Highest |
| General knowledge | Yes | 0.80 | Low | Low | Moderate |
Which mix of items is optimal for you depends on your study. If you are studying people who can be presumed to be native speakers of a given language, vocabulary will be the easiest option. If you cannot assume almost everybody is a native speaker, but everybody at least has a good grasp of English, then a carefully made general knowledge is a good idea. If you have quite divergent cultural and language backgrounds and don’t want to risk any bias in a general knowledge test, you will have to go for the nonverbal tests. Ideally, you would mix multiple items. So for a sample of native speakers, mix up about half vocabulary and general knowledge items. If you have a very diverse group, use number series, arithmetic and maybe matrices.
One could expand the above test matrix with more definite numbers and more tests, of course, but this gives you a rough idea of what is good. For instance, the 3D rotation items found in ICAR use a lot of time, but have high g-loadings as well. Unless you are interested specifically in spatial ability itself, they are probably inferior to the number series and arithmetic items on a time basis, but including some of them can help balance the test types. Tests that are heavily based on short term memory (e.g. digit span) are usually rather poor in g-loading while also being stressful and should be avoided unless you are particularly interested in short term memory (e.g. studying dementia). Unfortunately, neuroscience researchers love these tests so their batteries of tests usually have a large memory flavor of their g scores (e.g. NIH toolbox).
To take a practical example. Suppose you want to do an online study of Americans, and you can devote 10 minutes to measuring g, you might want to use something like 20 vocabulary, and 20 general knowledge items. If your sample has a lot of recent immigrants, you may want to stick with only general knowledge. If the potential for bias is still too high, you might switch to 7 number series + 7 arithmetic items. I cannot guarantee this will take exactly 10 minutes, but that would be my guess. Assuming the numbers hold, the 10 minutes will equate to 14 nonverbal items, or 40 verbal items. The g-loading of scores from the latter test will be much higher than the former but it will have more potential for bias. I am not aware of any nonverbal test that has low time use and low stress level, while still retaining a high g-loading. Finding such a test is an important goal for future research. My best guess would be something based on time measurement as discussed in my prior post.
What ready-made tests can you use? Well, ICAR includes number series (9 items) and matrices (11 items) in its collection. However, most of their number series items are based on Roman letters for some reason, so you have to first convert these to numerals (languages differ in their alphabets, so letters don’t correspond to the same values in all cases).
If you are looking for general knowledge, you probably should check out the items on the The Multifactor general knowledge test (MFGKT) available online. Many of the items have bias, however, so read the analysis by Seb Jensen on picking a least-biased subset of these. For science knowledge, you can use the items from Pew Research’s science quizzes (about 30 items, I have a study coming out about the items, but most of them show little bias for sex or race in the USA). There is another 20 items in our Dutch study.
For vocabulary, you can use our Dutch (20 items, see R notebook for item stats), or the English test from openpsychometrics.org (45 items, see my analysis for which items are highest loading). We are in the process of making more of these. It is fairly easy to make new vocabulary items for most languages using the AI chatbots.
I hope this helps people doing online measures of intelligence.