Back in January, Steve Hsu did an interview with Daphne Martschenko who is a phd candidate at Cambridge in education. She’s basically doing science journalism on behavioral genetics as far as I can tell. Now there’s a new interview up. I have some comments to it because Steve was a little too nice.
Bias from twin studies
A never ending topic of contention in the last 100 years or so has been the ability of standard twin studies (MZ-DZ reared together comparison) to correctly estimate causation parameters, in particular heritability, shared environment (whatever siblings have in common), and everything else (‘unshared environment’).
Assortative mating
Assortative mating – the tendency of mates to be similar in traits – is generally a thing, not just for humans. But for humans, it seems to be strongest for age (.77) and religiousness (.75), substantial for educational attainment, cognitive ability (.48), political preferences (~.35), criminality (~.40), and apparently weak for personality (r’s 0-.20), at least when we rely on self-reported, high-order (5-6 factors) scores. There’s even weak to moderate assortative mating for seemingly irrelevant physical features like ear lobes.
Assortative mating negatively biases heritability because it makes DZ twins more genetically similar on the trait of interest. Why? Because if parents are similar on a trait, and this trait is heritable, the parents are actually slightly related (inbred) with regards to that trait (and in general). To the degree that this is true, the genetic similarity of the DZ twins will be above 50%. However, MZ twins cannot get more similar since they are already at 100% (minus a few somatic mutations). The usual method to estimate heritability from standard twin studies relies on the assumption that there is no assortative mating because this means the DZ’s are 50% genetically alike while the MZ’s are 100%. This means that one can just double the difference between their correlations to estimate heritability: H=2(MZ-DZ). In the presence of assortative mating, one has to more than double this value because the genetic difference in difference in less than 50%. E.g. if the DZ’s are actually 60% related for the trait, the difference between their relatedness and the MZs relatedness is only 40%points. We need to multiple 40% 2.5 times instead of 2 to get to 100%. If we suppose for that a particular trait, MZs correlate at .85, DZs at .60, then the standard estimate of heritability would be 2(.85-.60)=50%. But if there is assortative mating as we assumed, we need to do 2.5(.85-.60)=62.5%. The bias in this was about -20%.
For more details, see: http://onlinelibrary.wiley.com/doi/10.1111/1745-9125.12049/abstract
Measurement error downwards bias
Measurement error — noise in the measurement of traits — systematically depresses correlations between any two variables. This also applies to twin studies. Measurement error makes the MZ and DZ correlations smaller which means that heritability estimates get lower too, and the everything else category grows. Let’s say we have the above correlations, but we know that our tests only have .90 reliability. What we need to do is correct the observed correlations first: .85/sqrt(.90*.90)=.944, and .60/sqrt(.90*.90)=.667. Then we plug the numbers back in: 2(.944-.667)=55.4%. But then, we also should take into account assortative mating: 2.5(.944-.667)=69.3%.
Thus, taking into account both assortative mating (possibly an unrealistic amount, not sure how to calculate this exactly) and realistic amounts of measurement error yields a heritability estimate that’s about 40% larger (50% vs. 69.3%).
Special MZ environment possible upwards bias
The standard twin design assumes that the environments of MZs are no more similar than those of DZs (in the equations, both MZ’s and DZ’s C are correlated at 1.00). Common sense has it that this is probably not entirely true. MZs look and act extremely similar and so it is possible that people — including their parents — treat them more similarly. This may cause an extra environmental effect that makes them more similar. This would cause upwards bias in the heritability estimates because the effect of special MZ environment is confounded with the genetic effect. The size of the bias depends on how much more similar the MZ environment is compared to the DZ, and on the effect size of this environment effect. If this sibling environment-type effect is weak to begin with, even a strong extra MZ environment would only weakly bias the estimates. (Again, I think too complicated to give a numeric example.) That’s the reason I said it’s a possible bias. The bias from assortative mating and measurement error are known, not merely possible.
How can we find about this possible bias? There are multiple options. One is:
In 1968, Scarr proposed a test of the EEA which examines the impact of phenotypic similarity in twins of perceived versus true zygosity. We apply this test for the EEA to five common psychiatric disorders (major depression, generalized anxiety disorder, phobia, bulimia, and alcoholism), as assessed by personal interview, in 1030 female-female twin pairs from the Virginia Twin Registry with known zygosity. We use a newly developed model-fitting approach which treats perceived zygosity as a form of specified familial environment. In 158 of the 1030 pairs (15.3%), one or both twins disagreed with the project-assigned zygosity. Model fitting provided no evidence for a significant influence of perceived zygosity on twin resemblance for any of the five disorders.
There’s a replication here, n=882. There’s a bunch of more studies too.
There’s another kind of study as well: sometimes twins get misclassified, including by their parents and themselves. Meaning, they think they are MZ, but they are really DZ, or the other way around. There’s been a number of such studies and there’s a 2013 review of them. No surprises.
What about womb effects? Twins may or may not share placentas and chorions. Pretty much no effect of these either.
Other family members?
Twins reared together are just convenient, but one can use pretty much any pair of family relations. Here’s a large study using siblings and half-siblings:
Twin studies have been criticized for upwardly biased estimates that might contribute to the missing heritability problem.
We identified, from the general Swedish population born 1960-1990, informative sibships containing a proband, one reared-together full- or half-sibling and a full-, step- or half-sibling with varying degrees of childhood cohabitation with the proband. Estimates of genetic, shared and individual specific environment for drug abuse (DA), alcohol use disorder (AUD) and criminal behavior (CB), assessed from medical, legal or pharmacy registries, were obtained using Mplus.
Aggregate estimates of additive genetic effects for DA, AUD and CB obtained separately in males and females varied from 0.46 to 0.73 and agreed with those obtained from monozygotic and dizygotic twins from the same population. Of 54 heritability estimates from individual classes of informative sibling trios (3 syndromes × 9 classes of trios × 2 sexes), heritability estimates from the siblings were lower, tied and higher than those from obtained from twins in 26, one and 27 comparisons, respectively. By contrast, of 54 shared environmental estimates, 33 were lower than those found in twins, one tied and 20 were higher.
With adequate information, human populations can provide many methods for estimating genetic and shared environmental effects. For the three externalizing syndromes examined, concerns that heritability estimates from twin studies are upwardly biased or were not generalizable to more typical kinds of siblings were not supported. Overestimation of heritability from twin studies is not a likely explanation for the missing heritability problem.
One can also use family members not reared together such as regular adoptions and the rare MZ adoptions. Generally these approaches also find similar results.
To be fair, here’s a large Icelandic study that used a variety of relationships that found lower heritability estimates (about 75% of standard) and higher shared environment estimates. Not sure why this is the case.
Still, most of the evidence fits with no particular bias from which kinds of family relationship are used. Measurement error, however, always biases heritability downwards.
Heritability of cognitive ability, and parental S
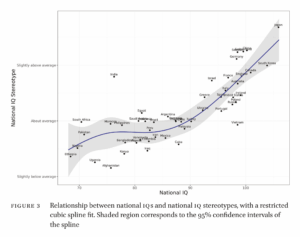
Daphne refers to the famous Turkheimer 2003 study. Since this is an interaction finding (interactions have low priors) and suited left-wingers, this finding spread like wildfire despite other equally large or larger studies finding no such effect (some found reverse effects too). Finally, 12 years later, someone did a meta-analysis, and we can now see that: 1) this finding is apparently only seen in US samples, and 2) it was wildly overestimated by the initial study. There’s some rather extreme citation bias there too. I wonder why.
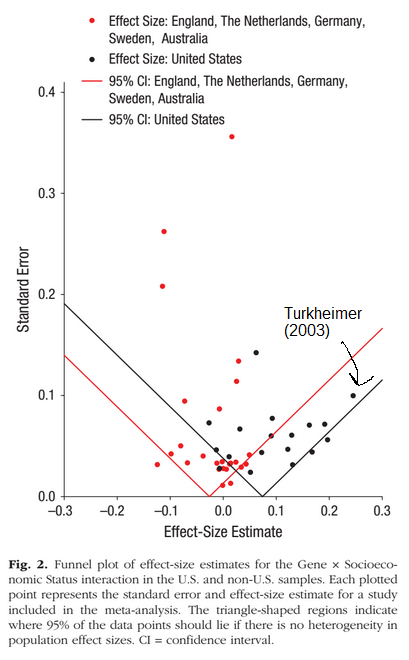
Even if this interaction effect was large, it is mostly pointless because shared environment effects go away with age for this trait.
Heritability of social success
Daphne talks about the heritability of social success, e.g. occupations, education and so on. While one can estimate the influence of cognitive ability indirectly, it’s easier to just estimate heritability directly, which was first done 40 years ago. The finding of heritable social success is more a less a given because: 1) if success is a function of psychological traits, 2) psychological traits are moderately to highly heritable, then 3) success is pretty likely to be fairly heritable too. Herrnstein’s syllogism.
This field is in general not well researched because it lacks a unifying theory (which the S factor model provides, kinda sorta). However, here’s some findings:
Education: meta-analysis ~ 40% H, C = 36%, E=25% (yes, apparently, they sum to 101). 44% in Taubman 1967.
Income: 42% in NLSY. 25-54% in Finnish twins female/male. 48% in Taubman 1976.
Occupation: 43% among the 1944-1960 cohort.
‘Neighborhood deprivation’: 65% nation-wide Swedish dataset, 71% in Scotland.
Still missing a more general, S factor heritability study (this can be done using NLSY links). I will make this prediction: higher S loading → higher heritability. E.g. single year income has poor S loading because it’s a bad indicator of S, and hence heritability. Heritability of S comes from highly heritable traits that include cognitive ability, personality and interests.
Self-identified race/ethnicity, race and cognitive ability
I am fortunate that these are my views because they are politically correct and garner me praise, speaking and writing invitations, and book adoptions at the same time those who disagree with me are demeaned, ostracized, and in some cases threatened with tenure revocation even though their science is as reasonable as mine. Don’t get me wrong, I think their positions are incorrect and I have relished aiming my pen at what I regard to be their leaps of logic and flawed analysis. But they deeply believe that I am wrong. The problem is that I can tell my side far more easily than they are permitted to tell theirs, through invitations to speak at meetings, to contribute chapters and articles, etc.. This offends my sense of fairness and cannot be good for science. I think Saletan would agree with me on this.
See also: Double standards.
As for genomic ancestry and self-identity, there are lots of studies. Here’s some results from the PING dataset:

We relate ancestry to cognitive ability, while controlling for SIRE (and all the cultural effects related to SIRE), then we get:

The method is not entirely satisfactory. Better would be if we also had skin brightness from the persons (PING does not seem to have this), so we could control for any effects of skin-based racism, however implausible. Better yet, we could get a large set of racially admixed siblings. These siblings vary slightly in their genomic ancestry in imperceptible ways (e.g. one is 55% African, another is 50%). A genetic model predicts this small variation to be linked to cognitive ability. This design is neat because by virtue of using siblings, it controls for family effects. The results of such a study would be pretty conclusive. It’s not at all impossible, a very similar study has already been done for height. All that is needed is some large (10k? Maybe Gwern should do a power analysis? :) ) sibling dataset with genomic data, cognitive ability and skin brightness.
Or, we use exploit the fact that while in the total population, skin brightness and racial ancestry are moderately to strongly correlated (r ≈ .50), they aren’t so between siblings (I can’t find an empirical demonstration of this). However, if skin-based racism is really responsible for cognitive differences, then skin brightness differences between siblings should show correlations to cognitive ability differences, educational attainment, income, and so on. Yet they don’t. And if we control for cognitive ability, skin brightness has positive correlations to education. The opposite of what colorism predicts. In general, colorism is not a good hypothesis. The race gaps are smaller for things like income, whereas these are the easiest things to discriminate for.
GWAS results/polygenic scores, by the way, replicate/work partly in non-European samples too, to a degree that depends on the relatedness according to an animal breeding study. This is because the causal tagging depends on LD patterns. SNPs are generally not causal (or so we think!), they are just close to the causal variants on the genome.
Isn’t it more than a little odd that a topic that so many people consider so important and which is so easy to get to the bottom of, attracts so little research attention? This debate is easy to settle: get access to medical datasets with the required variables.