A new preprint is out on a massive many teams study. In this design, a single dataset (or database) is given to a bunch of researchers, and they are asked to answer some questions (research hypotheses). They are left to their own choices in how to deal with the data, transformations, outliers, models, and so on. These choices are called researcher degrees of freedom (RDF) by analogy with statistical degrees of freedom. Let’s look at the three studies so far (I covered one in the prior post against neuroscience):
-
Silberzahn, R., Uhlmann, E. L., Martin, D. P., Anselmi, P., Aust, F., Awtrey, E., … & Nosek, B. A. (2018). Many analysts, one data set: Making transparent how variations in analytic choices affect results. Advances in Methods and Practices in Psychological Science, 1(3), 337-356.
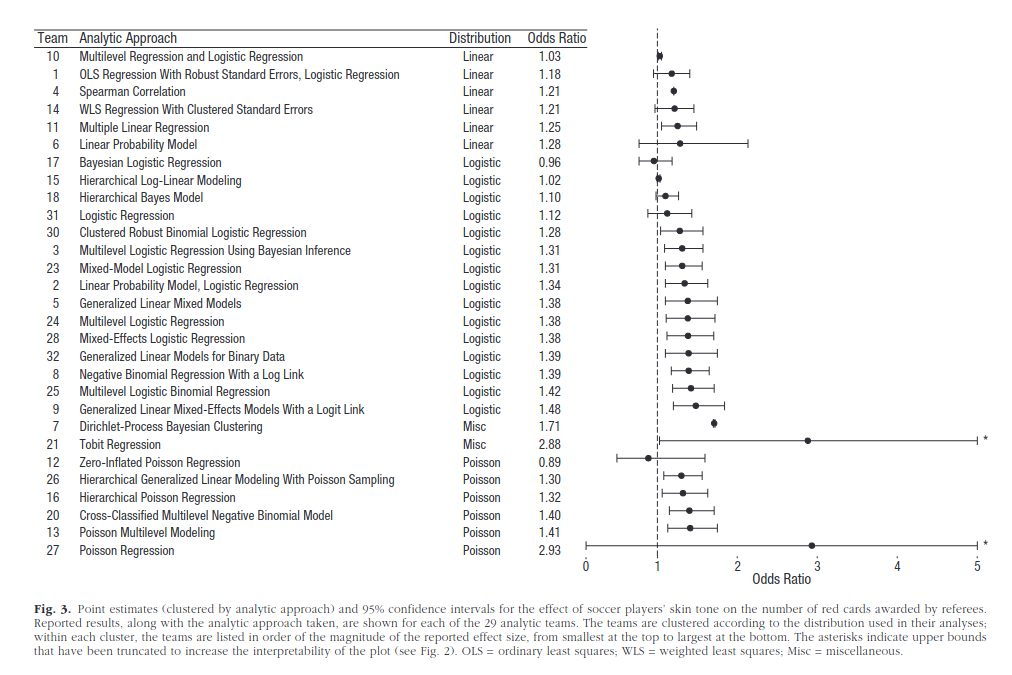
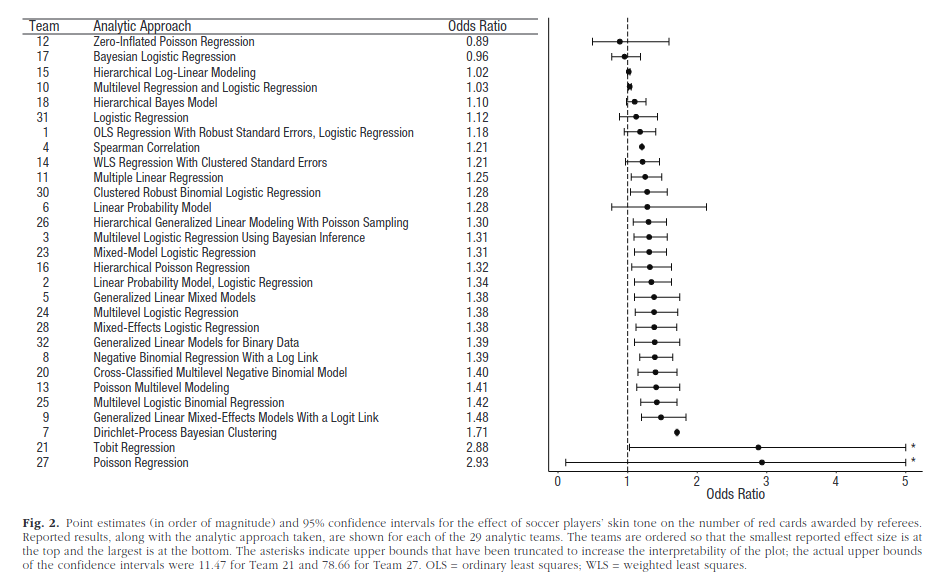
Twenty-nine teams involving 61 analysts used the same data set to address the same research question: whether soccer referees are more likely to give red cards to dark-skin-toned players than to light-skin-toned players. Analytic approaches varied widely across the teams, and the estimated effect sizes ranged from 0.89 to 2.93 (Mdn = 1.31) in odds-ratio units. Twenty teams (69%) found a statistically significant positive effect, and 9 teams (31%) did not observe a significant relationship. Overall, the 29 different analyses used 21 unique combinations of covariates. Neither analysts’ prior beliefs about the effect of interest nor their level of expertise readily explained the variation in the outcomes of the analyses. Peer ratings of the quality of the analyses also did not account for the variability. These findings suggest that significant variation in the results of analyses of complex data may be difficult to avoid, even by experts with honest intentions. Crowdsourcing data analysis, a strategy in which numerous research teams are recruited to simultaneously investigate the same research question, makes transparent how defensible, yet subjective, analytic choices influence research results.
-
Botvinik-Nezer, R., Holzmeister, F., Camerer, C. F., Dreber, A., Huber, J., Johannesson, M., … & Rieck, J. R. (2020). Variability in the analysis of a single neuroimaging dataset by many teams. Nature, 582(7810), 84-88.
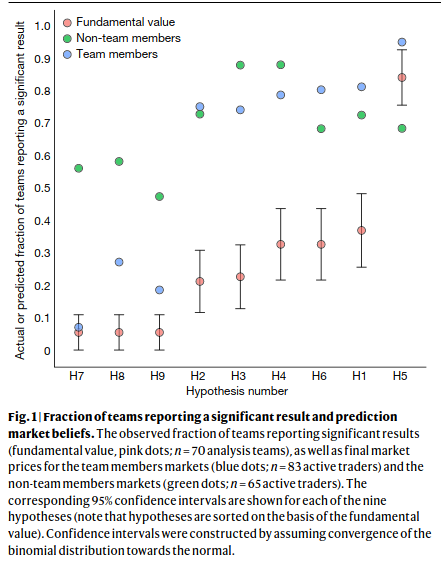
Data analysis workflows in many scientific domains have become increasingly complex and flexible. Here we assess the effect of this flexibility on the results of functional magnetic resonance imaging by asking 70 independent teams to analyse the same dataset, testing the same 9 ex-ante hypotheses1. The flexibility of analytical approaches is exemplified by the fact that no two teams chose identical workflows to analyse the data. This flexibility resulted in sizeable variation in the results of hypothesis tests, even for teams whose statistical maps were highly correlated at intermediate stages of the analysis pipeline. Variation in reported results was related to several aspects of analysis methodology. Notably, a meta-analytical approach that aggregated information across teams yielded a significant consensus in activated regions. Furthermore, prediction markets of researchers in the field revealed an overestimation of the likelihood of significant findings, even by researchers with direct knowledge of the dataset2,3,4,5. Our findings show that analytical flexibility can have substantial effects on scientific conclusions, and identify factors that may be related to variability in the analysis of functional magnetic resonance imaging. The results emphasize the importance of validating and sharing complex analysis workflows, and demonstrate the need for performing and reporting multiple analyses of the same data. Potential approaches that could be used to mitigate issues related to analytical variability are discussed.
-
Breznau, N., Rinke, E. M., Wuttke, A., Adem, M., Adriaans, J., Alvarez-Benjumea, A., … & van der Linden, M. (2021). Observing Many Researchers using the Same Data and Hypothesis Reveals a Hidden Universe of Data Analysis. MetaArxiv
Across scientific disciplines, recent studies unambiguously find that different researchers testing the same hypothesis using the same data come to widely differing results. Presumably this outcome variability derives from different research steps, but this has yet to be tested. In a controlled study we open the black box of research by observing 73 research teams as they independently conduct a same-data, same-hypothesis study. We find that major research steps explain at most 2.6% of total variance in effect sizes and 10% of the deviance in subjective conclusions. Expertise, prior beliefs and attitudes explain even less. Each generated model was unique, which points to a vast universe of research design variability normally hidden from view in the presentation, consumption, and perhaps even creation of scientific results.
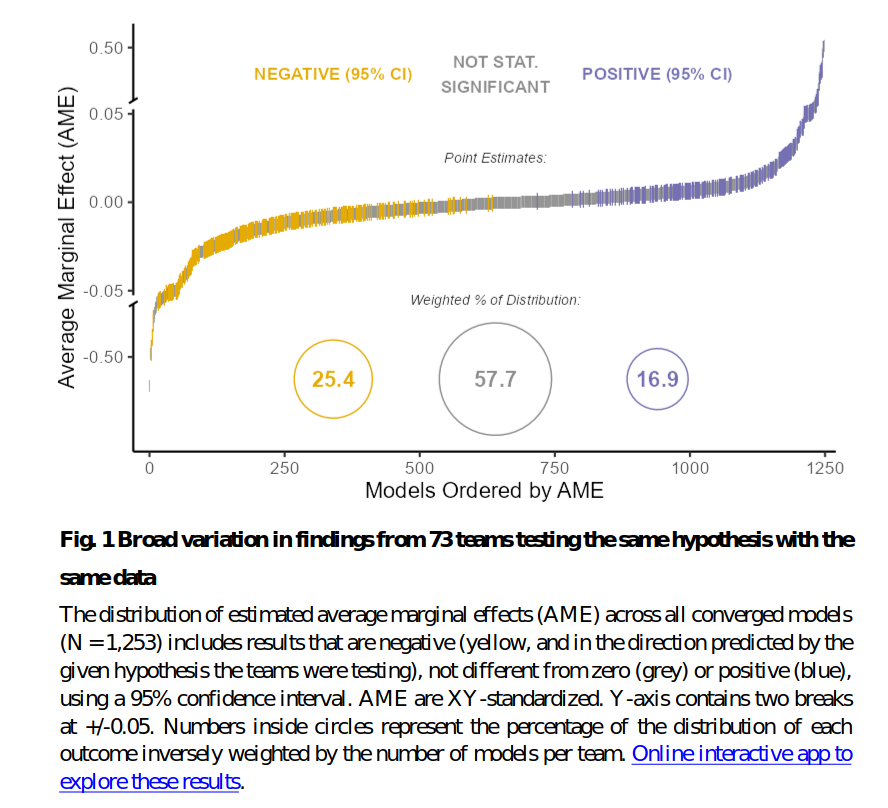
The conclusions are sobering:
- There is often large variation in results from analysis of the same dataset, even when researchers follow what they consider to be normal methods.
- Most datasets are only ever analyzed by a single team. This means you are looking at the draw of one result from the distribution of possible results owing to RDF from some combination of dataset and research question.
- In fact, most datasets can only be analyzed by a single team, because the datasets are not properly shared. In facter, most datasets are lost to history, so they cannot even potentially be reanalyzed even by the same authors.
- Various differences between researchers will be reflected in their choices. This is where political bias comes in. One can often try more than one specification and report preferably the ones that produce the best results for a given interest. This bias is inevitable, and can only be combated by pre-registration of exact methods. For many datasets this is not possible since there are too many choices in a given analysis, one cannot make them all before looking at the data.
- A prudent reader of science takes this uncertainty into account. Conclusions are more reliable when they are produced from diverse datasets and by many people, especially diverse people.
Edited to add: 2021-04-27
There is a new preprint with some guidelines to doing these studies. More useful to us, it contains a longer list of these, more I didn’t know about. Here they are, bold are the ones I highlighted above:
- Bastiaansen, J. A. et al. Time to get personal? The impact of researchers choices on the selection of treatment targets using the experience sampling methodology. J. Psychosom. Res. 137, 110211 (2020).
- Dongen, N. N. N. van et al. Multiple Perspectives on Inference for Two Simple Statistical Scenarios. Am. Stat. 73, 328–339 (2019).
- Salganik, M. J. et al. Measuring the predictability of life outcomes with a scientific mass collaboration. Proc. Natl. Acad. Sci. 117, 8398–8403 (2020).
- Silberzahn, R. et al. Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results. Adv. Methods Pract. Psychol. Sci. 1, 337–356 (2018).
- Botvinik–Nezer, R. et al. Variability in the analysis of a single neuroimaging dataset by many teams. Nature 582, 84–88 (2020).
- Dutilh, G. et al. The Quality of Response Time Data Inference: A Blinded, Collaborative Assessment of the Validity of Cognitive Models. Psychon. Bull. Rev. 26, 1051–1069 (2019).
- Fillard, P. et al. Quantitative evaluation of 10 tractography algorithms on a realistic diffusion MR phantom. NeuroImage 56, 220–234 (2011).
- Starns, J. J. et al. Assessing theoretical conclusions with blinded inference to investigate a potential inference crisis. Adv. Methods Pract. Psychol. Sci. 2, 335–349 (2019).