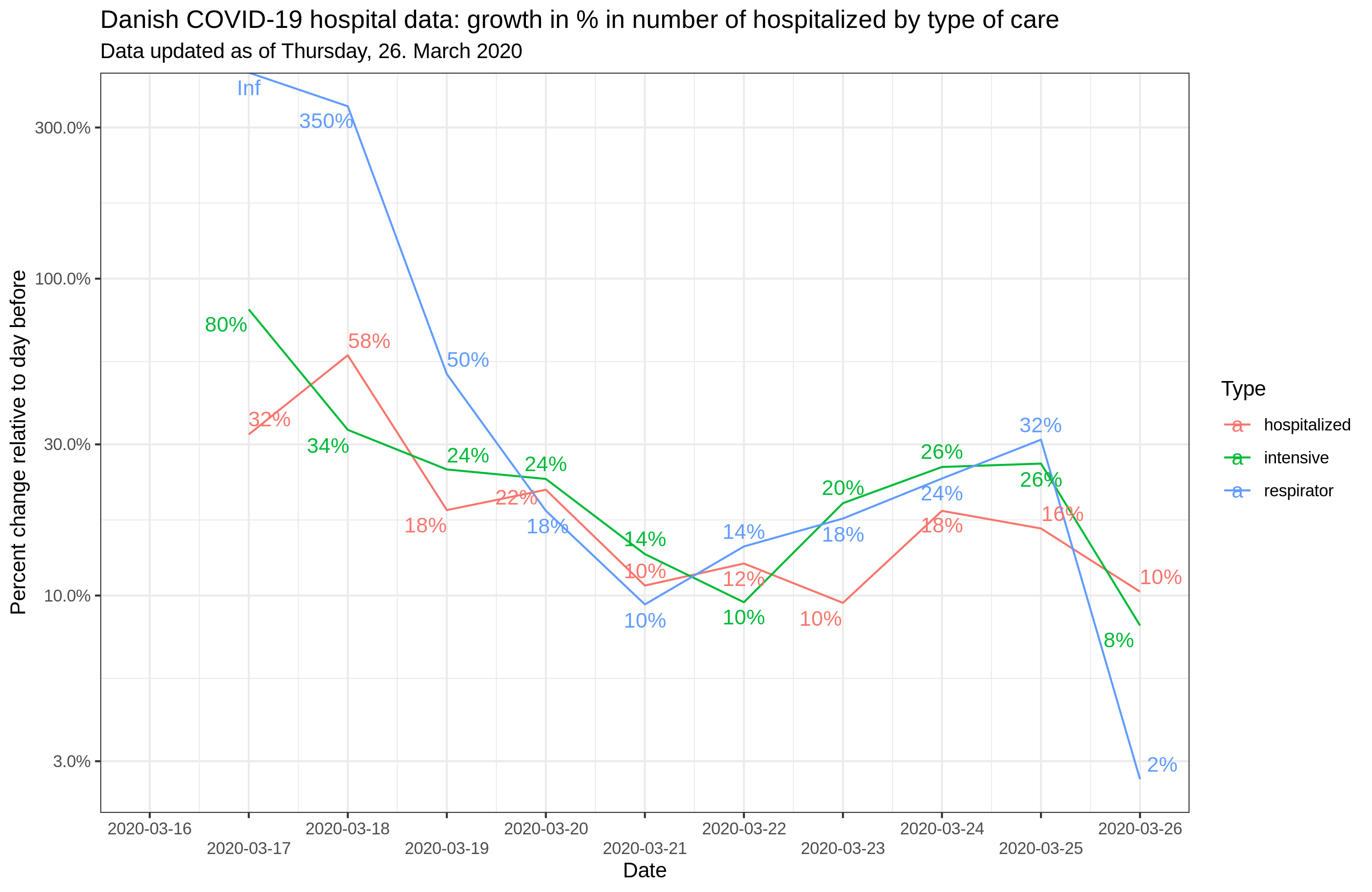
Every day, I post the updated Danish COVID-19 hospitalization data on Twitter and Facebook The latest version is always available at https://rpubs.com/EmilOWK/COVID19_Denmark. The raw data are here. The figures for March 26th look like this:


Why track hospitalizations instead of cases? Because the number of true cases is practically unknown due to lack of large-scale random testing (see prior post), but we can be confident that the number of hospitalizations is roughly correct since they test anyone with broadly matching symptoms. In other words, this tracking is based on this model of the COVID-19 cases:

We don’t know how many mild cases there are, but we do know the areas under the right tail by different cutoffs. Deaths are also decent to track, but since they are few in number, they provide unreliable statistics, and are quite delayed since the disease history takes a while to unfold. It should be said that the hospitalization approach is based on the assumption that the thresholds don’t change, which they could if the healthcare system gets overloaded to the point where they refuse to hospitalize anyone except the most severe cases, or refuse to hospitalize people who aren’t likely savable. Thus, one can probably use this approach to track the epidemic in Denmark, but it would be unwise to use it on Lombardian data.
