I’ve got a new paper out of some nontrivial interest to many.
- Kirkegaard, E. O. W. (2021). New paper out: Genetic ancestry and social race are nearly interchangeable. OpenPsych
It has been claimed that social race and genetic ancestry are at best weakly related. Here we test this claim by applying predictive modeling in both directions, i.e., predicting genetic ancestry from social race(s), and predicting social race(s) from genetic ancestry. We utilize the public Pediatric Imaging, Neurocognition, and Genetics (PING) dataset (n = 1,391), so that others may examine the data as well. In the simple scenario where we are only concerned with self-identified white, black, and mixed (black-white) race individuals (571 whites, 140 blacks, 25 mixed), model accuracy was very high. Predicting social race from genetic ancestry resulted in an area under curve (AUC) of .994, an overall accuracy (concordance) of 98.0%, and a pseudo-R2 of .951. Conversely, predicting genetic ancestry from social race had a model R2 adjusted of .992. Using the full dataset, there are 8 census-type categories of social race. Using cross-validated multinomial regression to predict social race from 6 genetic ancestry variables, we find that the AUC is .89. Using Dirichlet regression to predict ancestries from social race, we find an overall correlation of .94 (R2 = 88.4%). Further analyses using more sophisticated methods (random forest, support vector machine) found similar results. In conclusion, social race and genetic ancestry are nearly interchangeable.
It’s the battle of our time: genetics, race and social inequality. We’ve been over this a number of times. A typical talking point of the woke is to deny relationships between genetics and social race, or claim they are merely weak. They don’t generally provide numbers for such claims. So what are the numbers? This is what this study looked at.
The dataset is the PING, the same dataset we used previously. It is fairly representative of the US children and youth group:
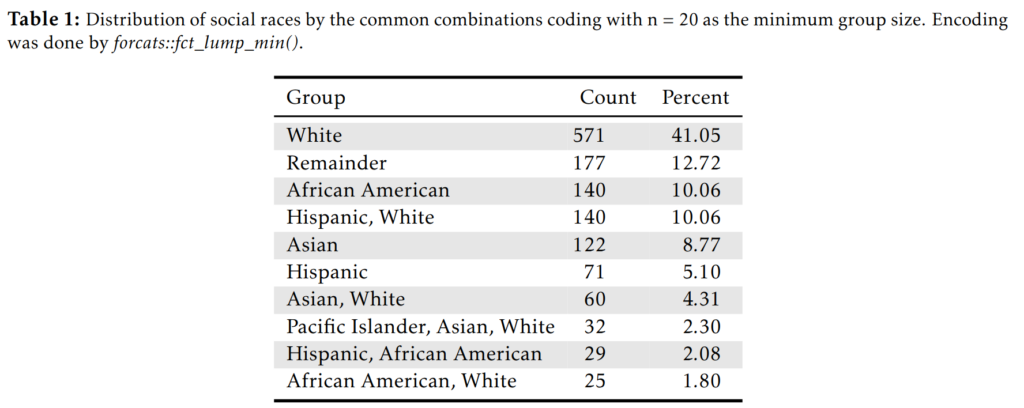
These values are based on what the kids or youths themselves said they were, or their parent if they were too young to respond.
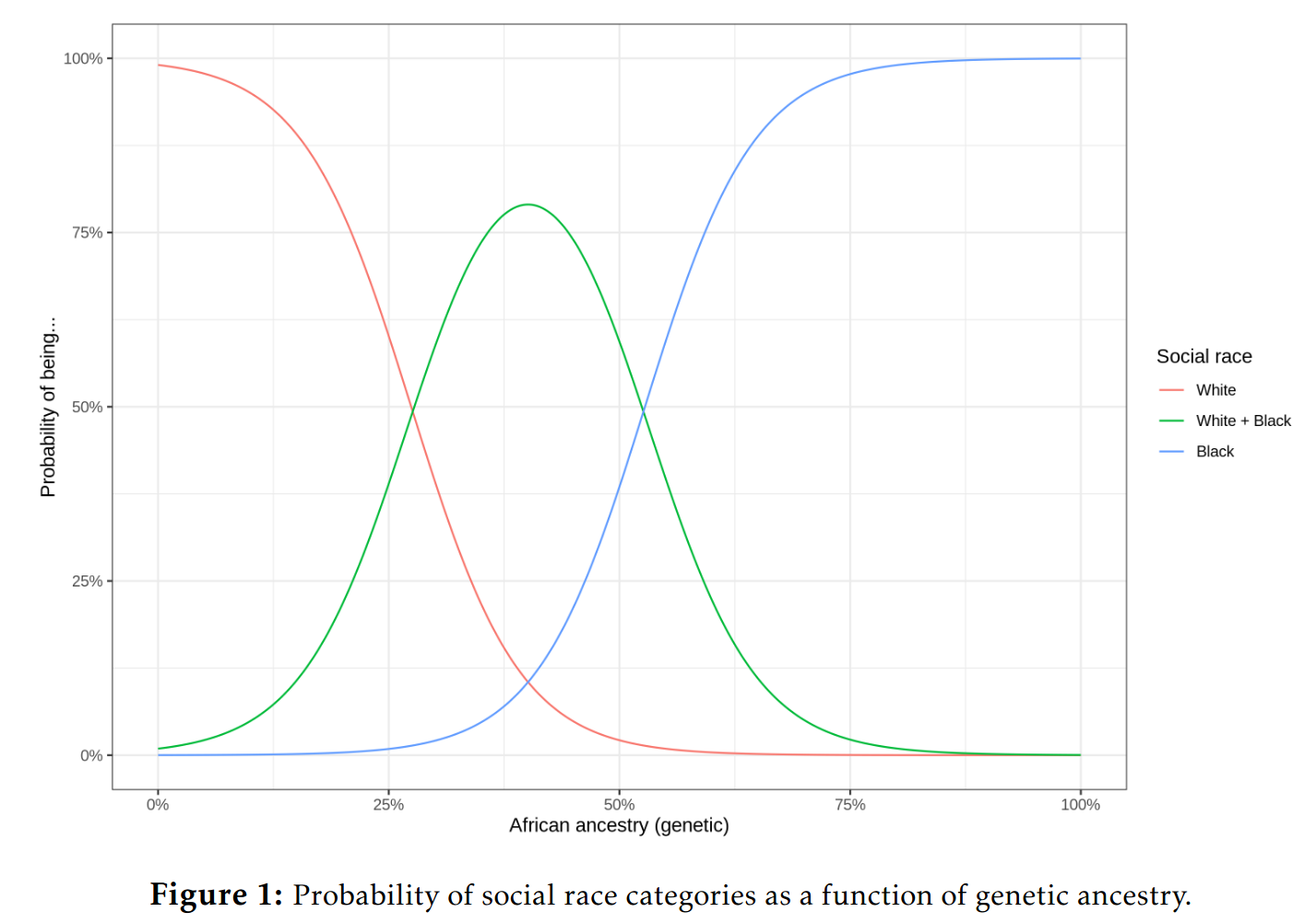
Zooming into the European-African groups, one can ask a logistic regression to predict the group membership:
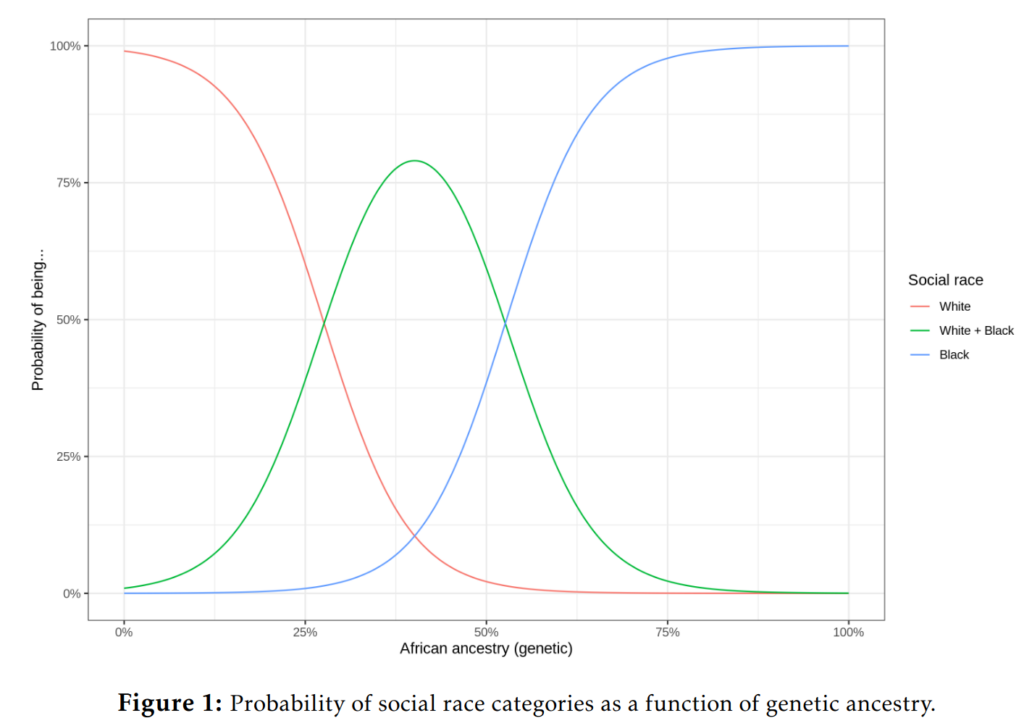
Confusion matrix for this model shows the errors are pretty understandable:
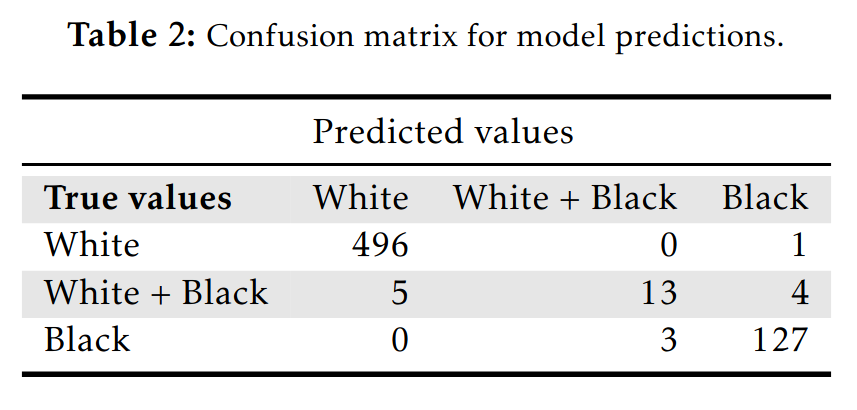
Of the 497 people who self or parent-identified as white, the model predicted 496 of them right, 1 was predicted to be black. So in other words, one person was misclassified in this situation, giving an accuracy of 496/497=99.8%. This doesn’t even mean it is an error. This value is so low that maybe this person just filled out the questionnaire wrong. The other errors are similar in nature. There is a group of persons who socially identify as black and white, and whose genetic ancestry is intermediate. Sometimes the model would assign these to the only-white or only-black categories, but out of these 22 persons, 13 were still assigned correctly. This accuracy of 59.1% sounds bad but that’s when you forget the base rate here is 22/649=0.034 (3.4%). For the blacks, the model assigned 0 of them as only white, 127 as only-black and 3 as mixed. The accuracy of 97.7%. Overall, model accuracy was 98.0%.
Anyway, one can also predict genetic ancestry from social race with a linear model:
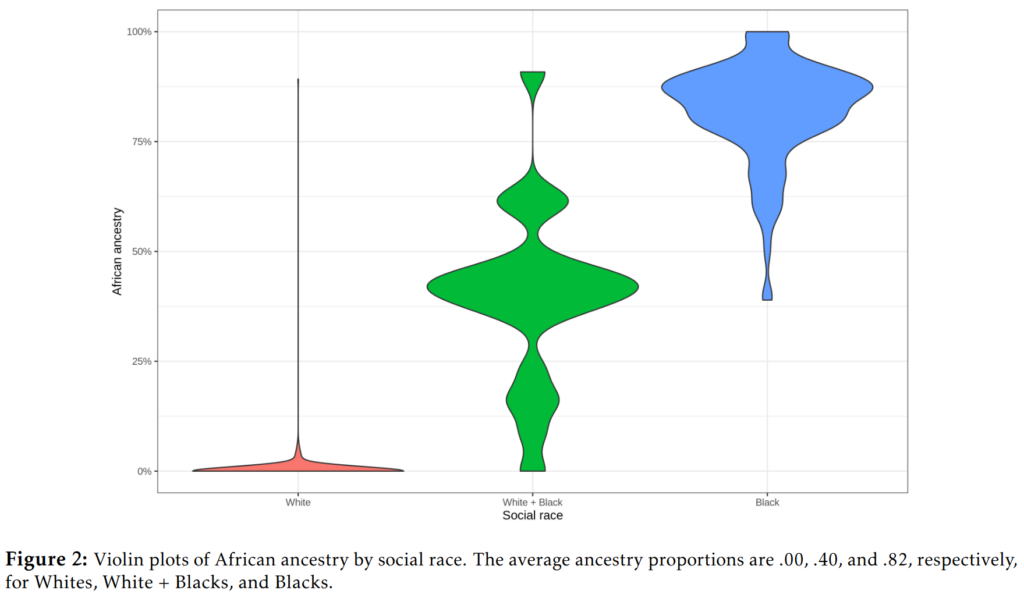
When we zoom out to the full sample, these are more complicated, we have to use fancy Dirichlet regression, which could look like this when visualized:
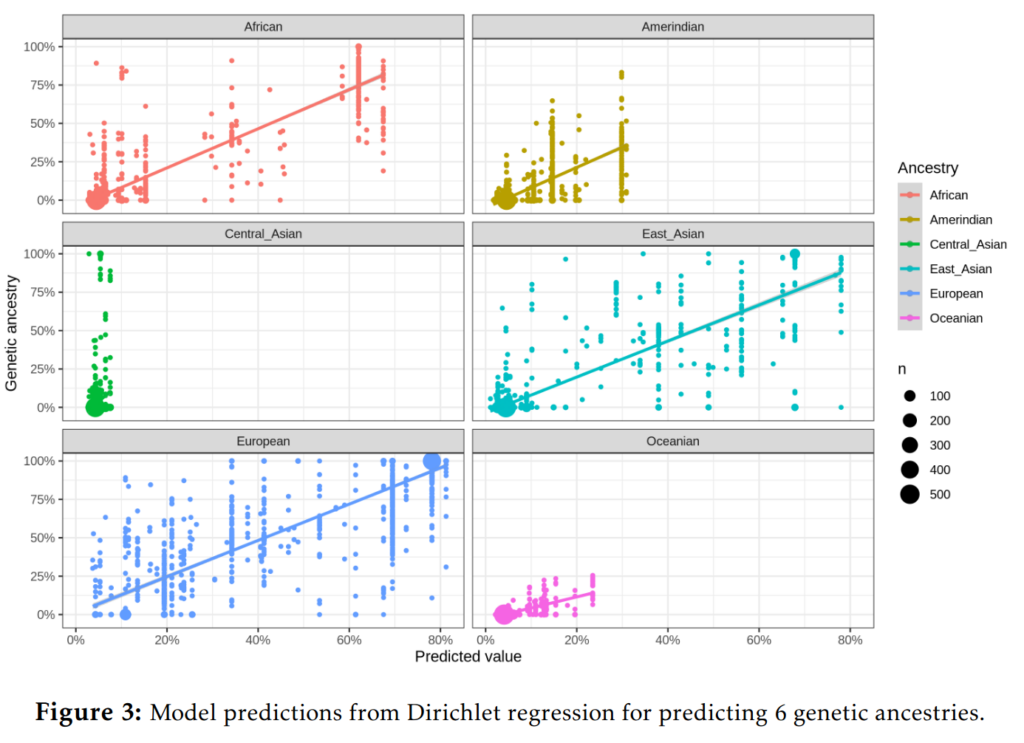
I leave the details here for the paper itself, but overall the model accuracy is extremely high by comparison with anything social science, rivaling even good medical tests. Social race classifications do a pretty good job of summarizing genetic ancestry, and vice versa.