I wanted to wait until all the US election stuff resolves, but seems like this will take a while for the last few questions, so let’s proceed for now. As mentioned in the Goals for 2020 post, I decided to get into forecasting because I found a funnier website than GJOpen: Metaculus:
I also want to commit to doing 100 forecasts on Metaculus. I am at 6 right now, began a few days ago. My profile is in my own name, so let’s see if I have what it takes. This site is probably mainly used by fairly nerdy and good forecasters, so I don’t expect to be anywhere close to the top. This is a cooler alternative to Good Judgment Project (https://www.gjopen.com/). There’s also a few others like this worth mentioning: https://www.replicationmarkets.com/, and https://www.maby.app/. For the latter see their launch blogpost here, and our related but independent preprint on forecasting COVID consequences here.
So what are my stats now, close to year’s end?
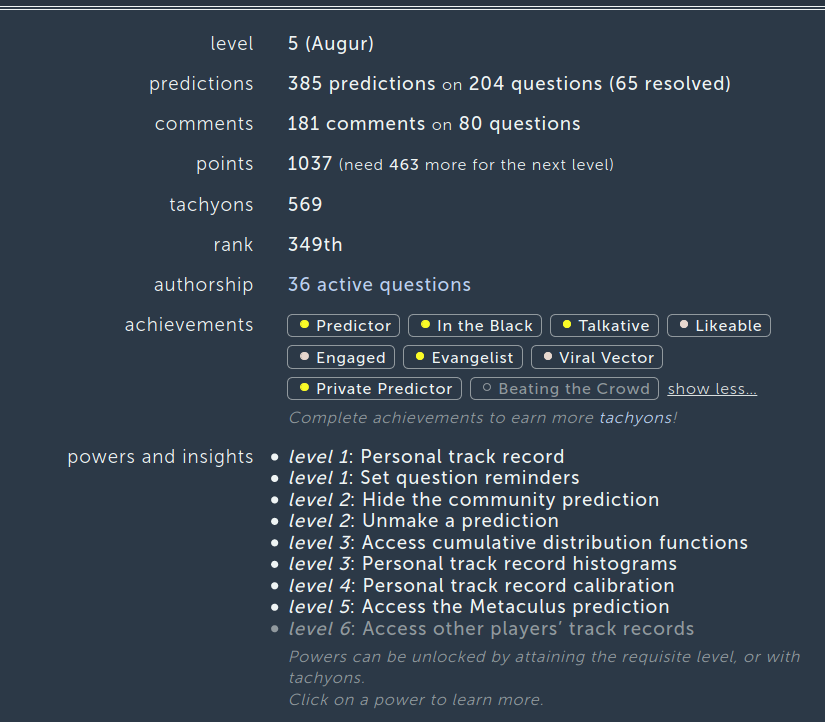
So, I did a lot more than 100 forecasts (385) on ~200 different questions (the rest are updates). 65 of these have resolved (some with ambiguous status). I am now the 349th ranked user on the site (toplist found here) according to the total points (this does not adjust for time spent on site). More interesting are the plots of results:
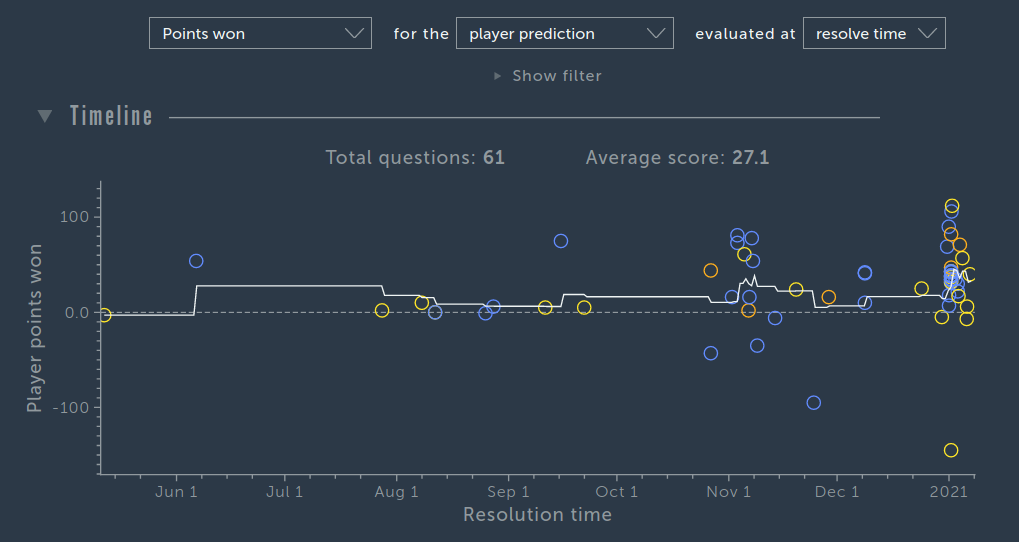
The site calculates points using some complicated formula that rewards 1) correctness, 2) beating the crowd, 3) forecasting in advance, and 4) making numerical predictions. Average points per question controls for number of questions resolves, but since longer running questions give more points (point 3 above), there is still some time spent on site confounding (my oldest predictions are about 6 months out). Nevertheless, if we compare this to the values for the top players, we get this:
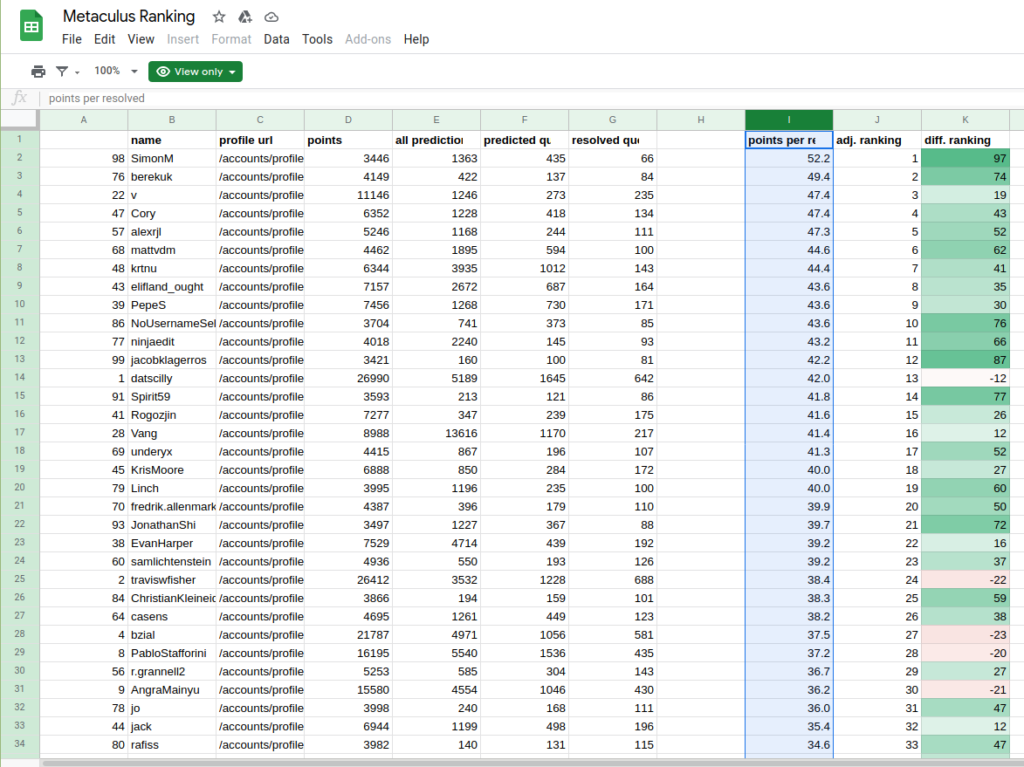
Scrolling to 27.1 average, we get my estimated position of top 66. This site has several thousand users I think, so I am very happy about this. Probably my rank is too good because I will likely lose a lot on this Trump question (If president Trump loses the 2020 election, will he concede?). I am locked in on 99% that he will, underestimating his narcissism I guess. The site’s algorithm is at 97%, so I am not out of line, but the community median is 75% at the closing of predictions (but at 90% when I made mine). So assuming it will resolve negatively (I think this is 80% likely now), I will be losing a lot of points for some overconfidence and not updating this value downwards as others did later.
Another metric is the Brier score, more known but ultimately not very interpretable. Worse, there are no guidelines for reasonable performance (0 = perfect, 1 = worst) or easy comparisons. Still, it looks like this, 0.119.
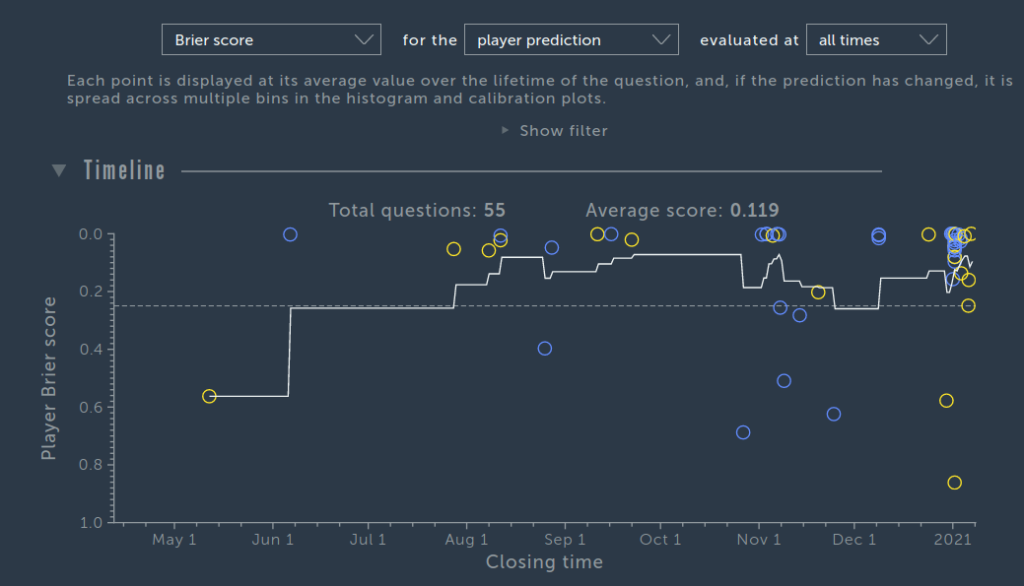
GJOpen has some data, but they use other questions, maybe harder.
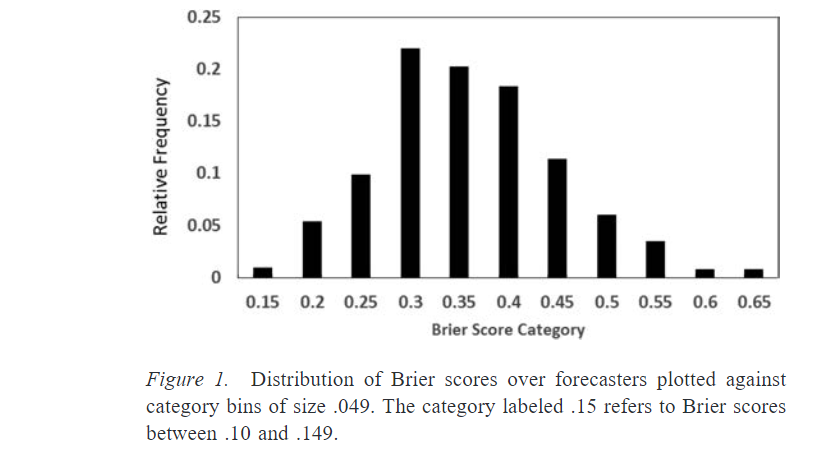
For this set of questions, guessing randomly (assigning even odds to all possibilities) would yield a Brier score of 0.53. So most forecasters did significantly better than that. Some people—the people on the far left of this chart, the superforecasters—did much better than the average. For example, in year 2, the superforecaster Doug Lorch did best with 0.14. This was more than 60% better than the control group.12 Importantly, being a superforecaster in one year correlated strongly with being a superforecaster the next year; there was some regression to the mean but roughly 70% of the superforecasters maintained their status from one year to the next.13
I do not believe I am better than their top forecaster, obviously. So I don’t know what to make of this comparison data unfortunately.
I asked long-term and top forecaster Jgalt to share his equivalent scores to mine above:
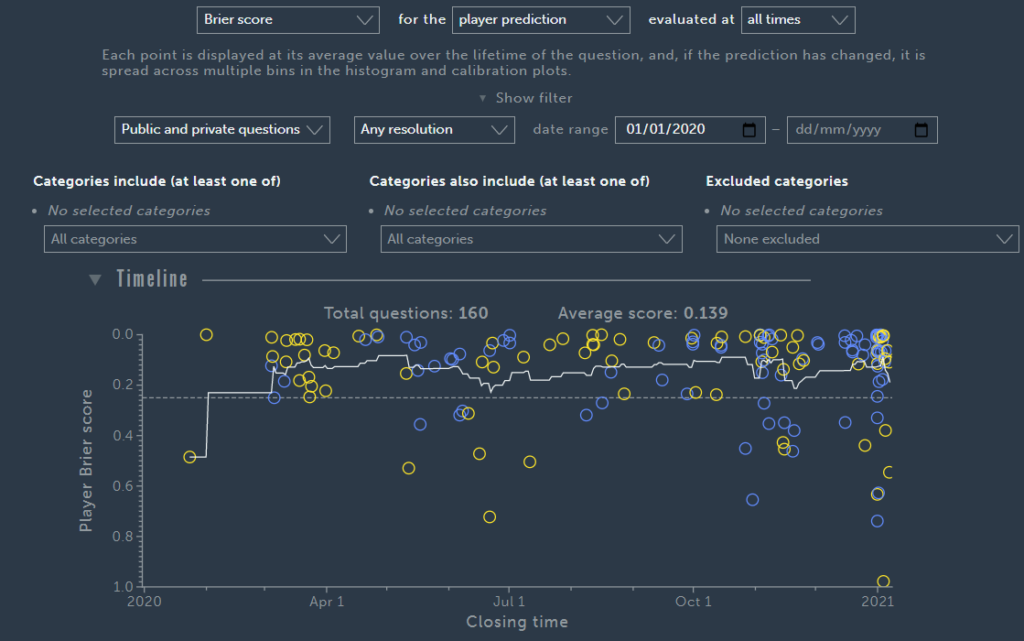
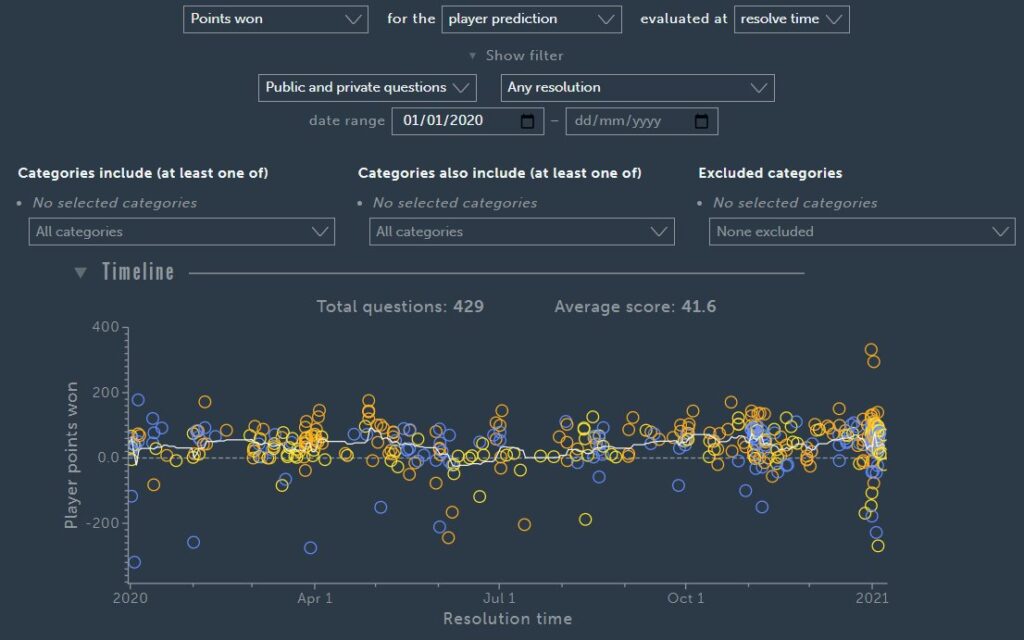
So I am actually beating Jgalt by Brier score but he is beating me by the points per question!
In terms of Trump, since a lot of people ask about these (though they are not a good measure of skill, too few questions, too specific!):
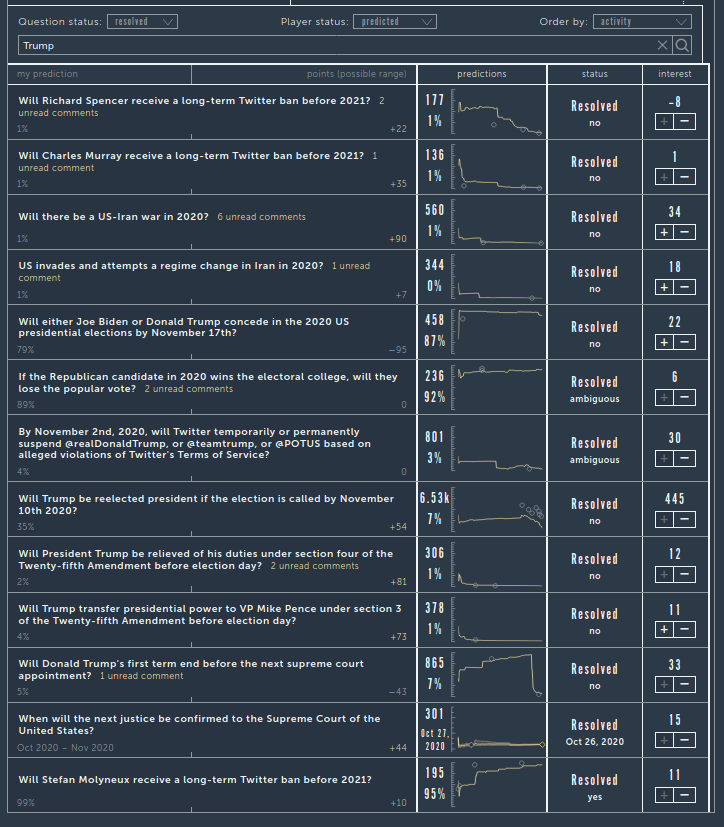
My predictions can be seen on the plots (the grey dots), the orange line is the site’s algorithm. The value on the far left is my final prediction (before it closed or resolved). So for instance, I gave Trump 35% chance of being re-elected. Overall, my predictions were alright. I expected the Senate to stay Republican (and it did), but I also expected it to stay Republican in the Georgia runoff but Dems seem to win both seats. Some results:
Electoral votes
Some people have requested these. If we use the current public results (virtually guaranteed): Biden has 306 to President Trump’s 232 (AP). My median values were: 284 and 216. Unfortunately, these values are impossible: the sum is 500 but should be 538. This is because the site used two different questions, so the sum was not forced to equal 538. Luckily, we can simply fix this retrospectively by adjusting my numbers for this error. The adjusted numbers are: 284*(538/500)=305.6 and 216*(538/500)=232.4. These are exactly the final values. Of course, this is somewhat of a lucky coincidence, but it is nevertheless fun! My numbers got the exact right ratio of the the electoral votes between the parties.
Personal predictions
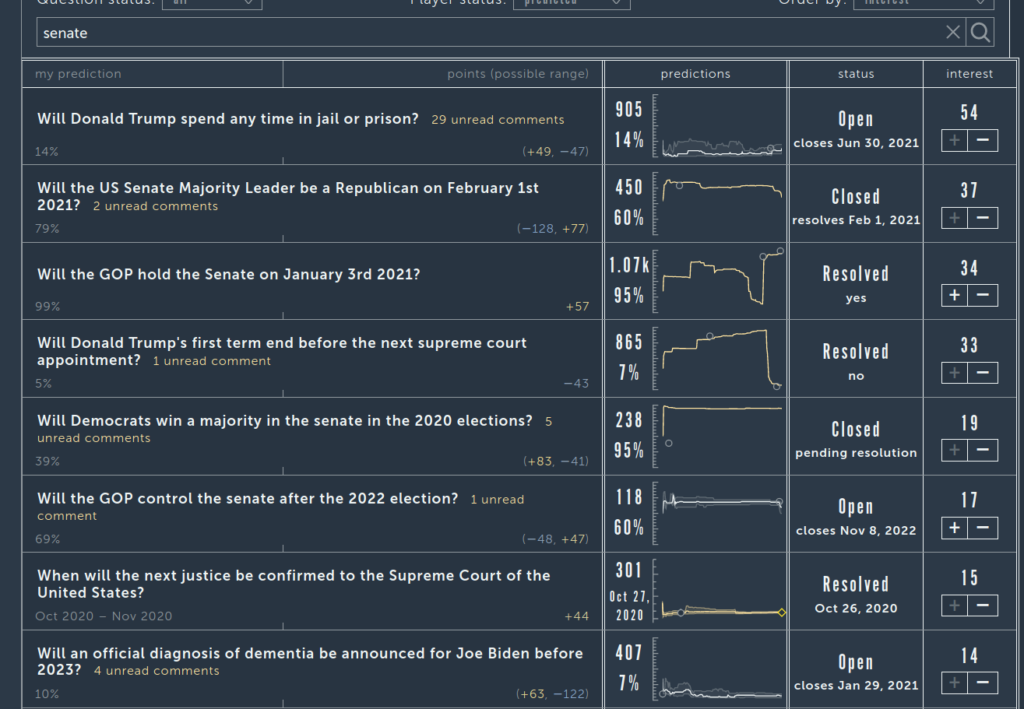
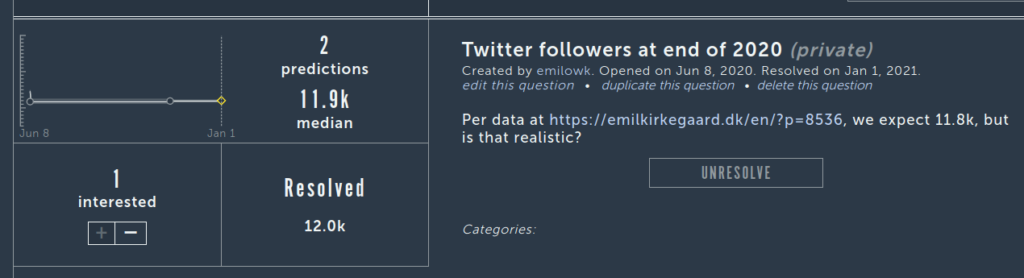
Moving beyond all this election talk, I made some private predictions (included above) about my own progress. Twitter followers:
Youtube subscribers:
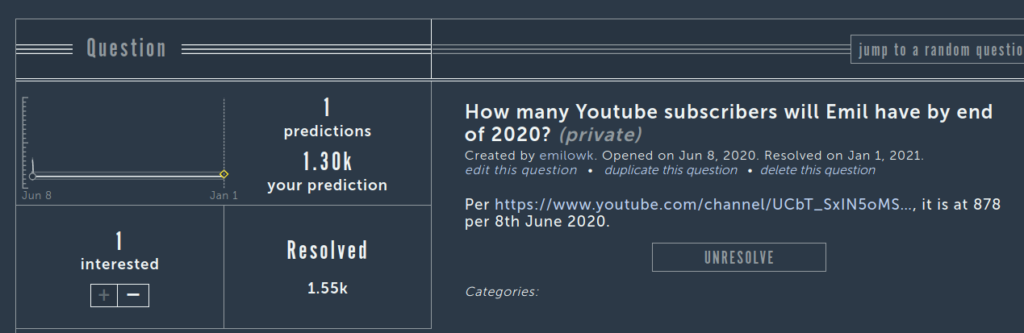
These quantitative predictions turned out to be remarkable accurate even when made half a year in advance. Apparently, these things are easy to project with simple statistical models. Blogposts, I didn’t make one for Metaculus (no reason why that I can recall):
I don’t really recall the reason why it varies so much over the years. The extrapolation to 114 seems pretty dangerous given the previous 4 years averaged close to 80! Well, set difficult goals, they say, so 114 it is. I think I have generally moved a lot of my writing to formal papers, so let’s go there.
Using the archive page, we can see the number was… 117. I actually did not cheat and try to match it up.
Papers:
So far this year, I am at 6. So the usual extrapolation gives us expected value of 21ish. Way too high. 10 seems like fairly safe bet, but 15 is possibly doable if I include some decent preprints in the count. I have 2 reviewed papers coming out this summer issue of MQ, but one of them is already counted above as a preprint. I imagine another 2-3 in the autumn and winter issues. Have 2 papers in review at Intelligence, not sure if they will get through the censors.
The number according to the frontpage is 12, and ResearchGate is 13.
In the next post, I will make new predictions like the above for 2021, hoping to make them at least 11 months in advance for more difficulty!


