

Back in October Razib Khan had Carole Hooven on his podcast. She’s the author of a new popsci book on testosterone: T: The Story of Testosterone, the Hormone that Dominates and Divides Us (342 pages). In the book she mentions some other recent woke books on testosterone, specifically: Testosterone: An Unauthorized Biography (288 pages) by Rebecca M. Jordan-Young, and Katrina Karkazis. So I decided to read both to see what each party in this battle are talking about. You can probably guess what happens next.
Woke
The woke book is a frustrating read because it’s so full of political whining. There are 16 counts of “racism”, 22 of “political”, 19 of “racis” and so on. Often you find yourself wishing the authors would just get to the next point instead of yet another paragraph of no scientific content. But the book is not all like this. I learned quite a bit. One has to be careful about the strength of the evidence. For instance, speaking of testosterone and violence:
And yet gold standard studies consistently have found T to have no effect on aggressive behavior or feelings: these are double-blind, placebo-controlled studies in which neither the investigator nor participants know who is getting T versus an inert substance. A number of such studies have involved raising T to supraphysiological levels (that is, well beyond the upper limit of the range seen in healthy men), and have also included asking the men themselves as well as significant others to report on the men’s mood and behavior. No effect of T on aggression, anger, or hostility has been observed in the studies that have used this design. But at present, researchers still read the overwhelmingly negative evidence on T and human aggression as “weak and inconsistent,” seeing in that an intriguing doorway to new knowledge rather than an indication of a dead-end street.6
“gold standard studies consistently”. Sounds like strong evidence! What is in footnote 6?
6. Examples of placebo-controlled studies that find no link include Ray Tricker, Richard Casaburi, Thomas W. Storer, et al., “The Effects of Supraphysiological Doses of Testosterone on Angry Behavior in Healthy Eugonadal Men—A Clinical Research Center Study,” Journal of Clinical Endocrinology and Metabolism 81 (1996): 3754–3758; Daryl B. O’Connor, John Archer, and Frederick W. C. Wu, “Effects of Testosterone on Mood, Aggression, and Sexual Behavior in Young Men: A Double-Blind, Placebo-Controlled, Cross-Over Study,” Journal of Clinical Endocrinology and Metabolism 89 (2004): 2837–2845. There are a few exceptions to the general pattern that exogenous T in placebo-controlled trials does not increase aggression, but those findings should be viewed with some skepticism. For instance, Pope, Kouri, and Hudson report that exogenous T increased aggression, but the aggression measure that was linked to higher T in their study was a computer game (the point-subtraction aggression paradigm, PSAP), which was only linked to T in a subsample of twenty-seven men, while scores on aggression measures that were used in the entire sample of fifty-six, including a validated measure of aggressive actions and feelings and an assessment by significant others, were not associated with T. Harrison G. Pope, Elena M. Kouri, and James I. Hudson, “Effects of Supraphysiologic Doses of Testosterone on Mood and Aggression in Normal Men—A Randomized Controlled Trial,” Archives of General Psychiatry 57 (2000): 133–140. Another study found that exogenous T was linked to more “aggressive” play on the PSAP, but only among men who scored high on a “dominance” measure or low on a “self-control” measure. Even so, the effects were quite modest: “Collectively, the trait dominance by drug condition and trait self-control by drug condition interactions accounted for 8.8% of the variance in aggressive behavior.” Justin M. Carré, Shawn N. Geniole, Triana L. Ortiz, et al., “Exogenous Testosterone Rapidly Increases Aggressive Behavior in Dominant and Impulsive Men,” Biological Psychiatry 82 (2017): 249–256.
Let’s look at them:
- First study is a study from 1996, with n = 43.
- Second study from 2004 has n = 28.
- Third study from 2000, n = 56.
- Fourth study from 2017, n = 121.
So by sample sizes alone, we don’t really care too much about the oldest smallest studies. The technology was worse back then and the sample sizes mean statistical power is very low, so we cannot interpret p > .05 findings as supporting the null very strongly. Their summary of the third study is odd. Here’s what the results say “Testosterone treatment significantly increased manic scores on the YMRS (P = .002), manic scores on daily diaries (P = .003), visual analog ratings of liking the drug effect (P = .008), and aggressive responses on the Point Subtraction Aggression Paradigm (P = .03).”. The last finding is probably just p-hacking but the other p values are quite small. The last study is a single dose of T and then looking for immediate effects. They report some interactions effects with p < .01, but we are extra suspicious about interaction effects so what can we make of these 4 studies chosen? Not much. It’s odd then that the authors describe them as “consistently have found T to have no effect on aggressive behavior or feelings”. Rather, the studies here are too small to show anything consistently.
One thing that runs through the entire book is the meta-analysis style of the 1970s I/O psychology: the narrative review. Small studies with ‘conflicting findings’ are interpreted as showing that matters are really very complicated. What works in one study, doesn’t work in the next despite their similarity. There is no realization that low powered studies will not paint any consistent picture in terms of p values being below or above .05 even when reality is 100% consistent. Statistical power is never mentioned in the book, neither is the idea of a false negative. Schmidt and Hunter (1998) provides the historical background in the I/O psychology area:
Research studies assessing the ability of personnel assessment methods to predict future job performance and future learning (e.g., in training programs) have been conducted since the first decade of the 20th century. However, as early as the 1920s it became apparent that different studies conducted on the same assessment procedure did not appear to agree in their results. Validity estimates for the same method and same job were quite different for different studies. During the 1930s and 1940s the belief developed that this state of affairs resulted from subtle differences between jobs that were difficult or impossible for job analysts and job analysis methodology to detect. That is, researchers concluded that the validity of a given procedure really was different in different settings for what appeared to be basically the same job, and that the conflicting findings in validity studies were just reflecting this fact of reality. This belief, called the theory of situational specificity, remained dominant in personnel psychology until the late 1970s when it was discovered that most of the differences across studies were due to statistical and measurement artifacts and not to real differences in the jobs (Schmidt & Hunter, 1977; Schmidt, Hunter, Pearlman, & Shane, 1979). The largest of these artifacts was simple sampling error variation, caused by the use of small samples in the studies. (The number of employees per study was usually in the 40-70 range.) This realization led to the development of quantitative techniques collectively called meta- analysis that could combine validity estimates across studies and correct for the effects of these statistical and measurement artifacts (Hunter & Schmidt, 1990; Hunter, Schmidt, & Jackson, 1982). Studies based on meta-analysis provided more accurate estimates of the average operational validity and showed that the level of real variability of validities was usually quite small and might in fact be zero (Schmidt, 1992; Schmidt et a]., 1993). In fact, the findings indicated that the variability of validity was not only small or zero across settings for the same type of job, but was also small across different kinds of jobs (Hunter, 1980; Schmidt, Hunter, & Pearlman, 1980). These findings made it possible to select the most valid personnel measures for any job. They also made it possible to compare the validity of different personnel measures for jobs in general, as we do in this article.
Contrast this to the typical claims in the book about the effects of T:
WE DON’T SCRUTINIZE every aspect of every study—exhaustive forensic examination is not necessary to see how the widely accepted idea that T drives human violence is, at the very least, grossly overblown. The very same researchers who have helped to establish the fact status of the connection between T and human aggression have acknowledged for decades that this link is “tenuous,” “weak and inconsistent,” “inconclusive,” and “elusive.”
Again later:
Kreuz and Rose set out to test the idea that aggressive prisoners would have higher T levels than nonaggressive prisoners. They selected twenty-one inmates and divided them into two groups, “fighters” and “nonfighters.” “Nonfighters” were reported to have been in one or no prison fights; “fighters” had to have been in two or more. Three different aggression scores were calculated for each inmate. The first score was culled from prison records and included items you might expect, such as physical fights, making threats, or destroying property, but also some items that you might not expect in an inventory of violent behavior, such as cursing or refusing to obey officers. The second set of data came from three standardized, written psychological tests to assess things like subjective feelings of aggressiveness. Finally, they looked at past criminal offenses, including the type of offense, frequency of offending, and age at each offense. All told, they examined close to two dozen behavior measures in the sample of just twenty-one men. And then there was the testosterone. To make sure they got reliable T measures, they drew each man’s blood multiple times, always first thing in the morning to control for T’s diurnal rhythm. This was considered top-notch research at the time: they were being very thorough, and if there was a relationship between T and aggression, they were bound to find it.10
A study of 21 prisoners is not ‘bound to find’ a statistical link at p < .05 if it exists. The authors describe this study as a “landmark study”, whereas to a reasonable reader, it is more of a historical curiosity in terms of utility. The authors are right, again, that this particular 1972 study is not convincing of much of anything. Here’s their results table:

So 8 tests, one with p < .01, this is shrug tier stuff. They go on with more studies like this, such as the n = 89 study by Dabbs from 1987. What is the point of this stuff? The proper evidence to look at is a quantitative meta-analysis. These do exist. I checked on Google Scholar. For instance:
Book, A. S., Starzyk, K. B., & Quinsey, V. L. (2001). The relationship between testosterone and aggression: A meta-analysis. Aggression and Violent Behavior, 6(6), 579-599.
In non-human animals, the relationship between testosterone and aggression is well established. In humans, the relationship is more controversial. To clarify the relationship, Archer conducted three meta-analyses and found a weak, positive relationship between testosterone and aggression. Unfortunately, each of the analyses included only five to six studies. The aim of the present study was to re-examine the relationship between testosterone and aggression with a larger sample of studies. The present analyses are based on 45 independent studies (N=9760) with 54 independent effect sizes. Only studies that reported a p-value or effect size were included in the analyses and the sample may underestimate the proportion of non-significant findings in the population. Correlations ranged from −0.28 to 0.71. The mean weighted correlation (r=0.14) corroborates Archer’s finding of a weak positive relationship.
And this is from 2001, obviously the authors could have found it and discussed it, but they didn’t. This is an expansion on a prior meta-analysis from 1998, not cited by the authors either. There’s a more negative 2020 meta-analysis, authors could not have included it as their book is from 2019. The point is that they are trying to do a narrative review of studies based on p values without an understanding of statistical power, and this approach is hopeless.
One of the most interesting studies they discussed is:
To answer these questions, Dabbs and Morris used data that had been collected by the US Centers for Disease Control and Prevention (CDC) for a prior study of nearly 4,500 US veterans of the Vietnam War. The original study was a wide-ranging examination of the long-term effects of military experience for these veterans, but Dabbs and Morris scoured the dataset for all indications of what they called “antisocial” behavior, a broad category that encompassed everything from “having trouble with parents, teachers, and classmates” to assaulting other adults, going AWOL in the military, using drugs and alcohol, and having a larger number of sexual partners. Echoing the way that T and criminal violence were sutured together in the studies on prisoners, Dabbs and Morris use several strategies to assemble the connections between T, social class, and bad behavior. By stepping away from a narrow focus on criminality or even on violence to the broad notion of “antisocial behavior,” thus exponentially expanding the number of variables and statistical analyses, they almost guaranteed that they would find some relationship. They concluded that high T is a direct cause of antisocial behavior, but that the relationship is strongest among men of lower socioeconomic class.22
This is the same dataset I have been publishing on the last couple of years (1, 2, 3) with the very same Helmuth Nyborg they complain about (he gets 9 mentions!). It’s impressive large, so if someone looked at it, and found relationships, it is hard to get around. The authors rightly complain about some poor choice of methods in the study (from 1990). However, instead of re-analyzing the dataset (which is now public and which before could be gotten by emailing people for a copy), they leave it as the complaints. I call this lazy criticism. First, let’s look at the actual results by Dabbs:
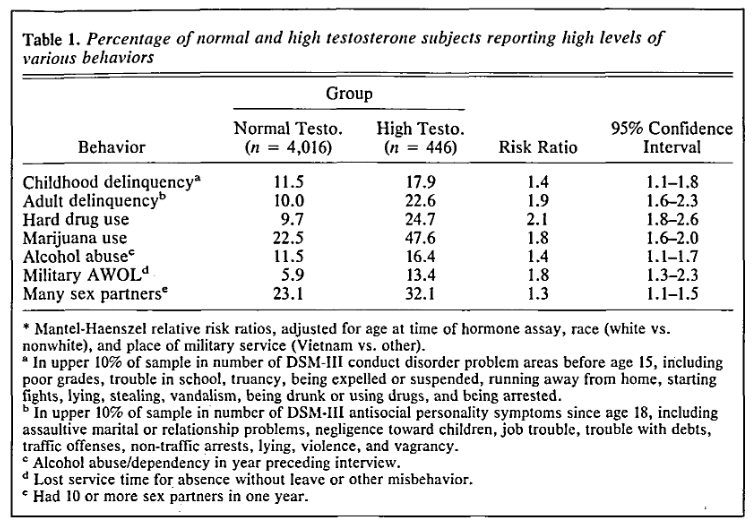
OK, so there are 7 tests, of which 7 are p < .05. This conflicts with the authors take where they describe this as a typical fishing expedition study like that of the 21 inmates above (1 of 8 tests with p < .05). The non-findings of a relationship among the higher SES men is also not a surprise when you look at the table:
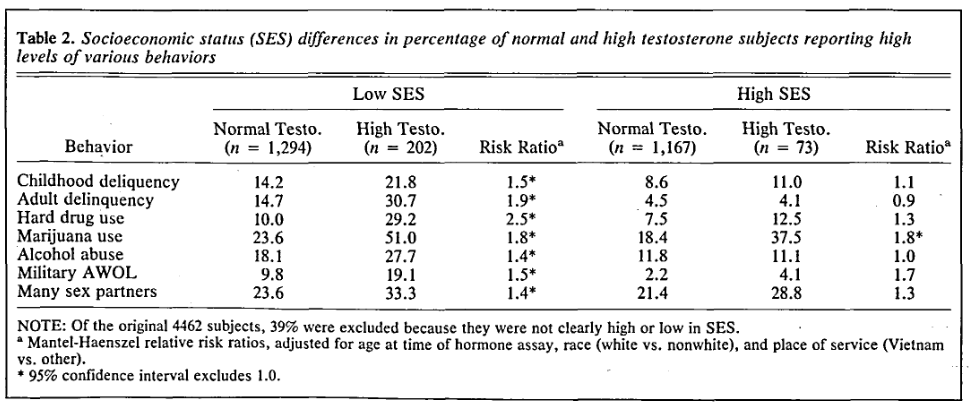
The sample size of high SES men with high SES is only 73, and there was 1 ‘hit’ out of 7 tests. It means nothing, a regression analysis is needed here, which is also what the authors advocate. The bigger problem with the study is that there are no statistical controls for race and age. Africans are of course higher in every kind of antisocial behavior and also in testosterone levels, so this presents a potential confound. Anyway, so I spent an hour or so recoding variables in the dataset, and was able to repeat most of the 1990 Dabbs analysis but done properly. First, the correlation matrix:
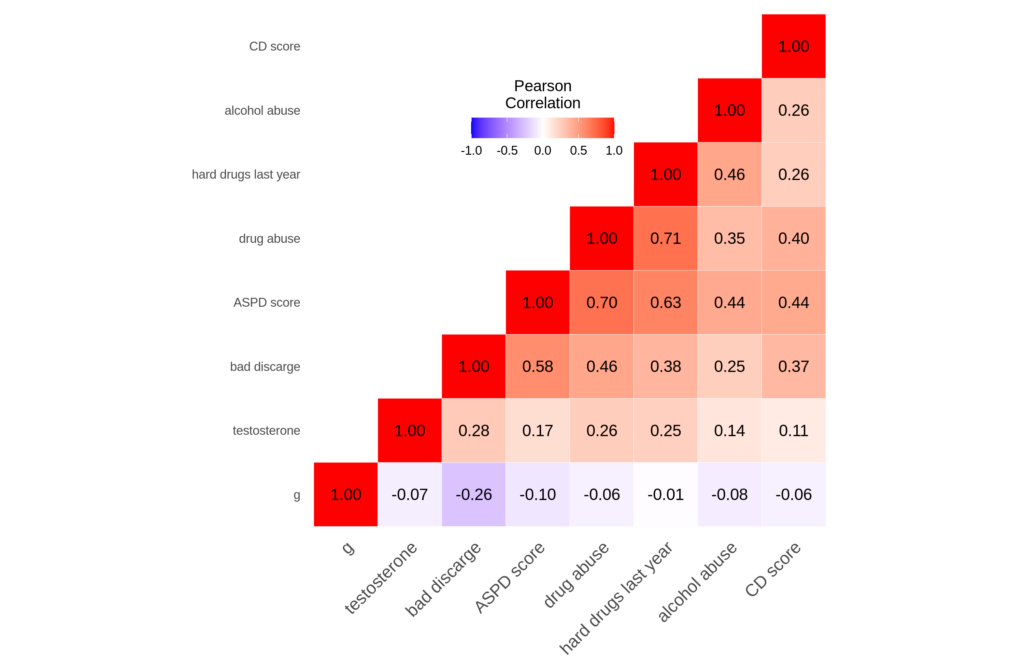
So we see that Dobbs was right. All the bad behaviors are correlated with one another and with testosterone. Thus, one can speak of a general factor of antisocial behavior, as I have also demonstrated previously in the OKCupid sample. For good measure, we also see that intelligence relates negatively to all of them. What if we control for age, race, and SES?
| Predictor/Model | 1 | 2 | 3 | 4 |
| Intercept | 3.15 (0.225, <0.001***) | 2.43 (0.219, <0.001***) | 3.12 (0.225, <0.001***) | 2.39 (0.218, <0.001***) |
| age | -0.08 (0.006, <0.001***) | -0.06 (0.006, <0.001***) | -0.08 (0.006, <0.001***) | -0.06 (0.006, <0.001***) |
| race=Black | 0.29 (0.045, <0.001***) | 0.16 (0.044, <0.001***) | 0.24 (0.049, <0.001***) | 0.28 (0.047, <0.001***) |
| race=Hispanic | 0.04 (0.070, 0.557) | -0.04 (0.067, 0.578) | 0.01 (0.071, 0.89) | 0.04 (0.068, 0.53) |
| race=Asian | -0.13 (0.177, 0.462) | 0.00 (0.169, 0.985) | -0.13 (0.177, 0.463) | 0.03 (0.169, 0.869) |
| race=Native | 0.75 (0.139, <0.001***) | 0.60 (0.134, <0.001***) | 0.74 (0.139, <0.001***) | 0.61 (0.133, <0.001***) |
| testosterone | 0.17 (0.015, <0.001***) | 0.13 (0.014, <0.001***) | 0.17 (0.015, <0.001***) | 0.13 (0.014, <0.001***) |
| SES | -0.36 (0.019, <0.001***) | -0.44 (0.022, <0.001***) | ||
| testosterone * SES | -0.11 (0.018, <0.001***) | -0.13 (0.021, <0.001***) | ||
| g | -0.04 (0.016, 0.011) | 0.12 (0.017, <0.001***) | ||
| testosterone * g | -0.01 (0.014, 0.431) | 0.04 (0.016, 0.026) | ||
| R2 adj. | 0.101 | 0.176 | 0.103 | 0.186 |
| N | 4272 | 4271 | 4272 | 4271 |
So, 4 models. In the first and simplest, we just regress this general factor of bad behavior on testosterone, race, and age. We find that testosterone has half-decent beta at 0.17, p < .001. Model 2: we throw in SES and its interaction with T, but T itself remains sizable (0.13), and indeed we see that at higher SES, it is much weaker (interaction is negative). Model 3: We also try intelligence (g), and it is a surprisingly weak predictor despite being negatively related to each variable (as we saw above), including T. Still with p = .011, it is not entirely useless here. Model 4: Finally, we control both SES and g and add their interactions with T, we get the very weird situation where g predicts bad behavior positively at beta 0.12 (p < .001), in what is maybe the first study! What is happening here is collider bias because we control for SES I think. T and g might interact positively to predict crime, p = .026 but our sample size is too small to really say for sure. This curiosity aside, T remains a decent predictor in every model: beta 0.13-0.17 So, the relationship is not “weak and inconsistent”, but very consistent when you have a large sample. Weak depends on comparison to other variables. What we have here is a one-time blood measurement of T, and we are interested in a batch of bad behaviors. It is not surprising the relationship is only weak as no one really thinks that a single snapshot of T level provides that much information about T’s lifetime influence on that person (this includes effects on organizing the brain in utero). This small study needs some expansion and a publication, which I will look into probably next year. Email me if you are interested in working on this with me.
An interesting part of the authors anti simple T models approach is that they spend a lot of time taking issue with… power posing!
The idea behind power posing has a potentially even more revolutionary message: T is already as much feminine as masculine, a resource that anyone can call on from within their own bodies. The fantasy version of power posing thus queers T and makes endogenous T as well as pharmaceutical T into a technology with the potential to elicit and legitimize new arrangements and relationships between the categories of “masculinity” and “femininity,” between social status and power, and between bodies themselves. But this fantasy requires a predictable chain of reactions—from a powerful pose to a rise in T to a range of effects that this rise would supposedly have—and that’s not the way T works. T is responsive, but it’s not a simple switch. Moreover, the last step in the chain, where elevated T supposedly cements one’s powerful position, is broadly inconsistent with human evidence.
OK, this paragraph is nonsensical, but in general, they do into the replication failures of power posing. As a matter of fact, the authors do understand p-hacking, and point out problems when studies look p-hacked, as the study of 21 inmates above. Amy Cuddy proposed T as a mediator of her power posing, and this claim of course did not replicate.
Next, the authors take issue with some student study of T (n=110 MBA students). The study itself it not so interesting (looks like a waste of time, in fact, with a main finding of a p = .08 interaction), but they write:
But what, exactly, is the concept of risk that runs through these literatures? Leaning hard on previous studies by James Dabbs, especially the study of army veterans that Dabbs used to link higher T to lower social class, White and colleagues assert that “the preponderance of evidence supports a relationship between T and occupation.” Their breezy tour through Dabbs’s findings reasserts the idea that higher T leads to “blue collar” occupations, while lower T leads to “white collar professions.” White and colleagues also highlight some interesting occupational contrasts from that study, such as the “male actors and professional athletes” who have higher T levels compared to “ministers and farmers.” We were intrigued by these groupings, and decided to go back to the study they came from. It turns out Dabbs and colleagues were also initially unsure what to make of them, writing, “We do not know how actors and football players are similar to one another and different from ministers. Nor do we know why the assertiveness of salesmen, the high status of physicians, and the sensation-seeking qualities of firemen were not reflected in higher testosterone.” As usual, though, these puzzling results were no match for Dabbs and his team, who quickly provided several possible explanations for their “negative findings.” Whenever men in characteristically aggressive, high-status, and sensation-seeking jobs had relatively low T, the researchers rationalized the illogical results. The salesmen in their sample, for example, “were not involved in aggressive ‘cold call’ selling, the physicians still had resident status, and the ‘sensation-seeking’ firemen spent more time waiting than fighting fires.” Why bother digging up lapses in logic from a study that’s three decades old? Because it is providing ballast for a much newer and frequently cited study.9
But there are associations with T levels and occupations! Again, the VES dataset can show this. They have occupations for the 4462 men, so we can compute occupational means. But we don’t have to because the very same Dabbs already did this in 1992!
Men with higher levels of serum testosterone have lower-status occupations, as indicated by archival data from 4,462 military veterans in six U.S. census occupational groups. This finding supports a structural equation model in which higher testosterone, mediated through lower intellectual ability, higher antisocial behavior, and lower education, leads away from white-collar occupations. The model is plausible because testosterone levels are heritable and available early enough to affect a number of paths leading to occupational achievement. Prior research has related testosterone to aggression in animals and men, and high levels of testosterone presumably evolved in association with dominance in individual and small-group settings. It appears an irony of androgens that testosterone, which evolved in support of a primitive kind of status, now conflicts with the achievement of occupational status.
And the key figure:
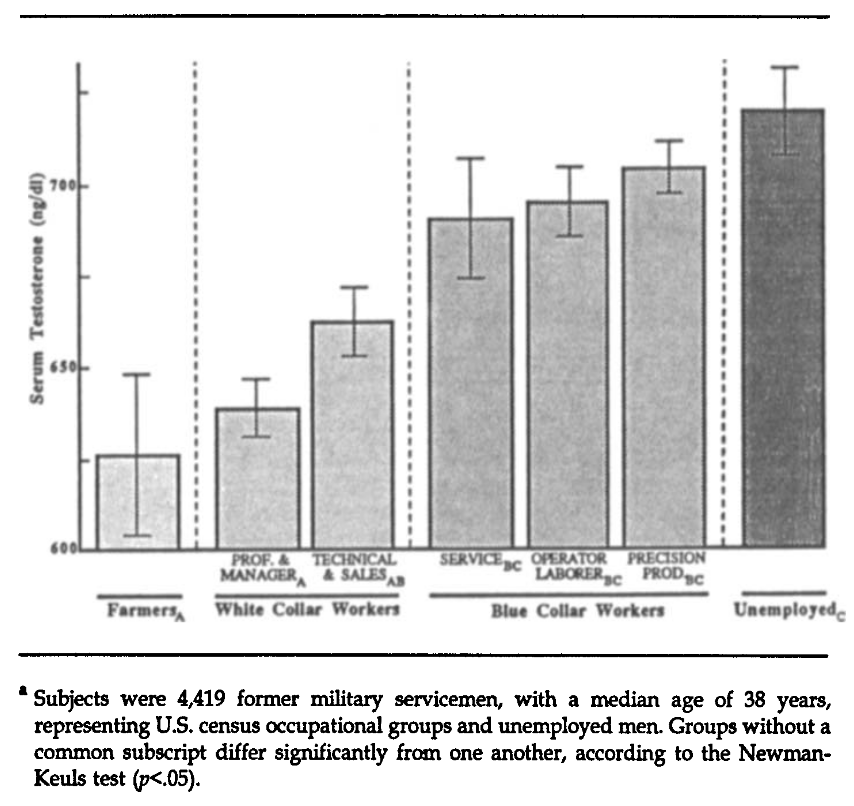
I looked too. I didn’t use the same 7 group split as Dabbs. There are 383 groups in the VES occupation standard classification (unfortunately without names on them). We can find the groups here. So this turned out to be a lot of work since I couldn’t find a ready-made conversion file BUT basically you can end up with a plot like this one:
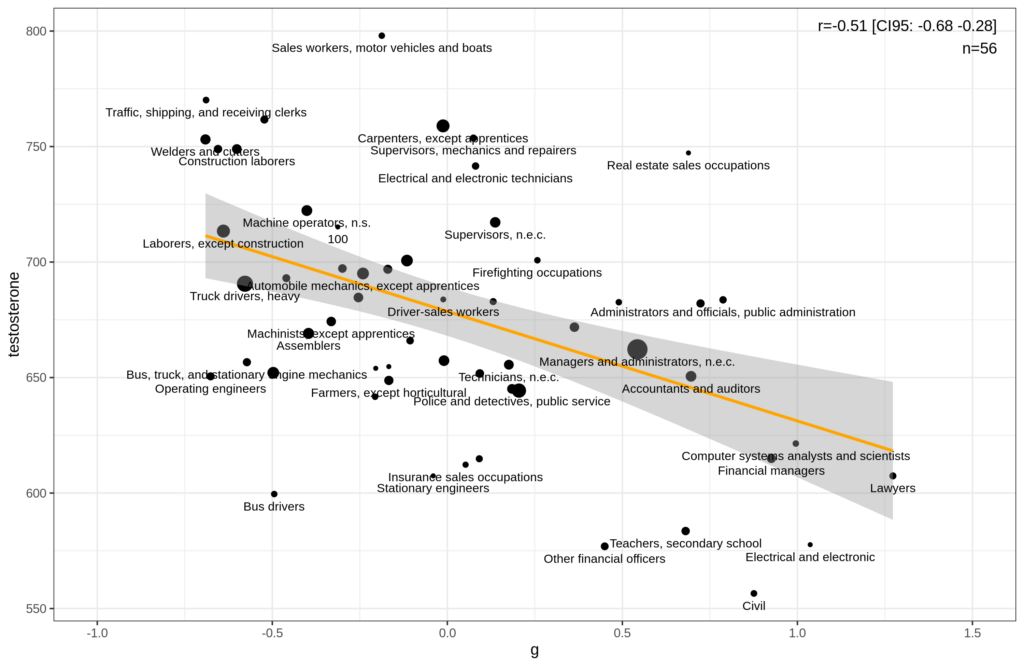
This is based on the occupations with at least 20 men in them. The correlation matrix looks like this:
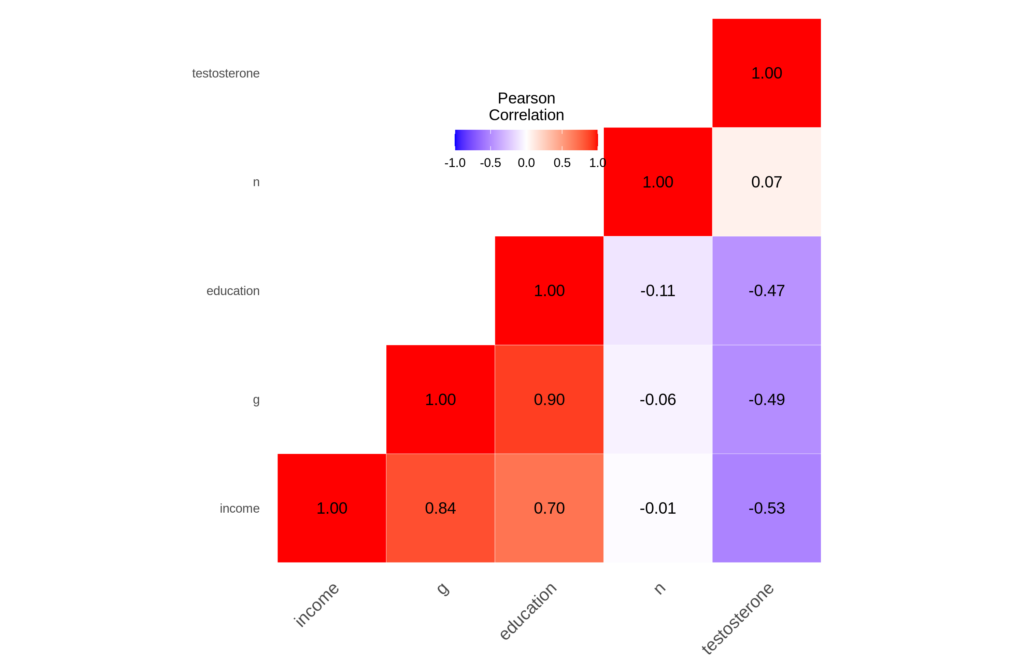
So while individual level T associations are weak, they are quite strong at the occupational level, and negatively so. Academia is definitely full of high g, low T men. Dabbs was right: testosterone levels seem counterproductive in our society judging from these data.
The authors next move is to attack r/K Rushton type thinking:
Ellis soon teamed up with another psychologist, Helmuth Nyborg of Denmark, to extend his analysis of racial differences and T. Based on a large dataset of health and social variables among Vietnam-era US Army veterans that had been collected by the US Centers for Disease Control and Prevention, Ellis and Nyborg reported that T levels were higher in black men relative to white men. The resulting paper, which does not mention r/K selection theory, has played an outsized role in linking T, race, and behavior because of the many citations it has garnered. In 1994, Nyborg built on his analysis with Ellis to elaborate how testosterone could serve as the linchpin for Rushton’s theory. Shortly thereafter Rushton endorsed this idea, writing, “One simple switch mechanism to account for a person’s position on the rK dimension is level of testosterone.”30
Ellis and Nyborg’s paper has reached its biggest audience by far via Allan Mazur and Alan Booth’s watershed 1998 article “Testosterone and Dominance in Men.” The various stories about T and behavior—dominance or its specific manifestation in aggression; aggression and its relation to crime, sexual behavior, reproduction, and more—all circle back on one another, with evidence about T’s relation to one held up as reason to suspect T will be involved in another. Thus, Ellis and Nyborg’s analysis of racial differences in T, which was crucial to Mazur and Booth’s story about high testosterone and the “honor culture” of young black men, secured a connection between the literature on racial differences in life history / mating / parenting strategies and the literature on dominance / violence / aggression.31
Another link in the racialized chain of associations with T repeatedly appears in this literature: racial disparities in health, especially prostate cancer. Sometimes the research on health is couched as evidence for race differences in r/K selection, and sometimes it is just a cover for looking at race and T in the first place. Either way, it’s a particularly sneaky move. An ardent disciple of Rushton, Nyborg extended r/K selection theory to link testosterone, supposed racial differences in intelligence, South-to-North immigration, and the “decay” of “Western civilization.” Yet while Ellis and Nyborg were both working on r/K selection theory, endorsing and amplifying some of the most noxious and baseless claims about racial inferiority of black people, they piously addressed readers’ potential concerns about the “propriety of probing into this sensitive area of research”: “We are aware that average racial / ethnic differences in testosterone levels may not only help to explain group variations in disease, but could also be relevant to group differences in behavior patterns, given that testosterone and its metabolites are neurologically very active. While cognizant of the possible misuse of information on race differences in sex steroids, we consider the prospects of beneficial effects to be much greater, particularly in the field of health. Nevertheless, especially in the short-run, scientists should be on guard against even the hint of any misuse of research findings in this area.” As historian John Hoberman noticed, “The threat of prostate cancer to black men turns out to have been only a prologue to a more ambitious theory of hormonal effects and the racial character traits to which they supposedly contribute.” Ellis and Nyborg’s analysis of racial differences in T is a staple in mainstream T research, and it would be worth revisiting their finding, especially given that of all the known covariates of T, especially diet and ratios of lean tissue to fat in body composition, they controlled only for age and body weight.32
There is not meat on the claims, however. No counterclaims, no evidence is cited. Still, they call other claims “baseless” and talk about “inferiority”, words never used by Ellis, Nyborg, or Rushton. Then follows some speculations on secret intentions. Very typical woke stuff, yawn. As for their objection, it makes no sense. Blacks are more obese than Whites in USA, which means their T levels are lowered by this confounding factor, if one wants to consider it that. So controlling for obesity or lean fat mass etc., would not work here to hide the gaps.
In the conclusion of the book, we see the usual ‘I don’t even want to cite it’ behavior:
Writing about this work presented us with similar challenges. Whether a citation is laudatory or outright condemnation, it underscores the importance of a piece of writing by showing that others have taken it seriously enough to engage with it. Links across studies lend each other mutual support, reinforcing the “fact value” of each through citation. We have opted to write about a number of egregiously racist studies in this chapter, especially, and wish that we could do so without citing them. As scholars, we need better strategies for responsibly identifying deeply problematic work without adding to its fact value.
We are already familiar with this with regards to poor Richard Lynn et al, whose national IQs must not be known about or cited. There used to be a map and table on Wikipedia with national IQs, as there is a map and a table with any other kind of national indicator without implying it is 100% correct. But woke editors removed these years ago, leaving the public to find less accurate data elsewhere. The 2017 version of the Nations and intelligence page can be seen here featuring the maps of national IQs.
Moving on from this chapter on aggression and T, they move on to sports. No one would be silly enough to deny the rule of T in sports? Heh:
At this writing, Usain Bolt is the fastest human in the world. But he isn’t the fastest at every race. In an interview in 2013, when Bolt was asked why he never runs the 800 meters, he responded, “I cannot run the 800, that’s out of the question.… I’ve tried it and trained and my PR [personal record] is like 2:07, and that’s really slow, like, a woman could beat me.” The interviewer laughed him off, saying, “You’re going to get in trouble for that!” But Bolt was serious: “It’s true, though—they could!” In fact, Bolt was understating the case. Visit Alltime-Athletics.com’s list of best women’s times for the 800 meters and jump to the very bottom of the list. There you will find a thirteen-way tie for 1,881th place (no, that’s not a typo), most recently run by Habitam Alemu of Ethiopia at the 2016 Rio de Janeiro Olympics. Her time was 1:58.99—or roughly eight seconds faster than Usain Bolt’s best. In 2018 alone, 498 women ran faster than Bolt’s best time, including nearly a hundred teenage girls. It’s not just elite women who are faster than Bolt in the 800 meters: the all-time world age best for a twelve-year-old girl is 2:06.90, a record held since 2009 by Raevyn Rogers (USA). It goes against all conventions of sports to say that these women are faster than Usain Bolt. But they are—in the 800 meters. It’s just not his race.6
Seems incredible but it checks out.
What about giving women T to boost their performance? Authors write:
UP TO NOW, we have mostly been talking about people’s endogenous T. When reviewing the mixed evidence about T’s contribution to building muscle, we discussed several studies where researchers administered T or placebo. Most of those studies included measures of strength as well as muscle mass, and as we noted, they show that exogenous T increases both muscle size and strength, especially when it is administered in large doses to otherwise healthy men and is accompanied by resistance training. But when any of those conditions are changed—the doses are lower, or the subjects already have low T levels or are elderly or are women—the effects of T on strength are less consistent. The key again is context and specificity. With a team including Shalender Bhasin, whose work confirmed that large doses of T can stimulate muscle development in men, Grace Huang recently conducted a randomized, double-blind trial of T administration in women. As with men, women who received high doses of T (but not lower doses) gained lean body mass and got stronger, but on only two out of five measures of functional strength. Why did high doses of T improve chest press strength, for example, but not leg press strength or grip strength? It probably has to do with the specific demands of particular measures of strength. Elsewhere, Bhasin has explained that “testosterone effects on muscle performance are domain-specific; testosterone improves maximal voluntary strength and power, but it does not affect either muscle fatigability or specific force.… Unlike resistance exercise training, testosterone administration does not improve the contractile properties of skeletal muscle.” Strength is multifaceted, and T doesn’t have a flat relationship across all different kinds of strength.21
The findings from studies of T’s effects on strength that we’ve reviewed are statements of averages, and statements about T’s effects under particular conditions of testing. Bhasin’s statement about the domain-specific effects of T on muscle performance would be more accurate if those conditions were made explicit: testosterone improves the average Western man’s maximal voluntary strength as tested in the laboratory, or testosterone improves certain measures of strength and power, but not all, in Western women who have had hysterectomies. This is not to nitpick, but to point out the importance of signaling the specific conditions in which relationships have been found—especially when there is evidence that the relationship doesn’t generalize to other contexts.
So are T and strength related? Yes. How? In complicated ways that researchers don’t yet understand, but surely not in a linear and predictable way. The bottom line on strength is that big doesn’t equal strong and T affects strength, but not the same way for every kind of strength or every body.
Another ‘everything is complicated’ story. OK, so what is the study here? It’s a 2014 study with… n=71 women. Again, authors unable to understand the concept of statistical power (or precision), since they keep accepting null hypotheses based on small studies and subgroups and what not. This is what makes the book frustrating to read. And the authors continue in the same style, even drawing philosophical conclusions from their inability to understand statistics:
This deep dive into some of the most well-accepted ideas about T and sports yields surprisingly little in the way of conclusive evidence about what T does, instead showing a potentially frustrating collection of highly specific facts that seem to resist synthesis. This dissonance is what happens when researchers with different basic objectives study T’s relationship to physical functions that are relevant to sport. They approach their studies with very different goals, from resolving the question of whether T therapy might counter frailty in the elderly, to learning which strength training programs might naturally boost athletes’ T, to seeking evidence that might support an embattled regulation on women athletes. These goals in turn shape the facts that emerge from studies: Who emphasizes group differences, and who reports on individual variability? Do researchers approach T as a trait that might predict something about physical competence, or are they interested in how T responds to training or competition, perhaps to tailor training programs?
The range and detail of facts that are available about athleticism and T can be overwhelming, partly because without having a specific purpose for the information, there’s no way to anchor a search through the data. Free-floating facts aren’t the same as evidence, because the latter implies a specific hypothesis or problem. This isn’t just about T, but about science in general. Several decades of research across multiple disciplines show that just as science is not unitary, neither are the facts that emerge from specific sciences, or even specific studies. This point is different from the observation that multiple studies addressing the same question yield different results. Some studies show that athletes who compete generally get a rise in T whether they win or not; other studies show that only the winners’ T goes up; the bulk of studies seem to show no change. Those studies can be relatively directly compared and synthesized through approaches such as meta-analysis. Likewise, we aren’t talking here about good versus bad science. In previous chapters, we’ve shown some dubious and even outright wrong scientific practices in high-profile research on T. A good example is Carney and colleagues’ work on power posing, where, among other things, they p-hacked, picking their variables after they had already looked at the data. Another is the famous study by Coates and Herbert, where they chose variables that don’t actually answer their research question. We are talking instead about the fact that “good” science, science that follows all the rules of good methods, will produce particular facts that don’t easily align.
Science studies scholars have increasingly appreciated that this entanglement between our research methods and research subjects means that the facts that emerge from different research programs might not just be different or partial, but might actually be irreconcilable. There is a well-worn metaphor about partial knowledge that tells of different blindfolded experts who must describe an elephant, each feeling a different part of the animal. The idea is that each one provides a correct description of the part they can feel, but that each partial description is profoundly misleading to someone who needs to understand an elephant. As we said in Chapter 1, though, we are talking about an even deeper dilemma. The understandings that emerge from different scientific approaches can’t just be added up to make one coherent whole. And that’s because in the elephant metaphor, the blindfolded expert doesn’t transform the elephant: she merely conveys what is there. But science isn’t that neutral.
WHERE DOES THAT LEAVE T? For those who long for a tidier ending—a pronouncement that T “really” does these things over here, and does not do those things over there—by now it should be obvious that no easy answers about T will be forthcoming. If we have achieved our aims here, we have exposed readers to new insights into T and also to questions about it, showing it to be something far more interesting and complex than its traditional biographies have revealed. But we also hope to have shaken up not simply thinking about the hormone itself, but how ideas about T are used in the world to gloss entrenched social inequalities and to punt social concerns back to biology.
As we wrote this conclusion, an image formed of T as Atlas, bearing not a world but a worldview on his back. T has been made to bear a lot of weight. We know T talk will endure, as will the casual substitution in daily conversation of “testosterone” for men or masculinity and the “sex hormone” concept in research, but we hope that we have opened a space for new ways of thinking about T that might emerge alongside these, maybe taking up more room and gaining momentum as T’s complexities are further elaborated. Instead of the titanic strength of Atlas, we hope we’ve suggested that T has other and better superpowers: a shape-shifting, moving, social molecule that serves as a dense transfer point for the micro-operations of biology and social relations of power at multiple levels.
Questions about biology and human nature are inextricable from moral and political debates about the value of human variations, the possibilities for equality, and the urgency and feasibility of social change. In some ways this book started with our prior work, but writing the book became urgent to us in the context of the regulation of women athletes’ testosterone levels. It was in specific moments of that project that the human consequences of how we think about T came into sharp relief. In the cases heard by the Court of Arbitration for Sport, the IAAF advanced a supposedly authoritative but profoundly narrow and distorted “science of T” that rested on a static, binary, “sex hormone” view of T. That view in turn was used to justify exclusions and interventions against specific people: bodily, psychic, economic, and social harms that are both profound and impossible to fully assess. International sports bodies have so far tenaciously held on to their determination to bend T to their exclusionary regulations, but we hold out hope that better thinking about T might yet make a difference in that arena and so many others.
They go completely overboard at the end. Harms that are profound? We are talking about excluding a 0.1% or whatever intersex or women with rare syndromes from women’s sports. Hardly a big deal, just a way to prevent cheating or mentally ill men from competing in women’s sports.
On the positive side: their chapter 2 is about ovulation and it’s fascinating. Their central story is that T actually has some utility in women’s reproductive system, by activating eggs before ovulation. This fact was apparently not discovered until recently because researchers thought it was an unlikely idea to begin with, T being all masculine and all. Their anecdote goes like this:
DWYN HARBEN WAS HAPPILY single, but she did want to bear a child, and at almost forty-three, she knew she was running out of time if she wanted to use her own eggs. Harben made an appointment to see Dr. Norbert Gleicher at the Center for Human Reproduction (CHR) in New York City. Gleicher, a celebrated figure in infertility research and treatment, had both admirers and critics for his eagerness to push the limits of fertility medicine, including assisting women to become pregnant at later and later ages, and openly assisting prospective parents to do sex selection.
Harben didn’t know whether she was fertile: she had never been pregnant, nor had she tried to be. She wasn’t ready to be a parent just yet, so they agreed that Gleicher would give her ovary-stimulating drugs, harvest the eggs, do in-vitro fertilization (IVF) with as many as possible, and bank the frozen embryos until she was ready to pursue the pregnancy. It’s a long and uncertain road between stimulating the ovaries and ending up with a viable pregnancy carried to term. The first step, stimulating the ovaries with hormones gauged to bring multiple eggs to maturity at once, is one of the toughest hurdles, because many women’s ovaries simply don’t respond to the stimulation by producing enough eggs to work with, especially as they get older. At first Harben found herself in this disappointing situation: in her words, she “flunked” her first cycle in 2003, producing only one egg in spite of receiving the maximum dose of stimulation drugs. At Harben’s age, no more than 10 percent of eggs would be expected to produce embryos capable of turning into a fetus, and there’s no way to tell which ones are viable without transferring them and seeing if a pregnancy is established and maintained. If her plan was going to work, she needed to produce more eggs.
Harben wasn’t the sort to leave everything in the hands of her doctor, especially when so much was on the line. “Before I blow $12,000 on another cycle,” she thought, “I better know whether there’s something on the near horizon that looks promising.” She hit the internet and came across two possible options for women who, like her, were designated as “poor responders” to ovarian stimulation. One report suggested that acupuncture might be helpful, and the other, a small study by doctors at Baylor University in Houston, Texas, suggested that treating women with dehydroepiandrosterone (DHEA), a weak androgen, before ovarian stimulation cycles might improve egg production. She began acupuncture treatment, and also began taking over-the-counter DHEA supplements. She didn’t tell Gleicher, because she thought he wouldn’t appreciate the fact that she was “messing with his protocol.”1
Meanwhile, Gleicher told her that continuing treatment would be “against medical advice.” He said Harben should instead come back when she was ready to get pregnant, and use eggs from a donor. Based on her own research, she understood that any ethical IVF doctor would have told her the same. But she wasn’t ready to give up. She convinced Gleicher that she understood the risks and insisted on proceeding, producing three eggs and five eggs in the next two cycles. Even though there had been a small increase each time, Gleicher advised Harben that a small increase or decrease wasn’t very meaningful within such a very small range. She told us, “I had to push him hard after each of the first three cycles to let me do the next one.” When in the fourth cycle Harben produced seven eggs, all of which again were successfully fertilized, the upward trend was unmistakable, and Gleicher slightly modified his stance on proceeding. She was thinking that she would “go in and do [her] confession” about her self-treatment with DHEA and acupuncture after the fifth cycle, but there was a “downward hiccup” in her egg production, so she waited. After the sixth cycle, in which she produced thirteen eggs, twelve of which developed into embryos, she prepared to tell him.
By that point, Gleicher told us, he had never seen anything like it. In direct contrast to the well-established pattern that women with low ovarian reserve will produce fewer eggs over time, or at best level off, Harben’s ovaries had produced more healthy eggs with each cycle. When Harben walked into his office and announced, “Dr. Gleicher, I have to tell you a secret,” he was ready to listen. He read the literature she’d brought, and while he wasn’t impressed with the reports on acupuncture, the DHEA study caught his attention. He said he pored over that article and was “terribly surprised.” “In our training,” he explained to us, “I think me, and the field generally, have mostly thought of androgens as bad for women who are trying to get pregnant. But generally accepted beliefs are not always correct.” Over the course of the next couple of years, through his own clinical research and his study of the animal literature, Gleicher began to suspect that the real star of this story wasn’t DHEA at all. It was testosterone.
It’s a cool story. Does it check out though? I mean, does this treatment actually work? There is a nice supportive review from 2015, which they cite. Even the abstract gives us a different focus of the reason for the difficulty though: “Deciphering the specific roles and precise pathways by which AR-mediated actions regulate ovarian function has been hindered by confusion on how to interpret results from pharmacological studies using androgens that can be converted into oestrogens, which exert actions via the oestrogen receptors.”. Biology is hard, not a problem of thinking of androgens being mainly related to men. If we read some of the reviews they cite (this one from 2011 by Gleicher), there are other, very sensible reasons why researchers did not just immediately try androgens for infertility — it is known to be related to a specific disorder that doctors understandably want to avoid:
Some animal data are relevant to a better understanding of PCOS in humans: For example, it has been known for some time that in animal models dehydroepiandrosteron (DHEA) can induce PCOS phenotypes in previously normal ovaries [45, 46]. In humans we demonstrated the same only more recently, when long-term DHEA supplementation, in women with even very severe DOR was shown to result in typical PCOS-like ovaries [47] (for further detail, see below).
Anyway, so does it work? There is a meta-analysis of 9 studies from 2019, too new for the authors to have cited it. The funnel plot looks like this, for number of eggs harvested:
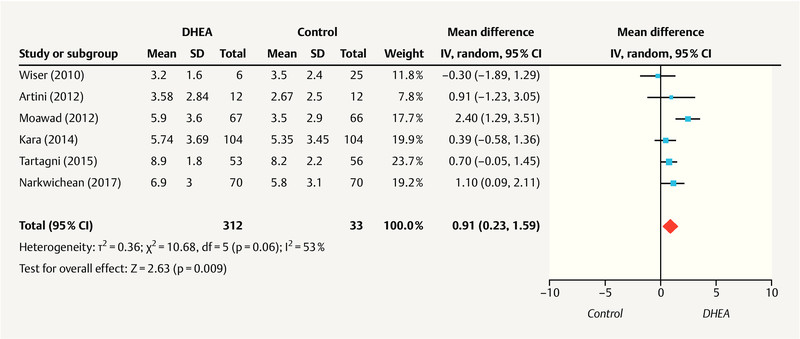
So it’s not totally convincing. The largest effect is seen in a study from Moawad (2012). Turns out this is published in Middle East Fertility Society Journal. So maybe it is just fake, these countries often produce fake research. There is a cautionary review about these studies. This review mentions there is an on-going phase 3 RCT, n=400, to check this treatment. When that arrives, we will have a better answer.
Finally, the conclusion is typically schizophrenic:
The story of ovulation shows that the trouble with T isn’t just cultural. The case of T’s role in ovulation, and how slowly the knowledge of that process is created and disseminated, is an important example of how T’s social identity is consequential to what we know about T in the most formal, material, scientific sense. The recent studies on ovulation have the potential to upend a century of understandings about what testosterone and its fellow androgens do. Indeed, playing a central role in ovulation undermines their very classification as androgens. And that’s one of our main reasons for going into the details of these studies: it’s a great case study for examining why it’s so hard to learn new things about T.
No, the fact that T has some functions in women is not surprising, and does not mean it is not an androgen. The status as androgen obviously has to do with its central role in masculinization of the fetus and the much higher concentration in men than women. This is all very obvious, only an obtuse person would contest it.
Non-woke
Now it would be nice if I had a similar long discussion of parts in Hooven’s book, but I don’t. The file has disappeared from all my devices, and with it, my highlighted passages. Hooven’s book is less easy to fact check because she does not provide footnotes to specific claims. For instance, take this anecdote and claim:
On July 17, 1994, at the Rose Bowl in Pasadena, California, Italy and Brazil squared off in the final game of soccer’s World Cup, the world’s biggest sporting event. This gave some behavioral endocrinologists from Georgia State University an idea.
Prior to the game, equipped with test tubes and participation forms, they went out on the town, found a crew of Italian male fans in a pizzeria and a crew of Brazilian male fans in a bar, and in both cases got some of them to produce saliva samples before and after the game. It was all part of a simple experiment to determine T levels.
After ninety minutes, neither side had scored. This was soccer, after all. Extra time brought no goals, either, so the game went to a heart-in-the-mouth penalty shootout. The world held its breath, and players from each side took shots on goal, one by one.
And who won? The researchers could have figured it out just by consulting the testosterone levels in the men’s spit samples. Levels of the Brazilian fans stayed about the same or increased at the end of the game, and they dropped for the Italians. Brazil wins! Many studies have found similar results, in which T rises prior to a competition in both the eventual winners and losers, but T remains elevated for longer in the winners than the losers. These kinds of T responses have been demonstrated even in men who compete in unathletic events like chess and video games. While this effect occurs regularly in humans and nonhuman animals, it’s variable. Many factors affect how T responds to competition, including the circumstances of the experiment (like whether the competition is orchestrated in the lab or in the “real world”), how much someone cares about winning, and levels of other hormones.
If one reads through the notes, however, one will find the right kind of studies cited:
this might simply be a by-product of the adrenals responding to stress: Some researchers are concerned that women are largely left out of these studies, and they are right that there are far more that examine this effect in men. Some of this apparent neglect is likely because previous attempts to find the “winner-loser” effect in women have mostly failed. Research on women’s T is complicated, partly because of previously discussed difficulties in measuring women’s T, and women’s T levels change as a function of menstrual cycles and birth control status, so these must be taken into account; and researchers want to obtain positive results so they can get their studies published. (I’m not endorsing leaving women out, but there are understandable reasons for their reduced inclusion.)
Of the studies on the winner-loser effect that include women: Shawn N. Geniole, Brian M. Bird, Erika L. Ruddick, and Justin M. Carré, “Effects of Competition Outcome on Testosterone Concentrations in Humans: An Updated Meta-Analysis,” Hormones and Behavior 92 (2017): 37–50; and K. V. Casto, D. A. Edwards, M. Akinola, C. Davis, and P. H. Mehta, “Testosterone Reactivity to Competition and Competitive Endurance in Men and Women,” Hormones and Behavior 123 (2020): 104655.
The evidence in the meta-analysis is not entirely convincing, but the more realistic studies of real world competitions (opposed to semi-fake ones in the lab) did find a sizable effect (d = 0.43).
Later she cites some CAG study. It’s the dangerzone, we know these kind of studies are ultra p-hacked. In this case, she says:
But that was not all. The researchers didn’t just look at personality—they also looked at genes, specifically, the androgen receptor gene. Remember my student Jenny from chapter 3? Her androgen receptor gene contained a mutation that put her androgen receptor out of business. In partial androgen sensitivity syndrome, the receptor works, but it is not as responsive to androgens as a fully functioning receptor. So it’s not all about T level: the effectiveness of the androgen receptor matters, too. The same point holds for ability of the T-bound androgen receptor to control the rate of protein production from its “target genes,” like those that promote beards, muscle, or aggression. As it turns out, even among the typical, fully functional androgen receptors, some are really efficient at controlling transcription from target genes and cause more proteins to be produced, and some are less so.
The researchers wanted to see if a given amount of T would preferentially increase aggression in men with relatively efficient androgen receptors, so they collected (used) mouthwash from the men in the experiment, from which they harvested their DNA.
The span of DNA that comprises each androgen receptor gene has something in it called a “CAG repeat,” which is a segment of C+A+G “letters” that repeats—from eight to thirty-seven times. Fewer repeats means the receptor is more efficient, and more repeats means it’s less so. All else being equal, the people who should have the greatest response to a given amount of T are those who have the lowest number of CAG repeats in their androgen receptor gene.
The length of one’s CAG repeat turns out to be associated with all sorts of things, such as the probability of getting prostate cancer (more likely with fewer repeats), pregnancy outcomes (spontaneous abortions are more likely with fewer repeats), and even one’s ethnic background.
And now we know one more thing that the CAG repeat predicts—aggression in response to testosterone. Among the men who were dominance oriented and impulsive, those who had a short CAG repeat, and thus a higher sensitivity to T, responded with more aggression (they stole more points) to the T gel.
Furthermore, the men with shorter CAG repeats reported that they got more pleasure from being aggressive! This finding provides some insight into how T might encourage aggression in men. Elevations in T provide incentives, because T increases sensitivity to reward. For example, when mice are given a choice of which side of a cage to hang out in, they will choose the side in which they previously received a nice dose of testosterone. The parts of the brain that are rich in the neurotransmitter dopamine, and which influence motivation, are dense with androgen receptors. We tend to get a rush of dopamine when we do something adaptive (or that was adaptive in our evolutionary past), like eating something sweet, having sex, or intimidating a competitor. The dopamine helps reinforce that behavior: since it feels good, we are motivated to do it again. And animal studies show that T actually increases the amount of dopamine that is released in response to winning, in addition to increasing the number of its own receptors in the reward centers of the brain! All of these changes appear to make it more likely that winning animals will be more likely to confront future threats.
To sum up the lessons from this study: increasing levels of T appear to be motivating and rewarding in some men in the right circumstances, with the right personality, and the right kind of androgen receptor gene. That all these factors matter is not evidence that the relationship between T and aggression is weak; rather, it shows us that it’s complicated, as is the research that looks into how the relationship works.
So what is the study? It’s this 2019 study. On the surface it looks good: n=308 men, multiple measures of T, before and after etc. But then you look at the stats and they are all totally wonky:
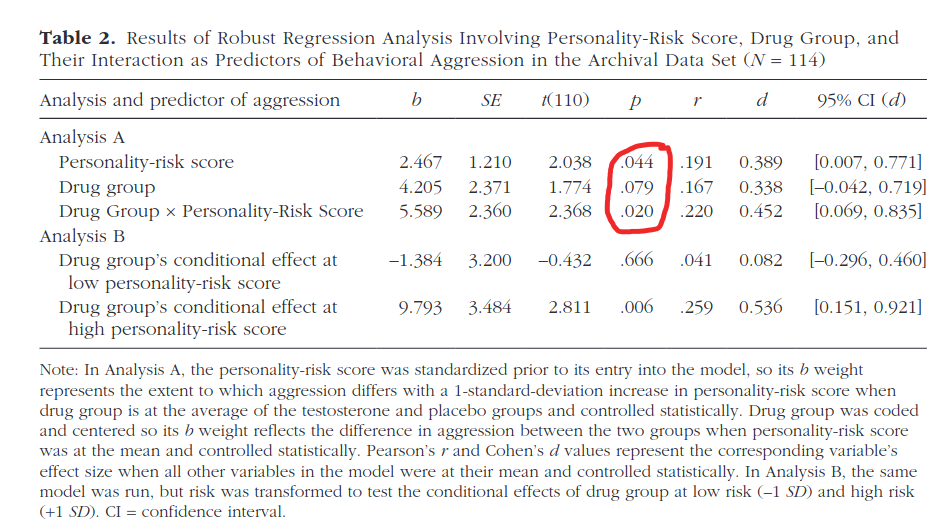
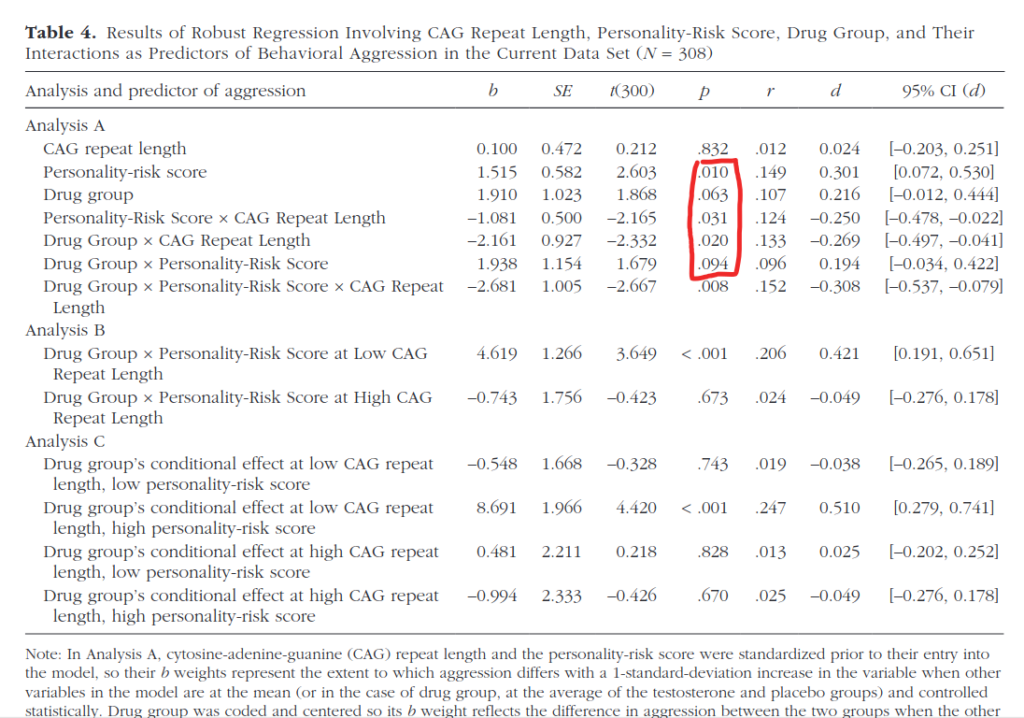
There are 2 tables because the authors had 2 datasets: one smaller archival dataset, and one new larger one. Nevertheless, they managed to produce a ton of p values in the .01 to .10 zone, indicating cheating. So I suggest ignoring this study despite its other virtues. A pity!
In general, Hooven did not make outrageous enough claims that I spent time combing through the notes to find the studies (without footnotes it takes some scrolling) and check up on them. But based on the pattern here, her studies are more modern and more meta-analysisy than the ones cited by the woke team. It seems the woke team decided on which studies to cite by looking at which are cited the most. This of course favors old studies — the ‘citation classics’ — which are more dubious, compared to modern ones and meta-analyses. Their approach has historical value, but it is not useful to evaluate the strength of evidence for some claim as it is now. By way of simple comparison: Hooven cites 13 meta-analyses in her notes, whereas the woke team cites 5.
All in all, I would recommend the Hooven book as it provides a useful review of findings in a sensible overall, scientific narrative. The woke book by Rebecca M. Jordan-Young, and Katrina Karkazis cannot really be recommended unless you are interested in obfuscation. Because of their political bias, one has to check everything they say, which makes for a painful reading experience.


{kind=link}