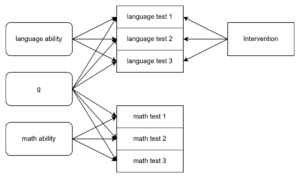
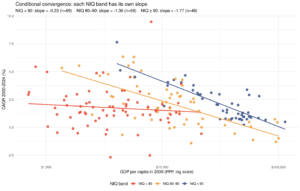
Many people are aware that American universities practice something called affirmative action. Really, this just means a kind of reverse racism that was instituted during the 1960s cultural takeover (or glorious revolution, depending on your view). It consists of providing easier access to universities, and sometimes jobs, based on your sex and race. Easier as in providing more slots to people who don’t objectively meet the admission criteria. I’ve written about how it was intended as a temporary policy until Blacks (and others) had caught up. Clearly, many people thought they would quickly catch up based on the theory that Black deficits relative to White (European) norms were due to Jim Crow, legacy of slavery, low school funding, racist teachers, and so on. In 1976, one Black judge swore to end it up in 25 years, and it’s been about 45 years. You are maybe tempted to dismiss this as whatever, but then again, in 2003, a US supreme court judge made the same claim that in 25 years we won’t need it anymore. Well, there are still 7 years left I guess. Despite claims to the contrary (mainly based on the meta-analysis by Flynn and Dickens from 2006), recent large representative samples don’t show any narrowing in intelligence. The PNC dataset shows 1.05 d gap in g from SEM, and 14.7 IQ gap if one uses the standard full scores. The ABCD dataset shows 1.08 d gap for the total factor scores. The WAIS-4 standardization sample shows a 1.16 d gap in g scores from SEM. These are all large samples of thousands of Blacks, kids as well as adults. If progress was just around the corner, was Flynn and Dickens thought, clearly these gaps should have been smaller, especially for the children. But the data are stubborn in their denial of this.
Anyway, so let’s return to affirmative action. The various people who get discriminated against — meaning men, Whites and Asians — tend to be unhappy about this, and sue the universities. So we get a steady stream of lawsuits about race discrimination. The universities know their policies are unpopular among voters (when you explain it!), so they tend to hide the data. Because of the lawsuits, however, sometimes data get released. One particular clear table has been making the rounds this last year. The AEI blogged it about it in the summer, but seemingly without knowing the exact source. One can also find other sites with it.
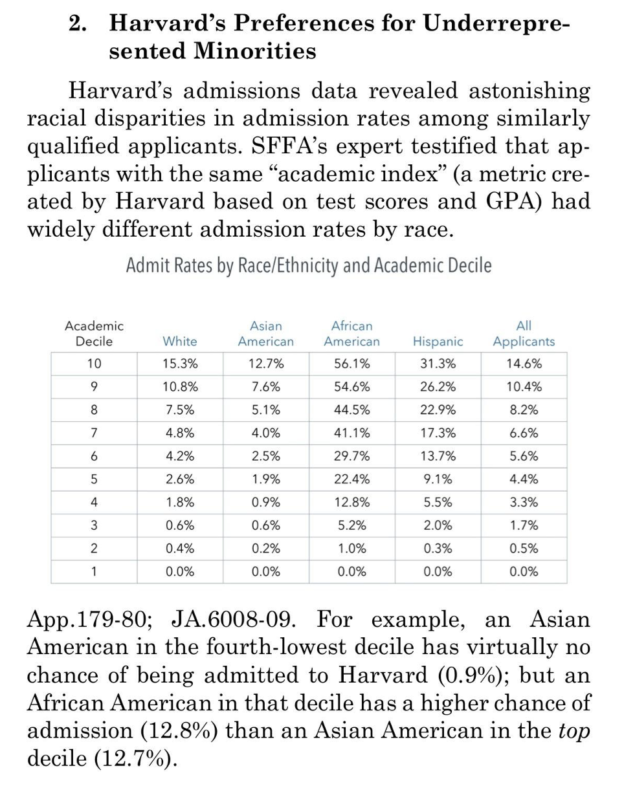
- Source: PETITION FOR WRIT OF CERTORARI, filed by FAIR (STUDENTS FOR FAIR ADMISSIONS, INC.) original URL, mirror
We see from the table that getting into Harvard is mostly about being in the academic 10th decile, meaning top 10%. The numbers in each cell show the chance of getting admitted conditional on being in that decile group and that race (by column). So the top 10% Whites have 15.3% chance of making it, while for Blacks this number is 56.1%. In other words, if we crudely hold constant their academic ability measured by test scores and GPA (and whatever), then we find about that Blacks have about 267% better chance of getting admitted. I say crudely because the use of the deciles actually under-adjusts a bit because relatively more persons will be in the lower 90%s centiles within the decile groups than for the higher scoring groups. This bias is probably slight. There is also probably no adjustment for random measurement error, which means that measurement error is giving the benefit of the doubt to the persons from the lower scoring groups. This effect is probably also slight considering the high reliability of the tests (but maybe not GPA). While these numbers may be shocking to some naive readers, they are not new at all. The Bell Curve reported various related numbers, and the AEI itself blogged about some similar numbers for medical school back in 2017, and those numbers were from 2013. I blogged about the implications of such admissions bias before (TL;DR: it kills).
Finding the exact source
You can skip this if you don’t care about how-to internet search.
A friend asked me to track down the exact source of this table. It was more difficult than imagined. Searching for some text fragments did find a PDF but it was seemingly not the right file. Searching the file itself did not find the text fragment. Strange! It turns out the explanation is that Google does its own OCR (recognizing text from images) of PDF files, and the results of that is used for the search. However, when you download the PDF and search it, you are using the embedded text, which may differ. In this case, it does differ because it contains a lot of obscuring whitespace that result in the search coming up empty. For those very curious, it looks like this:
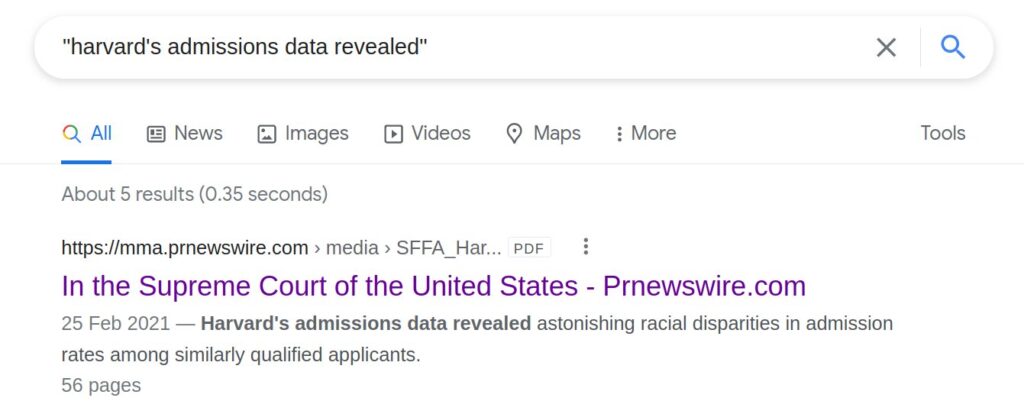
But not in the file:
![]()
Copying the text from both sources for comparison:
So on a technical note, it would be nice if PDF software would enhance their dealings with whitespace. The simple way here is to treat a space in a search as reflecting the Regex search “\s+” which means any positive number of whitespaces, including spaces, tabs and whatever.